
Introduction
In this article, we will go through the tutorial of YOLOv5 for object detection which is supposed to be the latest model of the YOLO family. We will understand what is YOLOv5 and do a high-level comparison between YOLOv4 vs YOLOv5. Finally, we will show you how to use YOLOv5 for object detection on various images and videos.
(But please note that the inclusion of YOLOv5 in the YOLO family is a matter of debate in the community, and neither its paper has been released officially for peer review. So its architectural and performance details mentioned here, as collected from the various sources have to be taken with a pinch of salt.)
What is YOLOv5?
i) History and Controversy
YOLO stands for You Look Only Once and it is one of the finest family of object detection models with state-of-the-art performances.
Its first model was released in 2016 by Joseph Redmon who went on to publish YOLOv2 (2017) and YOLOv3 (2018). In 2020 Joseph Redmon stepped out from the project citing ethical issues in the computer vision field and his work was further improved by Alexey Bochkovskiy who produced YOLOv4 in 2020.
YOLOv5 is the next controversial member of the YOLO family released in 2020 by the company Ultranytics just a few days after YOLOv4.
ii) Where is YOLOv5 Paper?
YOLOv5 is controversial due to the fact that no paper has been published yet (till the time of writing this) by its author Glenn Jocher for the community to peer review its benchmark. Neither it is seen to have implemented any novel techniques to claim itself as the next version of YOLO. Instead, it is considered as the PyTorch extension of YOLOv3 and a marketing strategy by Ultranytics to ride on the popularity of the YOLO family of object detection models.
But one should note that when YOLOv3 was created, Glenn Jocher (creator of YOLOv5) contributed to it by providing the implementation of mosaic data augmentation and genetic algorithm.
iii) Is YOLOv5 Good or Bad?
Certainly, the controversy behind YOLOv5 is just due to its choice of name, but it does not take away the fact that this is after all a great YOLO object detection model ported on PyTorch.
Probably if you are just a developer, you would not even care about the controversy and may enjoy working with YOLOv5 due to its ease of use. (As we will see in the examples of this tutorial)
YOLOv5 Architecture
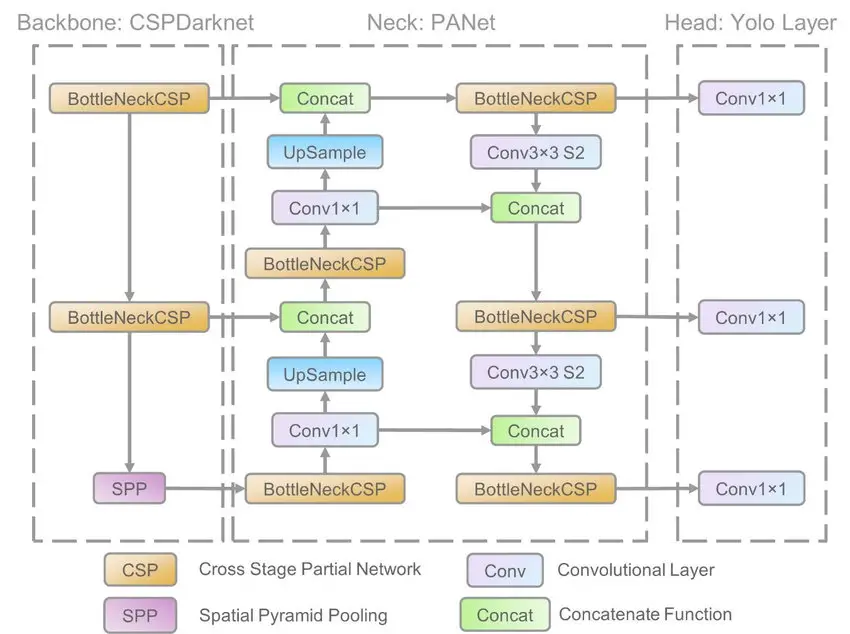
The YOLO family of models consists of three main architectural blocks i) Backbone, ii) Neck and iii) Head.
- YOLOv5 Backbone: It employs CSPDarknet as the backbone for feature extraction from images consisting of cross-stage partial networks.
- YOLOv5 Neck: It uses PANet to generate a feature pyramids network to perform aggregation on the features and pass it to Head for prediction.
- YOLOv5 Head: Layers that generate predictions from the anchor boxes for object detection.
