
Introduction
Any computer vision enthusiast has surely heard of YOLO models for object detection. Ever since the first YOLOv1 was introduced in 2015, it garnered too much popularity within the computer vision community. Subsequently, multiple versions of YOLOv2, YOLOv3, YOLOv4, and YOLOv5 have been released albeit by different people. In this article, we will give a brief background about all the object detection models of the YOLO family from YOLOv1 to YOLOv5.
Basic Working of YOLO Object Detector Models
As for every ML-based model precision and recall are very important to deduce and judge its accuracy and robustness. Thus the creator of YOLO kept tried to come up with the object detection model that maximizes mAP (mean average precision).
- Recall is the ratio of true positives to total positive prediction(correct or incorrect).
- Precision is the ratio of true positives to the ground truth positives(total correct predictions).
- The mean of all average precision is called mean average precisions(mAP).
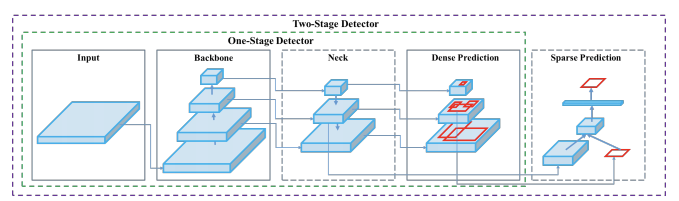
Besides this, the architecture of all the YOLO models have a similar theme of components as outlined below –
- Backbone: A convolutional neural network that accumulates and produces visual features with different shapes and sizes. Classification models like ResNet, VGG, and EfficientNet are used as feature extractors.
- Neck: A set of layers that integrate and blend characteristics before passing them on to the prediction layer. Example: Feature pyramid network(FPN), path aggregation network(PAN) and Bi-FPN
- Head: Takes in features from the neck along with the bounding box predictions. Performs classification along with regression on the features and bounding box coordinates to complete the detection process. Outputs 4 values, generally x,y coordinate along with width and height.
YOLOv1 – The Beginning
The first YOLO model was introduced by Joseph Redmon et all in their 2015 paper titled “You Only Look Once: Unified, Real-Time Object Detection”. Till that time RCNN models were the most sought-after models for object detection. Although the RCNN family of models were accurate but were relatively slow because it was a multi-step process of finding the proposed region for the bounding box and then do classification on these regions and finally do post-processing to refine the output.
YOLO was created with the goal to do away with multistage and perform object detection in just a single stage, thus increasing the inference time.
Performance
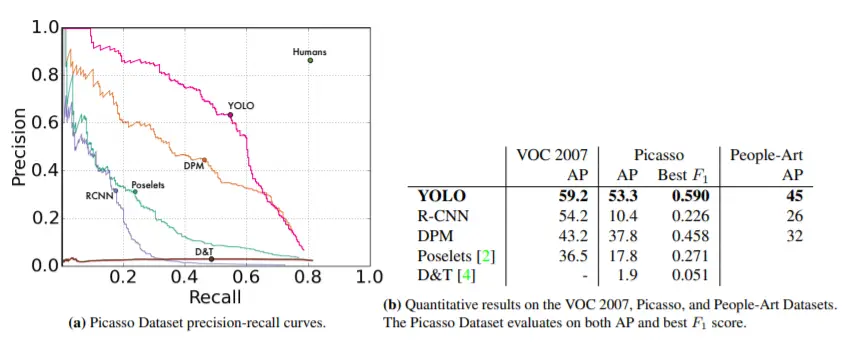
YOLOv1 sported a 63.4 mAP with an inference speed of 45 frames per second (22ms per image). At that time, it was a huge improvement of speed over the RCNN family for which inference rates ranged from 143ms to 20 seconds.
Technical Improvements
The basic working of the YOLO model relies upon its unified detection technique which groups together different components of object detection into a single feed neural network.
