
Introduction
What is Bag of Visual Words
Relation with Bag of Words
In the bag of word model, the text is represented with the frequency of its word without taking into account the order of the words (hence the name ‘bag’).
The main idea behind the counting of the word is:
Documents that share a large number of the same keywords, regardless of the order the keywords appear in, are considered to be relevant to each other.
Bag of Visual Words
In Computer Vision, the same concept is used in the bag of visual words. Here instead of taking the word from the text, image patches and their feature vectors are extracted from the image into a bag. Features vector is nothing but a unique pattern that we can find in an image.
To put it simply, Bag of Visual Word is nothing but representing an image as a collection of unordered image patches, as shown in the below illustration.
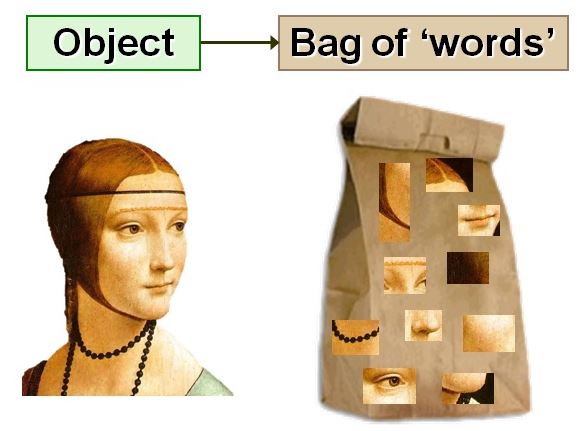
What is the Feature?
Basically, the feature of the image consists of keypoints and descriptors. Keypoints are the unique points in an image, and even if the image is rotated, shrink, or expand, its keypoints will always be the same. And descriptor is nothing but the description of the keypoint. The main task of a keypoint descriptor is to describe an interesting patch(keypoint)in an image.