Apart from this YOLOv5 uses the below choices for training –
- Activation and Optimization: YOLOv5 uses leaky ReLU and sigmoid activation, and SGD and ADAM as optimizer options.
- Loss Function: It uses Binary cross-entropy with logits loss.
Different Types of YOLOv5

YOLOv5 has multiple varieties of pre-trained models as we can see above. The difference between them is the trade-off between the size of the model and inference time. The lightweight model version YOLOv5s is just 14MB but not very accurate. On the other side of the spectrum, we have YOLOv5x whose size is 168MB but is the most accurate version of its family.
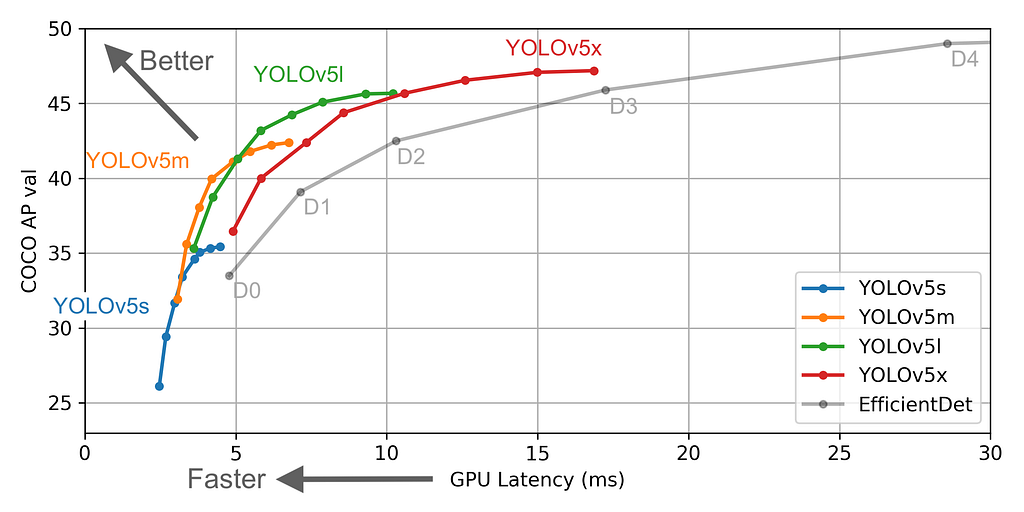
YOLOv4 vs YOLOv5
In absence of any official paper, it is difficult to draw an authentic comparison between YOLOv4 vs YOLOv5. But if we are to quote this blog at Roboflow, the following can be a good reference point –
“If you’re a developer looking to incorporate near-realtime object detection into your project quickly, YOLOv5 is a great choice. If you’re a computer vision engineer in pursuit of state-of-the-art and not afraid of a little more custom configuration, YOLOv4 in Darknet continues to be most accurate.”
From an operational standpoint of view, we put forward the following comparison between YOLOv4 and YOLOv5.
- Installation: In order to use Yolov4 one has to build the ‘darknet.exe’ app using the darknet repository whereas in the case of Yolov5 you can just run the ‘requirements.txt’ file and start using the models.
- Directory structure: In the case of custom data Yolov4 requires the path to two different directories containing the images and their annotations(txt or XML format is used). While Yolov5 uses ‘yml’ files.
- Storage size: Yolov4 stores weights in the ‘.weights’ format and the least is 250mbs(Yolov4). While Yolov5 stores it in ‘.pt’ format(PyTorch format) and the YOLOv5 S version has a 27MB weight file.
YOLOv5 Tutorial for Object Detection with Examples
In this section, we will see hands-on examples of using YOLOv5 for object detection of both images and videos, including YouTube videos. We are using Colab for the tutorial, so let us first understand how to set up the environment.
i) Environment Setup
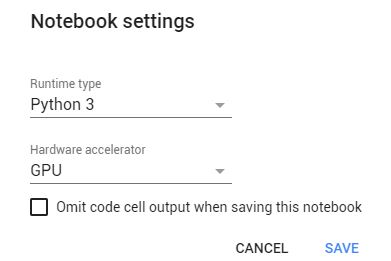
a) Enable GPU in Google Colab
Visit Google Colaboratory, a free online Jupyter Notebook with GPU provided by Google research. Next, change the runtime type to GPU but visiting the notebook settings.
b) Mounting Our drive
Run the below code to mount and use your personal google drive. You can use the images/videos present in your own drive
from google.colab import drive
drive.mount('/content/drive')
c) Cloning the YOLOv5 Repository
Clone the YOLOv5 repository made and maintained by Ultralytics.