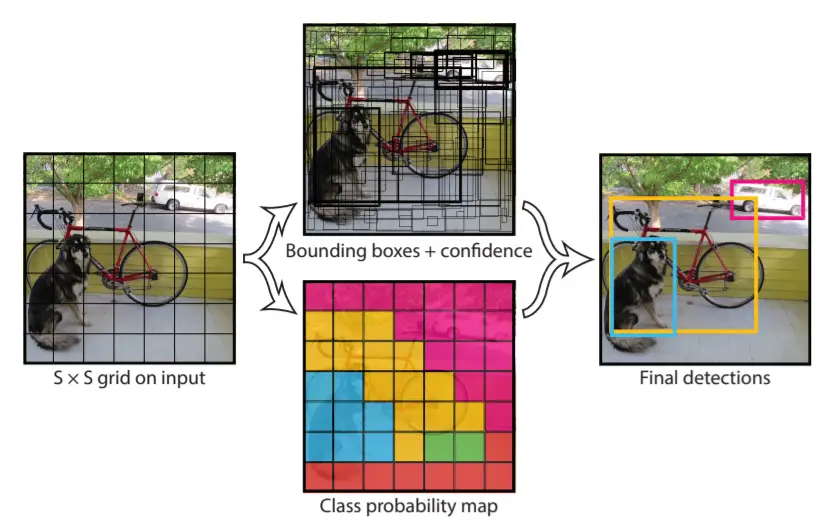
The model divides an incoming image into numerous grids and calculates the probability of an object resides inside that grid. This is done for all the grids that the image is divided into. After that, the algorithm groups nearby high-value probability grids as a single object. Low-value predictions are discarded using a technique called Non-Max Suppression(NMS).
The model is trained in a similar fashion where the center of each object detected is compared with the ground truth. In order to check whether the model is correct or not and adjust the weights accordingly.
YOLOv2 – Better, Faster, Stronger
YOLOv2 was released by Joseph Redmon and Ali Farhadi in 2016 in their paper titled “YOLO9000:Better, Faster, Stronger”. The 9000 signified that YOLOv2 was able to detect over 9000 categories of objects. This version had various improvements over the previous version YOLOV1.
Performance
YOLOv2 registered 78.6 mAP on the VOC 2012 dataset. We can see in the below table that it performed very well on the VOC 2012 dataset compared to other object detection models.

Technical Improvements
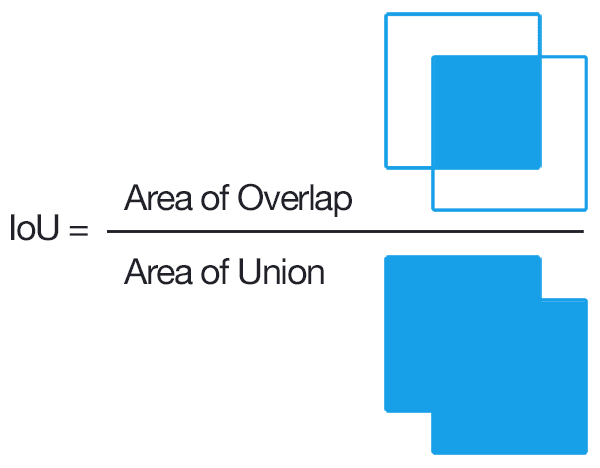
YOLOv2 version introduced the concept of anchor boxes. Anchor boxes are nothing but predefined areas for an image that illustrates the idealized position of the objects to be detected. We calculate the ratio of overlap over union (IoU) of the predicted bounding box and the pre-defined anchor box. The IoU value acts as a threshold to decide whether the probability of the detected object is sufficient to make a prediction or not.
But in the case of YOLO, anchor boxes are not computed randomly. Instead, the YOLO algorithm examines the training data and performs clustering on it (dimension clusters). All this is done in order to ensure that the anchor boxes that are used represent the data on which we will be training our model. This helps in enhancing the accuracy a lot.