Image classification with Bag of Visual Words
This Image classification with Bag of Visual Words technique has three steps:
- Feature Extraction – Determination of Image features of a given label.
- Codebook Construction – Construction of visual vocabulary by clustering, followed by frequency analysis.
- Classification – Classification of images based on vocabulary generated using SVM.
Let us go through each of the steps in detail.
Feature Extraction
The first step to build a bag of visual words is to perform feature extraction by extracting descriptors from each image in our dataset.
Feature representation methods deal with how to represent the patches as numerical vectors. These vectors are called feature descriptors.
A good descriptor should have the ability to handle the intensity, rotation, scale and affine variations to some extent.
One of the most famous descriptors is Scale-invariant feature transform (SIFT) and another one is ORB.
SIFT converts each patch to 128-dimensional vector. After this step, each image is a collection of vectors of the same dimension (128 for SIFT), where the order of different vectors is of no importance.
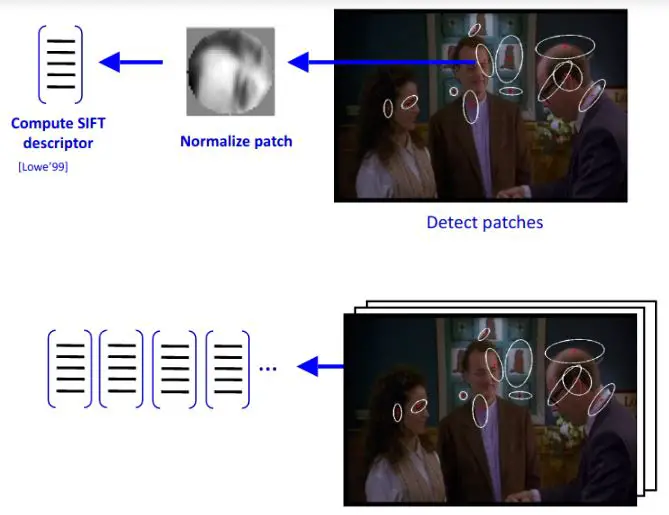
Codewords and Codebook Construction
The vectors generated in the feature extraction step above are now converted into the codewords which is similar to words in text documents. Codewords are nothing but vector representation of similar patches. This codeword also produces a codebook is similar to a word dictionary
This step normally accomplished via the k-means clustering algorithm. The outline of the K-Means clustering is shown below –
Given k:
- Select initial centroids at random.
- Assign each object to the cluster with the nearest centroid.
- Compute each centroid as the mean of the objects assigned to it.
- Repeat steps 2 and 3 until no change.
Some points to consider over here –
- Clustering, which is an unsupervised learning method, is commonly used for creating visual vocabulary or codebook.
- Each cluster center produced by k-means becomes a codeword.
- The number of clusters is the codebook size.
- Codebook can be learned on the separate training sets.
- Provided the training set is sufficiently representative, the codebook will be “universal”.
- The codebook is used for quantizing features. Quantization of features means that the Feature vector maps it to the index of the nearest codeword in a codebook.
So summarizing this step, each patch in an image is mapped to a certain codeword through the clustering process and the image can be represented by the histogram of the codewords.
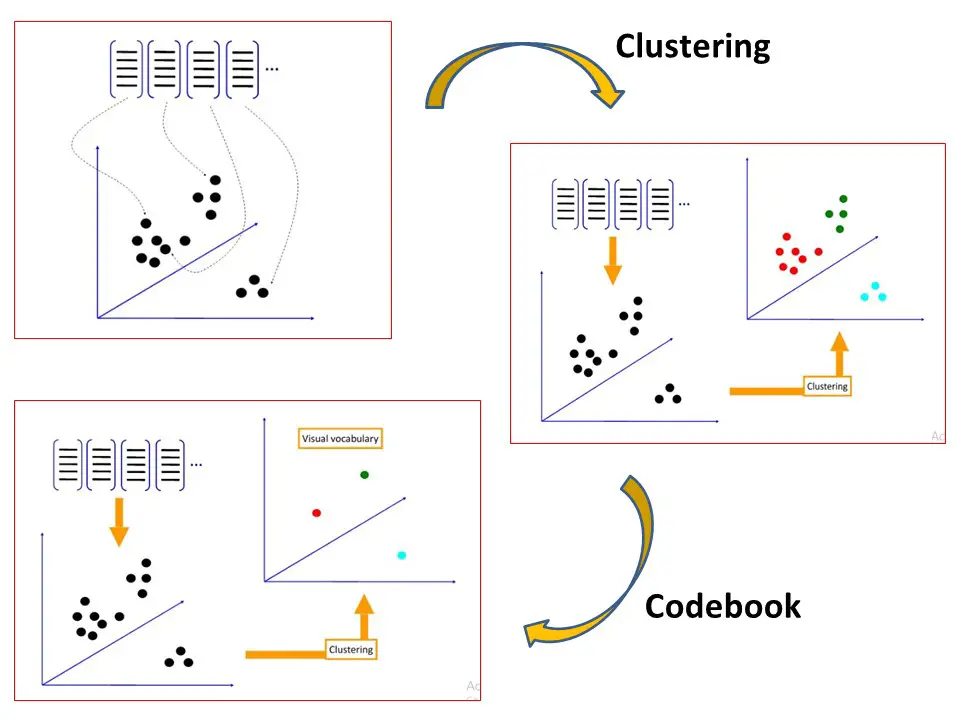
Example of Codebook

Classification
The next step consists of representing each image into a histogram of codewords.
It is done by first applying the keypoint detector or feature extractor and descriptor to every training image, and then matching every keypoint with those in the codebook.
The result of this is a histogram where the bins correspond to the codewords, and the count of every bin corresponds to the number of times the corresponding codeword matches a keypoint in the given image. In this way, an image can be represented by a histogram of codewords.
The histograms of the training images can then be used to learn a classification model. Here I am using SVM as a classification model.
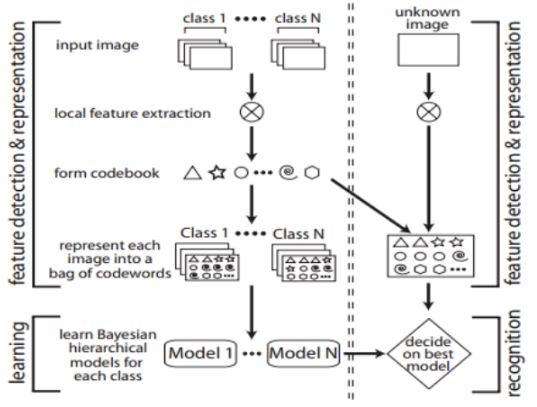
Coding Image Classifier using Bag Of Visual Words
In this example, we will use bag of visual words approach to perform image classification on dog and cat dataset.
Importing the required libraries
import cv2
import numpy as np
import os
import matplotlib.pyplot as plt
import random
import pylab as pl
from sklearn.metrics import confusion_matrix,accuracy_score
Defining the training path
In [4]:
train_path="dataset"
class_names=os.listdir(train_path)
print(class_names)
image_paths=[]
image_classes=[]
Function to List all the filenames in the directory
def img_list(path):
return (os.path.join(path,f) for f in os.listdir(path))
for training_name in class_names:
dir_=os.path.join(train_path,training_name)
class_path=img_list(dir_)
image_paths+=class_path
len(image_paths)
image_classes_0=[0]*(len(image_paths)//2)
image_classes_1=[1]*(len(image_paths)//2)
image_classes=image_classes_0+image_classes_1
Append all the image path and its corresponding labels in a list
D=[]
for i in range(len(image_paths)):
D.append((image_paths[i],image_classes[i]))
Shuffle Dataset and split into Training and Testing
dataset = D
random.shuffle(dataset)
train = dataset[:180]
test = dataset[180:]
image_paths, y_train = zip(*train)
image_paths_test, y_test = zip(*test)
Feature Extraction using ORB
des_list=[]
orb=cv2.ORB_create()
im=cv2.imread(image_paths[1])
plt.imshow(im)

