
Introduction
In this article, we will go through the tutorial of Keras Tokenizer API for dealing with natural language processing (NLP). We will first understand the concept of tokenization in NLP and see different types of Keras tokenizer functions – fit_on_texts, texts_to_sequences, texts_to_matrix, sequences_to_matrix with examples.
What does Tokenization mean?
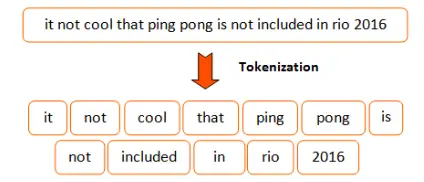
Tokenization is a method to segregate a particular text into small chunks or tokens. Here the tokens or chunks can be anything from words to characters, even subwords.
Tokenization is divided into 3 major types-
- Word Tokenization
- Character Tokenization
- Subword tokenization
Let us understand this concept of word tokenization with the help of an example sentence – “We will win”.
Usually, word tokenization is performed by using space acts as a delimiter. So in our example, we obtain three word tokens from the above sentence, i.e. We-will-win.
Just like the above example, if we have a word say Relaxing. Then the character tokens and subword tokens are shown below:
Character Tokens : R-e-l-a-x-i-n-g
Subword Tokens: Relax-ing
I hope, this section explains the basic concept of tokenization, let us now go into details about Keras Tokenizer Class.
Keras Tokenizer Class
The Tokenizer class of Keras is used for vectorizing a text corpus. For this either, each text input is converted into integer sequence or a vector that has a coefficient for each token in the form of binary values.
Keras Tokenizer Syntax
The below syntax shows the Keras “Tokenizer” function, along with all the parameters that are used in the function for various purposes.
tf.keras.preprocessing.text.Tokenizer(
num_words=None,
filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n',
lower=True,
split=" ",
char_level=False,
oov_token=None,
document_count=0,
**kwargs)Methods of Keras Tokenizer Class
- fit_on_texts
- texts_to_sequences
- texts_to_matrix
- sequences_to_matrix
1. fit_on_texts
The fit_on_texts method is a part of Keras tokenizer class which is used to update the internal vocabulary for the texts list. We need to call be before using other methods of texts_to_sequences or texts_to_matrix.
- word_counts : It is a dictionary of words along with the counts.
- word_docs : Again a dictionary of words, this tells us how many documents contain this word
- word_index : In this dictionary, we have unique integers assigned to each word.
- document_count : This integer count will tell us the total number of documents used for fitting the tokenizer.
Example 1 : fit_on_texts on Document List
from keras.preprocessing.text import Tokenizer
t = Tokenizer()
# Defining 4 document lists
fit_text = ['Machine Learning Knowledge',
'Machine Learning',
'Deep Learning',
'Artificial Intelligence']
t.fit_on_texts(fit_text)
print("The document count",t.document_count)
The document count 4
print("The count of words",t.word_counts)
print("The word index",t.word_index)
print("The word docs",t.word_docs)
Example 2 : fit_on_texts on String
fit_on_texts, when applied on a string text, its attributes produce different types of results.
- The word_count shows the number of times a character has occurred.
- The document_count prints the number of characters present in our input text.
- The word_index assigns a unique index to each character present in the text.
- The word_docs produces results similar to word_counts and gives the frequency of characters.
[6]:
t = Tokenizer()
fit_text = 'Machine Learning'
t.fit_on_texts(fit_text)
print("Count of characters:",t.word_counts)
print("Length of text:",t.document_count)
print("Character index",t.word_index)
print("Frequency of characters:",t.word_docs)
2. texts_to_sequences
Example 1: texts_to_sequences on Document List
We can see here in the example that given a corpus of documents, texts_to_sequences assign integers to words. For example, ‘machine’ is assigned value 2.
t = Tokenizer()
test_text = ['Machine Learning Knowledge',
'Machine Learning',
'Deep Learning',
'Artificial Intelligence']
t.fit_on_texts(test_text)
sequences = t.texts_to_sequences(test_text)
print("The sequences generated from text are : ",sequences)
Example 2: texts_to_sequences on String
In this example, texts_to_sequences assign integers to characters. For example, ‘e’ is assigned a value ‘4’.
t = Tokenizer()
test_text = "Machine Learning"
t.fit_on_texts(test_text)
sequences = t.texts_to_sequences(test_text)
print("The sequences generated from text are : ",sequences)
3. texts_to_matrix
Another useful method of tokenizer class is texts_to_matrix() function for converting the document into a numpy matrix form.
