
What is Random Forest
Random forest is a supervised machine learning algorithm used to solve classification as well as regression problems. It is a type of ensemble learning technique in which multiple decision trees are created from the training dataset and the majority output from them is considered as the final output.
Random forest is a very popular technique due to its simplicity and ability to produce robust results.
How Random Forest Works
Random Forest works on the Bootstrap Aggregation (Bagging) technique of Ensemble learning –
i) Here, first of all, multiple training data is created by sampling data from the training set which is known as bootstrapping or bagging.
For example, if we have a data set (a,b,c,d,e,f,g,h,i,j) then the following training set can be obtained with bootstrap –
(a,f,d,j,h,c) (b,g,a,i,c,f) (i,d,c,e,a,d) (b,h,g,h,a,b)
You may notice here that the same data can appear multiple times across the training sets because we are doing random sampling with replacement.
ii) The leftover training data that has not been added in the bootstrapped data can be used to find the random forest accuracy. This is called the out-of-bag-datasets.
iii) Next, multiple decision trees are trained on each of these datasets. Instead of taking all features, we can add more variation by randomly selecting some features of the dataset for each of the decision trees.
iv) The output of each decision tree is aggregated to produce the final output. For classification, the aggregation is done by choosing the majority vote from the decision trees for classification. In the case of regression, the aggregation can be done by averaging the outputs from all the decision trees.
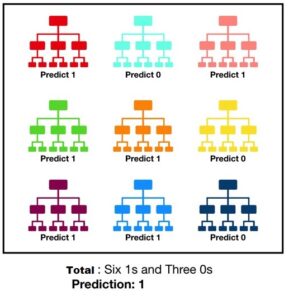
e.g. if 9 decision trees are created for the random forest classifier, and 6 of them classify the outputs as class 1 and the remaining 3 classify output as class 0, then the final classification will be chosen as class 1, based on the maximum vote it got.
Advantages of Random Forest
Some of the advantages of random forest are listed below.
- Random forests have much higher accuracy than the single decision tree.
- It has low bias and low variance.
- Can be used for both classification and regression.
- Handel missing values very well and gives a good accuracy on missing values dataset.
- Due to its randomness doesn’t overfit the model, thus gives a good prediction on unseen datasets.
- Large datasets having high dimensionality can be handled using random forest.
Disadvantages of Radom Forest
There are several disadvantages of using a random forest. Some of them are listed below.
- The random forest needs good computational resources to train them efficiently.
- At times random forest regression fails to produce accurate results.
- It behaves like a black box where we don’t have much control over the output it produces as it lacks interpretability.
Random Forest vs Decision Tree

- The traditional decision tree algorithm has a high variance that may result in overfitting. Random forest on the other hand has low variance which means it does not overfit as much.
- Compared to the decision tree, the random forest results are difficult to interpret which is a kind of drawback.
- Since in random forest multiple decision trees are trained, it may consume more time and computation compared to the single decision tree.
Random Forest Classifier in Sklearn
We can easily create a random forest classifier in sklearn with the help of RandomForestClassifier() function of sklearn.ensemble module.
Random Forest Hyperparameters (Sklearn)
Hyperparameters are used to tune in the model to increase its predictive power or to make it run faster. Some of the import hyperparameters of Random Forest in sklearn implementation of RandomForestClassifier() are :
- n_estimators: It takes an integer value which represents the number of decision trees the algorithm builds. In general, a higher number of trees increases the performance and makes the predictions more stable, but it also slows down the computation. The default value of this parameter is 100.
- criterion: This is a tree-specific parameter. It takes either “Gini” or “entropy”. By default, it is “Gini”. It represents the quality of a split of the decision trees. Where “gini” is for the Gini impurity splitting method and entropy” for the information gain splitting method.
- max_features: It provides the maximum number of features to consider when looking for the best split. It takes either of {“auto”, “sqrt”, “log2”}, integer or float value. By default, it is “auto”
- n_features: It takes an integer value. It represents the number of features when the fit is performed.
- oob_score: It takes a boolean value. By default it is False. It decides whether to use out-of-bag samples to estimate the generalization accuracy.
- min_sample_leaf: It takes an integer or a floating value. By default, it is 1. This determines the minimum number of samples required to be at a leaf node. A split point at any depth will only be considered if its leaves are less than
min_samples_leaf. If it is an integer, then it considers as the minimum number. Else it considers as a fraction and is the minimum number of samples for each node. - n_jobs: It takes an integer value. By default it is none. It represents how many processors it is allowed to use. If it has a value of one, it can only use one processor. A value of “-1” means that using all processors available.
- random_state: The model will always produce the same results when it has a definite value of random_state and if it has been given the same hyperparameters and the same training data. For further reading refer to the documentation.
Example of Random Forest Classifier in Sklearn
About Dataset
In this example, we will use a Balance-Scale dataset to create a random forest classifier in Sklearn. The data can be downloaded from UCI or you can use this link to download it.
The goal of this problem is to predict whether the balance scale will tilt to left or right based on the weights on the two sides. It has 625 records and has 5 attributes as below –
- Class Name
- Left weight
- Left distance
- Right weight
- Right distance
Importing libraries
We start with initial libraries such as NumPy, pandas, seaborn, and matplotlib.pyplot. We will import more libraries as we move forward.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
Importing Dataset
Next, we import the dataset from the CSV file to the Pandas dataframes.
col = [ 'Class Name','Left weight','Left distance','Right weight','Right distance']
df = pd.read_csv('balance-scale.data',names=col,sep=',')
df.head()
Splitting the Dataset in Train-Test
We first split the dataset into train and test data using the train_test_split function.
from sklearn.model_selection import train_test_split
X = df.drop('Class Name',axis=1)
y = df[['Class Name']]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3)
Training the Random Forest Classifier
For training the random forest classifier we have used sklearn RandomForestClassifier to make a classifier model. We are keeping most of its parameters as default and then pass our training data to fit.
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier(criterion='entropy')
rf_clf.fit(X_train,y_train)
Test Accuracy
To check the accuracy we first make predictions on test data by using model.predict function and passing X_test as attributes.
y_predict = rf_clf.predict(X_test)
We can see that we are getting a pretty good accuracy of 82.4% on our test data.
from sklearn.metrics import accuracy_score,classification_report,confusion_matrix
accuracy_score(y_test,y_predict)
In our earlier article we had used the same data to create a decision tree and the accuracy was only 70%. So we can clearly see the accuracy has increased with random forest here.