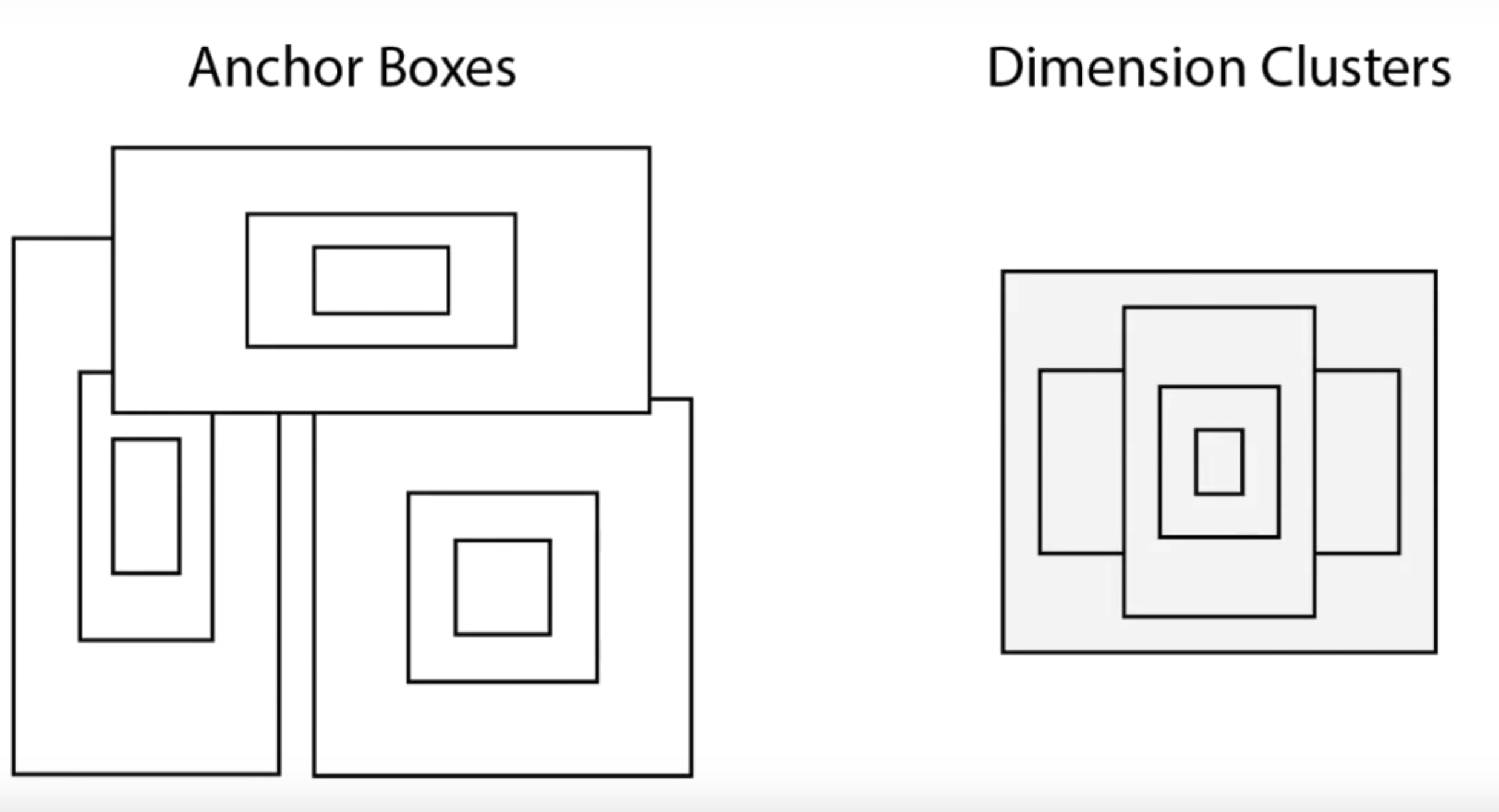
Additional Improvements
- In order to adapt to different aspect ratios, the YOLOv2 model is randomly resized throughout the training process (this is called multi-scale training).
- For the model to be robust the YOLOv2 model was trained on a combination of the COCO dataset (80 classes with bounding boxes) and the ImageNet dataset (22k classes without bounding boxes). When the model processes an image with labels the detection and classification error is calculated. Whereas when the model sees a label-less image it backpropagates the classification error only. This structure is called the WordTree.