Input:
!git clone https://github.com/ultralytics/yolov5
Output:
Cloning into 'yolov5'... remote: Enumerating objects: 7103, done. remote: Counting objects: 100% (209/209), done. remote: Compressing objects: 100% (129/129), done. remote: Total 7103 (delta 122), reused 154 (delta 80), pack-reused 6894 Receiving objects: 100% (7103/7103), 9.12 MiB | 19.58 MiB/s, done. Resolving deltas: 100% (4858/4858), done.
d) Installing Requirements
Run the following command to install the required package in order to run the YOLOv5 detector. The second command is to go inside the directory where the files reside.
!pip install -r yolov5/requirements.txt !cd /content/yolov5
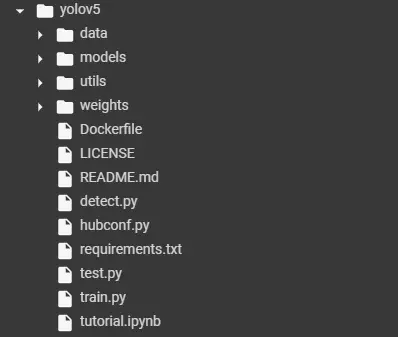
After the successful execution the directory structure looks like this:
ii) How to Inference YOLOv5
The YOLOv5 model can be used for inferencing just by a single command, show syntax and parameters are shown below –
!python <path to detect.py> --source <path to Image/Video/Youtube video> --weights <path to weights> --conf <Min Confidence Value>
Parameters:
<path to detect.py>: Detect.py initializes our detector and contains the code to make predictions.
<path to Image/Video/Youtube Video>: Here you provide the path of the image, Video, or a youtube link on which the detection process is to be performed.
<path to weights>: Here we provide the weight file i.e. the model we wish to use for the detection.
<Min confidence value>: Min confidence value for the model to consider a prediction as viable.
iii) Example of YOLOv5s
!python /content/yolov5/detect.py --source /content/drive/MyDrive/test1.jpeg --weights yolov5s.pt --conf 0.25


iv) Example of YOLOv5m
YOLOv5m has 308 layers, 21 million parameters, a mean average precision of 44.5, and an average speed of inference of 2.7ms(FLOPs value at 51.3 billion).
Run the following command to perform inference with the YOLOv5m version:
Input:
!python /content/yolov5/detect.py --source /content/drive/MyDrive/test3.jpg --weights yolov5m.pt --conf 0.25

Yolov5m Output
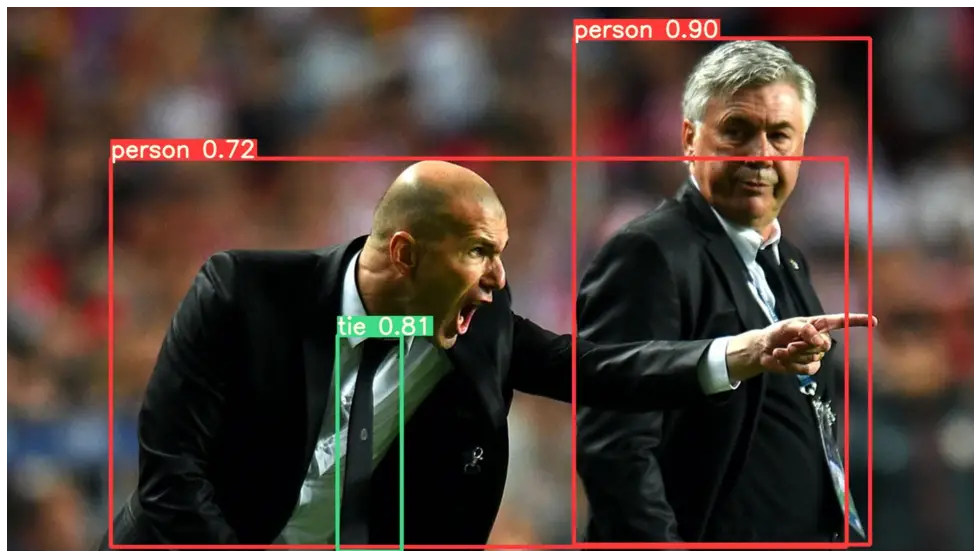
v) Example of YOLOv5l
The YOLOv5l version has 47 million parameters and 392 layers. It recorded an mAP of 48.2 percent with an inference speed of 3.8ms on average(since FLOPs value is 115.4 billion).