Function for plotting keypoints
def draw_keypoints(vis, keypoints, color = (0, 255, 255)):
for kp in keypoints:
x, y = kp.pt
plt.imshow(cv2.circle(vis, (int(x), int(y)), 2, color))
Plotting the keypoints
kp = orb.detect(im,None)
kp, des = orb.compute(im, kp)
img=draw_keypoints(im,kp)

for image_pat in image_paths:
im=cv2.imread(image_pat)
kp=orb.detect(im,None)
keypoints,descriptor= orb.compute(im, kp)
des_list.append((image_pat,descriptor))
descriptors=des_list[0][1]
for image_path,descriptor in des_list[1:]:
descriptors=np.vstack((descriptors,descriptor))
descriptors.shape
descriptors_float=descriptors.astype(float)
Performing K Means clustering on Descriptors
from scipy.cluster.vq import kmeans,vq
k=200
voc,variance=kmeans(descriptors_float,k,1)
Creating histogram of training image
im_features=np.zeros((len(image_paths),k),"float32")
for i in range(len(image_paths)):
words,distance=vq(des_list[i][1],voc)
for w in words:
im_features[i][w]+=1
Applying standardisation on training feature
from sklearn.preprocessing import StandardScaler
stdslr=StandardScaler().fit(im_features)
im_features=stdslr.transform(im_features)
Creating Classification Model with SVM
from sklearn.svm import LinearSVC
clf=LinearSVC(max_iter=80000)
clf.fit(im_features,np.array(y_train))
Testing the Classification Model
In [36]:
des_list_test=[]
for image_pat in image_paths_test:
image=cv2.imread(image_pat)
kp=orb.detect(image,None)
keypoints_test,descriptor_test= orb.compute(image, kp)
des_list_test.append((image_pat,descriptor_test))
len(image_paths_test)
from scipy.cluster.vq import vq
test_features=np.zeros((len(image_paths_test),k),"float32")
for i in range(len(image_paths_test)):
words,distance=vq(des_list_test[i][1],voc)
for w in words:
test_features[i][w]+=1
test_features
test_features=stdslr.transform(test_features)
true_classes=[]
for i in y_test:
if i==1:
true_classes.append("Cat")
else:
true_classes.append("Dog")
predict_classes=[]
for i in clf.predict(test_features):
if i==1:
predict_classes.append("Cat")
else:
predict_classes.append("Dog")
print(true_classes)
print(predict_classes)
clf.predict(test_features)
accuracy=accuracy_score(true_classes,predict_classes)
print(accuracy)
Conclusion
As we can see above, we were able to achieve an accuracy of 65% with this classical technique of image classification with bag of visual words model. Now deep learning models have raised the bar of accuracy to more than 90% but before that, accuracy in the range of 65% to 75% was the benchmark with old techniques.
Reference –
[1]
L. Fei-Fei and P. Perona, “A bayesian hierarchical model for learning natural scene categories,” in Computer Vision and Pattern Recognition, 2005. CVPR2005. IEEE Computer Society Conference on, vol. 2, pp. 524–531, IEEE, 2005
[2]
http://people.csail.mit.edu/torralba/shortCourseRLOC/


2 Responses
Nice tutorial. Well done. Please can you make tutorial using Canny edge and HOG too with SVM or RF. Thanks
Thank You. Sure.. thanks for the feedback.