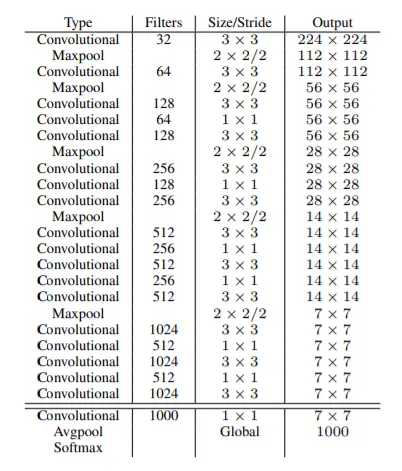
- Inference speeds of up to 200 FPS and mAP of 75.3 were achieved using a classification network architecture called darknet19 (the backbone of YOLO).
YOLOv3: An Incremental Improvement
In 2018, Joseph Redmon and Ali Farhadi introduced the third version of YOLOv3 in their paper “YOLOv3: An Incremental Improvement”. This model was a little bigger than the earlier ones but more accurate and yet was fast enough.
Performance
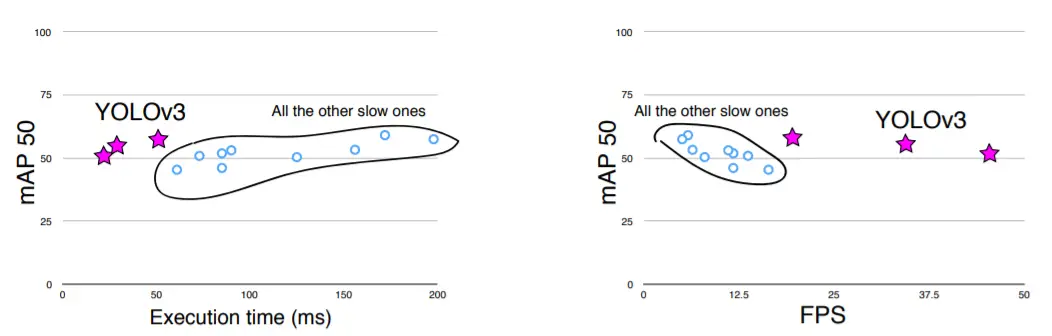
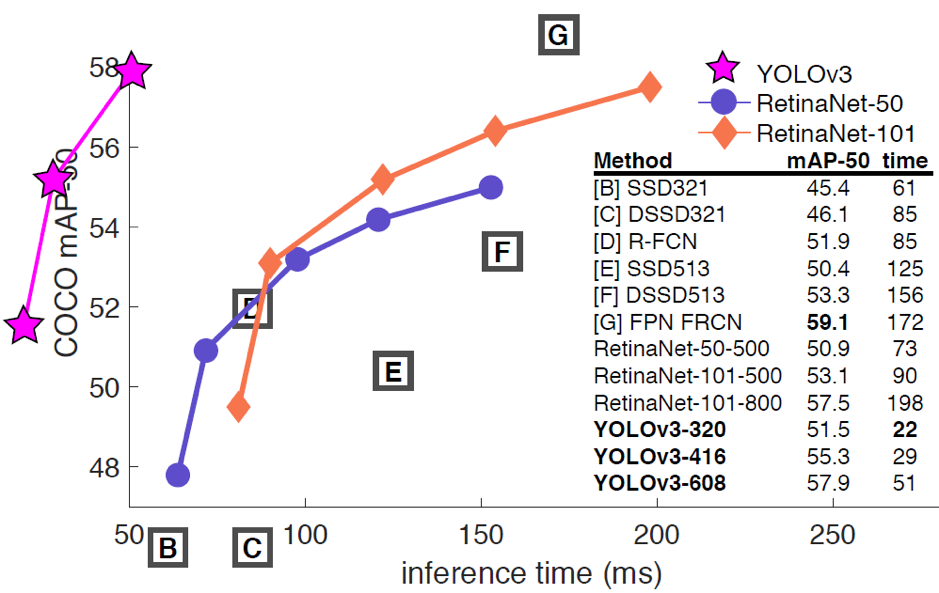
YOLOv3-320 has an mAP of 28.2 with an inference time of 22 milliseconds. (On the COCO dataset). This is 3 times fast than the SSD object detection technique yet with similar accuracy.
Technical Improvements
YOLOv3 consisted of 75 convolutional layers without using fully connected or pooling layers which greatly reduced the model size and weight. It provided the best of both worlds i.e. using residual models (from the ResNet model) for multiple feature learning with feature pyramid network(FPN) while maintaining minimal inference times.