Run the following command to perform inference with the YOLOv5l version:
Input:
!python /content/yolov5/detect.py --source /content/yolov5/data/images/bus.jpg --weights yolov5l.pt --conf 0.25


vi) Example of YOLOv5x
The biggest model referred to as the YOLOv5x and it has 476 layers and 87 million parameters along with a FLOPs value of 218.6 Billion in value. It recorded an inference speed of 6.1ms and an mAP of 50.4 percent.
Run the following command to perform inference with the YOLOv5x version:
Input:
!python /content/yolov5/detect.py --source /content/drive/MyDrive/test2.jpeg --weights yolov5x.pt --conf 0.25
The model is able to predict accurately even on complex images. That is pretty normal, what is of importance is the single inference time it increases with an increase in parameters.
Output:


vii) YOLOv5 Object Detection on Videos
The YOLOv5 command that we have seen in the above examples for images works seamlessly with videos as well. We just have to pass the path of the video saved in our drive, as shown below.
Input:
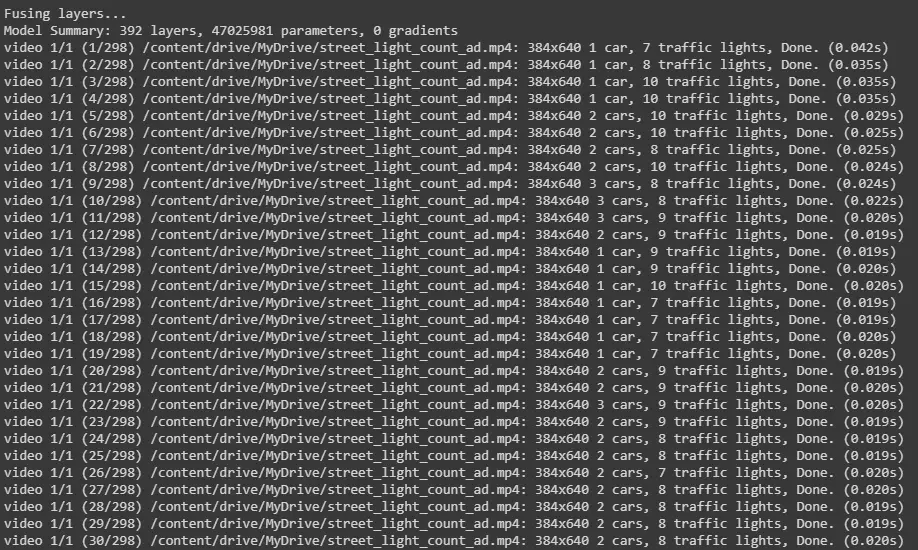
!python /content/yolov5/detect.py --source /content/drive/MyDrive/street_light_count_ad.mp4 --weights yolov5l.pt --conf 0.25
Video is processed frame by frame and predictions for each frame is printed.
Output:

vii) YOLOv5 Object Detection on YouTube Videos
YOLOv5 has done it one step better by adding the capability to perform object detection on a YouTube video by just passing the URL as shown below.
Input:
!python /content/yolov5/detect.py --source https://www.youtube.com/watch?v=jjlBnrzSGjc --weights yolov5m.pt --conf 0.25
Output:
Conclusion
We hope you found this introduction and tutorial on YOLOv5 for object detection quite useful. All the controversy aside, YOLOv5 is a cool model that requires minimal effort to work with it and produces impressive practical results as we saw in the example.
Disclaimer –
Please note that the inclusion of YOLOv5 in the YOLO family is a matter of debate in the community, and neither its paper has been released officially for peer review. So its architectural and performance details mentioned here, as collected from the various sources have to be taken with a pinch of salt.
Reference –
- https://github.com/ultralytics/yolov5
- https://blog.roboflow.com/yolov5-improvements-and-evaluation/
- https://pytorch.org/hub/ultralytics_yolov5/
- https://blog.roboflow.com/yolov4-versus-yolov5/
- https://www.researchgate.net/publication/349299852_A_Forest_Fire_Detection_System_Based_on_Ensemble_Learning


