
Introduction
In this tutorial, we will see how to implement Linear Regression in the Python Sklearn library. We will see the LinearRegression module of Scitkit Learn, understand its syntax, and associated hyperparameters. And then we will deep dive into an example to see the proper implementation of linear regression in Sklearn with a dataset.
But first of all, we will have a quick overview of linear regression.
What is Linear Regression
Linear Regression is a kind of modeling technique that helps in building relationships between a dependent scalar variable and one or more independent variables. They are also known as the outcome variable and predictor variables.
Although it has roots in statistics, Linear Regression is also an essential tool in machine learning for tasks like predictive modeling.
Linear regression attempts to model the relationship between two variables by fitting a linear equation to observed data.
Hyperparameter in Linear Regression
Hyperparameters are parameters that are given as input by the users to the machine learning algorithms Hyperparameter tuning can increase the accuracy of the model.
However, in simple linear regression, there is no hyperparameter tuning
Linear Regression in Python Sklearn
If we want to perform linear regression in Python, we have a function LinearRegression() available in the Scikit Learn package that can make our job quite easy.
Let us understand the syntax of LinearRegression() below.
Syntax of LinearRegression()
class sklearn.linear_model.LinearRegression(*, fit_intercept=True, normalize=False, copy_X=True, n_jobs=None, positive=False)
Parameters
- fit_intercept: This parameter determines whether an intercept has to be calculated or not. It is a boolean value and by default it is True.
- normalize: When the value of the above fit_intercept is False then this parameter is ignored. When fit_intercept is True then regressor X will be normalized. The default value is False.
- copy_X: If set to True, then X will be copied otherwise it is overwritten. By default it is True.
- n_jobs: It denotes the number of jobs to be used for computation. It is int value and by default it is None.
- positive: If set as true, coefficients are forced to be true. It only works for dense arrays. By default it is False.
Example of Linear Regression with Python Sklearn
In this section, we will see an example of end-to-end linear regression with the Sklearn library with a proper dataset.
We will work with water salinity data and will try to predict the temperature of the water using salinity
1. Loading the Libraries
We first load the necessary libraries for our example like numpy, pandas, matplotlib, and seaborn. Finally, we load several modules from sklearn including our LinearRegression.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn import preprocessing, svm
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
2. Loading the Dataset
Now we will load the dataset for building the linear regression model. Since it’s a huge dataset as we can see below, we’ll be focusing on two main columns for the purpose of this tutorial.
df = pd.read_csv('bottle.csv')
df.head()
Output:
| Cst_Cnt | Btl_Cnt | Sta_ID | Depth_ID | Depthm | T_degC | Salnty | O2ml_L | STheta | O2Sat | … | R_PHAEO | R_PRES | R_SAMP | DIC1 | DIC2 | TA1 | TA2 | pH2 | pH1 | DIC Quality Comment | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 054.0 056.0 | 19-4903CR-HY-060-0930-05400560-0000A-3 | 0 | 10.50 | 33.440 | NaN | 25.649 | NaN | … | NaN | 0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | 1 | 2 | 054.0 056.0 | 19-4903CR-HY-060-0930-05400560-0008A-3 | 8 | 10.46 | 33.440 | NaN | 25.656 | NaN | … | NaN | 8 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 1 | 3 | 054.0 056.0 | 19-4903CR-HY-060-0930-05400560-0010A-7 | 10 | 10.46 | 33.437 | NaN | 25.654 | NaN | … | NaN | 10 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 1 | 4 | 054.0 056.0 | 19-4903CR-HY-060-0930-05400560-0019A-3 | 19 | 10.45 | 33.420 | NaN | 25.643 | NaN | … | NaN | 19 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 1 | 5 | 054.0 056.0 | 19-4903CR-HY-060-0930-05400560-0020A-7 | 20 | 10.45 | 33.421 | NaN | 25.643 | NaN | … | NaN | 20 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
5 rows × 74 columns
3. Exploratory Data Analysis
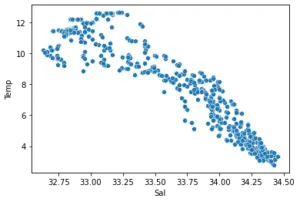
Since the dataset is quite huge, we’ll be utilizing only the first 500 values of this dataset. So, let’s first build a dataframe that contains only 500 values, and then, we’ll plot a scatter plot to understand the trend of the dataset.
This plot gives us an idea about the trend of our data and we can try to fit the linear regression model here.
df_binary500 = df_binary[:][:500]
sns.scatterplot(x ="Sal", y ="Temp", data = df_binary500)
4. Data Pre-processing
We only want to work with two relevant columns that will tell about the salinity and temperature of oceans and will be helpful to create the regression model.
We make use of the below code to create a new dataframe with Salinity and Temperature.
df_binary = df[['Salnty', 'T_degC']]
df_binary.columns = ['Sal', 'Temp']
df_binary.head()
| Sal | Temp | |
|---|---|---|
| 0 | 33.440 | 10.50 |
| 1 | 33.440 | 10.46 |
| 2 | 33.437 | 10.46 |
| 3 | 33.420 | 10.45 |
| 4 | 33.421 | 10.45 |
To get our dataset to perform better, we will fill the null values in the dataframes using fillna() function.
df_binary500.fillna(method ='ffill', inplace = True)
We also have to reshape the two columns of our dataframe, this will then be passed as variables for model building.
X = np.array(df_binary500['Sal']).reshape(-1, 1)
y = np.array(df_binary500['Temp']).reshape(-1, 1)
5. Train Test Split
We will now split our dataset into train and test sets. The training set will be used for creating a linear regression model and then its accuracy will be tested with the testing dataset.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25)
6. Model Training
Now we will train the model using LinearRegression() module of sklearn using the training dataset.
We create an instance of LinearRegression() and then we fit X_train and y_train.
regr = LinearRegression()
regr.fit(X_train, y_train)
7. Linear Regression Score
Now we will evaluate the linear regression model on the training data and then on test data using the score function of sklearn.
In [13]:
train_score = regr.score(X_train, y_train)
print("The training score of model is: ", train_score)
The training score of model is: 0.8442369113235618
test_score = regr.score(X_test, y_test)
print("The score of the model on test data is:", test_score )
The score of the model on test data is: 0.839197956273302
As we can see, the linear regression model has achieved a score of 0.839 on the test data set and it was 0.842 on the train data set. So overall we have created a good linear regression model in Sklearn.
8. Visualizing the Results
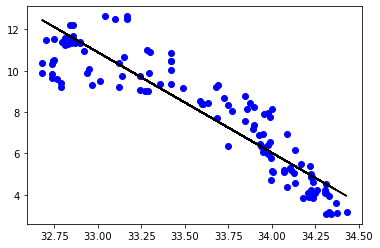
As a final step, we will visualize the result of the linear regression model by plotting the regression line with test data.
y_pred = regr.predict(X_test)
plt.scatter(X_test, y_test, color ='b')
plt.plot(X_test, y_pred, color ='k')
plt.show()
Conclusion
In this tutorial, we learned about the implementation of linear regression in the Python sklearn library. We discussed the syntax of the linear regression function in sklearn and finally saw an end-to-end example of linear regression with sklearn using a dataset.