- A feature pyramid network is a feature extractor that extracts different types/forms/sizes of features for a single image. It concatenates all the features so that the model can learn local and general features.
- By employing the use of logistic classifiers and activations the class predictions for the YOLOv3 goes above and beyond RetinaNet-50 and 101 in terms of accuracy.
- As the backbone, the YOLOv3 model uses the Darknet53 architecture.
YOLOv4 – Optimal Speed and Accuracy of Object Detection
YOLOV4 was not released by Joseph Redmon but by Alexey Bochkovskiy, et all in their 2020 paper “YOLOv4: Optimal Speed and Accuracy of Object Detection”.
Performance
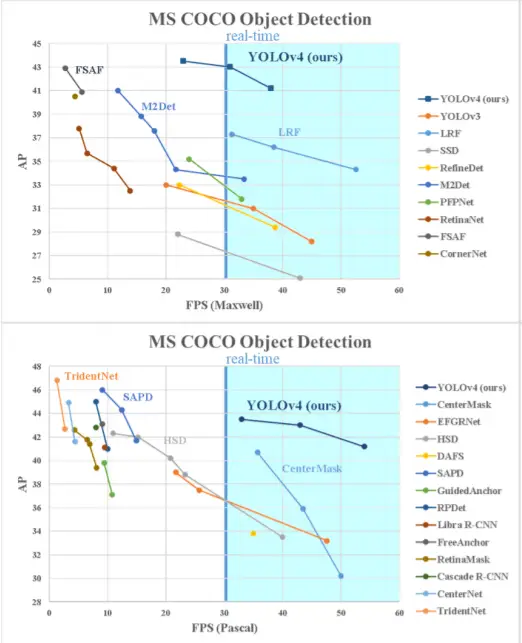
YOLOv4 model stands atop of the other detection models like efficientDet and ResNext50. It has the Darknet53 backbone (same as the YOLOv3).
Technical Improvements
YOLOv4 introduced the concept of the bag of freebies (techniques that bring about an enhancement in model performance without increasing the inference cost) and the bag of specials (techniques that increase accuracy while increasing the computation cost).
It has a speed of 62 frames per second with an mAP of 43.5 percent on the COCO dataset.
Bag of Freebies (BOF)
- Data augmentation techniques: Cutmix (Cut and mix multiple images containing objects that we want to detect), Mixup(Random mixing of images), Cutout, Mosaic data augmentation.
- Bounding box regression loss: Experimentation of different types of bounding box regression types. Example: MSE, IoU, CIoU, DIoU.
- Regularization: Different types of regularization techniques like Dropout, DropPath, Spatial dropout, DropBlock.
- Normalization: Introduced the cross mini-batch normalization which has proven to increase accuracy. Along with techniques like Iteration-batch normalization and GPU normalization.
Bag of Specials BOS
- Spatial attention modules (SAM): Generates feature maps by utilizing the inter-spacial feature relationship. Help in increasing accuracy but increase the training times.
- Non-max suppression(NMS): In the case of objects that are grouped together we get multiple bounding boxes as predictions. Non-max suppression reduces false/excess boxes.
- Non-linear activation functions: Different types of activation functions were tested with the YOLOv4 model. Example ReLU, SELU, Leaky, Swish, Mish.
- Skip-Connections like weighted residual connections(WRC) or cross-stage partial connections(CSP).
YOLOv5: Latest YOLO?
YOLOv5 is supposedly the next member of the YOLO family released in 2020 by the company Ultranytics just a few days after YOLOv4. No paper has been released and there is a debate in the community if it justifies using YOLO branding as it is just the PyTorch implementation of YOLOv3.