This function works in 4 different modes –
- binary : The default value that tells us about the presence of each word in a document.
- count : As the name suggests, the count for each word in the document is known.
- tfidf : The TF-IDF score for each word in the document.
- freq : The frequency tells us about ratio of words in each document.
Example 1: texts_to_matrix with mode = binary
The binary mode in texts_to_matrix() function determines the presence of text by using ‘1’ in the matrix where the word is present and ‘0’ where the word is not present.
NOTE: This mode doesn’t count the total number of times a particular word or text, but it just tells about the presence of word in each of the documents.
# define 5 documents
docs = ['Marvellous Machine Learning Marvellous Machine Learning',
'Amazing Artificial Intelligence',
'Dazzling Deep Learning',
'Champion Computer Vision',
'Notorious Natural Language Processing Notorious Natural Language Processing']
# create the tokenizer
t = Tokenizer()
t.fit_on_texts(docs)
encoded_docs = t.texts_to_matrix(docs, mode='binary')
print(encoded_docs)
Example 2: texts_to_matrix with mode = count
The count mode in texts_to_matrix() function determines the number of times the words appear in each of the documents.
# define 5 documents
docs = ['Marvellous Machine Learning Marvellous Machine Learning',
'Amazing Artificial Intelligence',
'Dazzling Deep Learning',
'Champion Computer Vision',
'Notorious Natural Language Processing Notorious Natural Language Processing']
# create the tokenizer
t = Tokenizer()
t.fit_on_texts(docs)
encoded_docs = t.texts_to_matrix(docs, mode='count')
print(encoded_docs)
Example 3: texts_to_matrix with mode = tfidf
TF-IDF or Term Frequency – Inverse Document Frequency, works by checking the relevance of a word in a given text corpus.
In this mode, a proportional score is given to words on the basis of the number of times they occur in the text corpus. In this way, this model can determine which words are worthy and which aren’t.
t.fit_on_texts(docs)
encoded_docs = t.texts_to_matrix(docs, mode='tfidf')
print(encoded_docs)
Example 4: texts_to_matrix with mode = freq
This last mode used in texts_to_matrix() is the frequency that actually determines a score and assigning to each on the basis of the ratio of the word with all the words in the document or text corpus.
t.fit_on_texts(docs)
encoded_docs = t.texts_to_matrix(docs, mode='freq')
print(encoded_docs)
4. sequences_to_matrix
This function sequences_to_matrix() of Keras tokenizer class is used to convert the sequences into a numpy matrix form.
sequences_to_matrix also has 4 different modes to work with –
- binary : The default value that tells us about the presence of each word in a document.
- count : As the name suggests, the count for each word in the document is known.
- tfidf : The TF-IDF score for each word in the document.
- freq : The frequency tells us about ratio of words in each document.
Example 1: sequences_to_matrix with mode = binary
In [14]:
# define 4 documents
docs =['Machine Learning Knowledge',
'Machine Learning and Deep Learning',
'Deep Learning',
'Artificial Intelligence']
# create the tokenizer
t = Tokenizer()
t.fit_on_texts(docs)
sequences = t.texts_to_sequences(docs)
encoded_docs = t.sequences_to_matrix(sequences, mode='binary')
print(encoded_docs)
Example 2: sequences_to_matrix with mode = count
In [15]:
# define 4 documents
docs =['Machine Learning Knowledge',
'Machine Learning and Deep Learning',
'Deep Learning',
'Artificial Intelligence']
# create the tokenizer
t = Tokenizer()
t.fit_on_texts(docs)
sequences = t.texts_to_sequences(docs)
encoded_docs = t.sequences_to_matrix(sequences, mode='count')
print(encoded_docs)