- Also Read – Introduction to YOLOv5 Object Detection with Tutorial
- Also Read – Tutorial – YOLOv5 Custom Object Detection in Colab
Performance
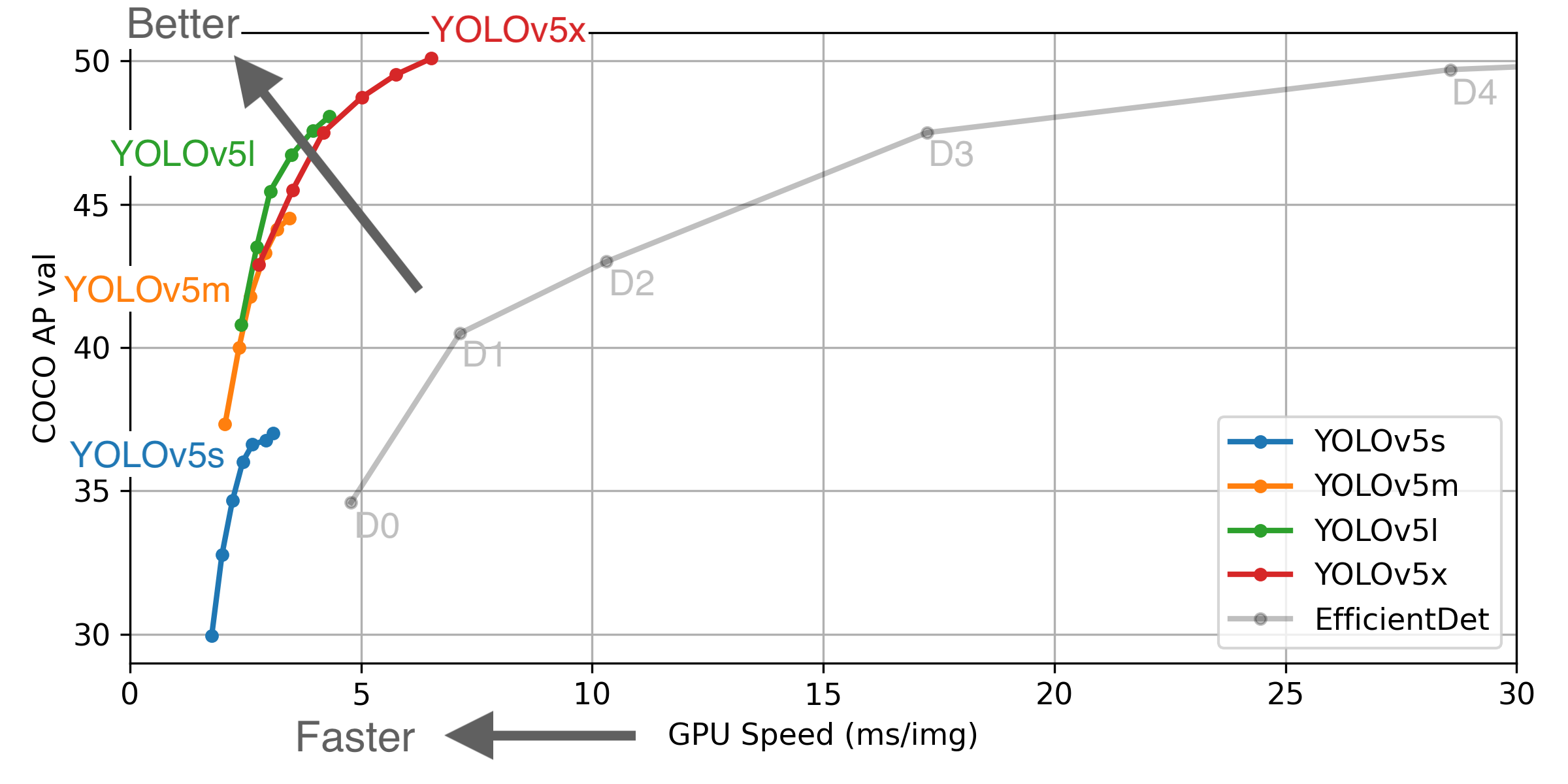
The authenticity of performance cannot be guaranteed as there is no official paper yet. It achieves the same if not better accuracy(mAP of 55.6) than the other YOLO models while taking less computation power.
Technical Improvements
- Better data augmentation and loss calculations (Now that the base of the model has shifted from C to PyTorch)
- Auto learning of anchor boxes (they do not need to be added manually now)
- Use of cross-stage partial connections(CSP) in the backbone.
- Use of path aggregation(PAN) network in the neck of the model
- Easier framework to train and test(PyTorch).
- Ease of use and installation.
- Instead of CFG files, the new version supports YAML files which greatly enhances the layout and readability of model configuration files.


