
Introduction
An artificial neural network consists of many artificial neurons stacked in one or more layers and each layer contains many artificial neurons. Each of these artificial neurons contains something known as the Activation Function. These activation functions are what add life and dynamics into the neural networks. There are many types of activation functions in neural network and each of them has its own characteristics & use cases.
In this post, we will discuss some of the most popular activation functions used in neural networks and deep learning. But before that, we will try to understand why the activation function is used in the first place.
Artificial Neuron – A Quick Recap
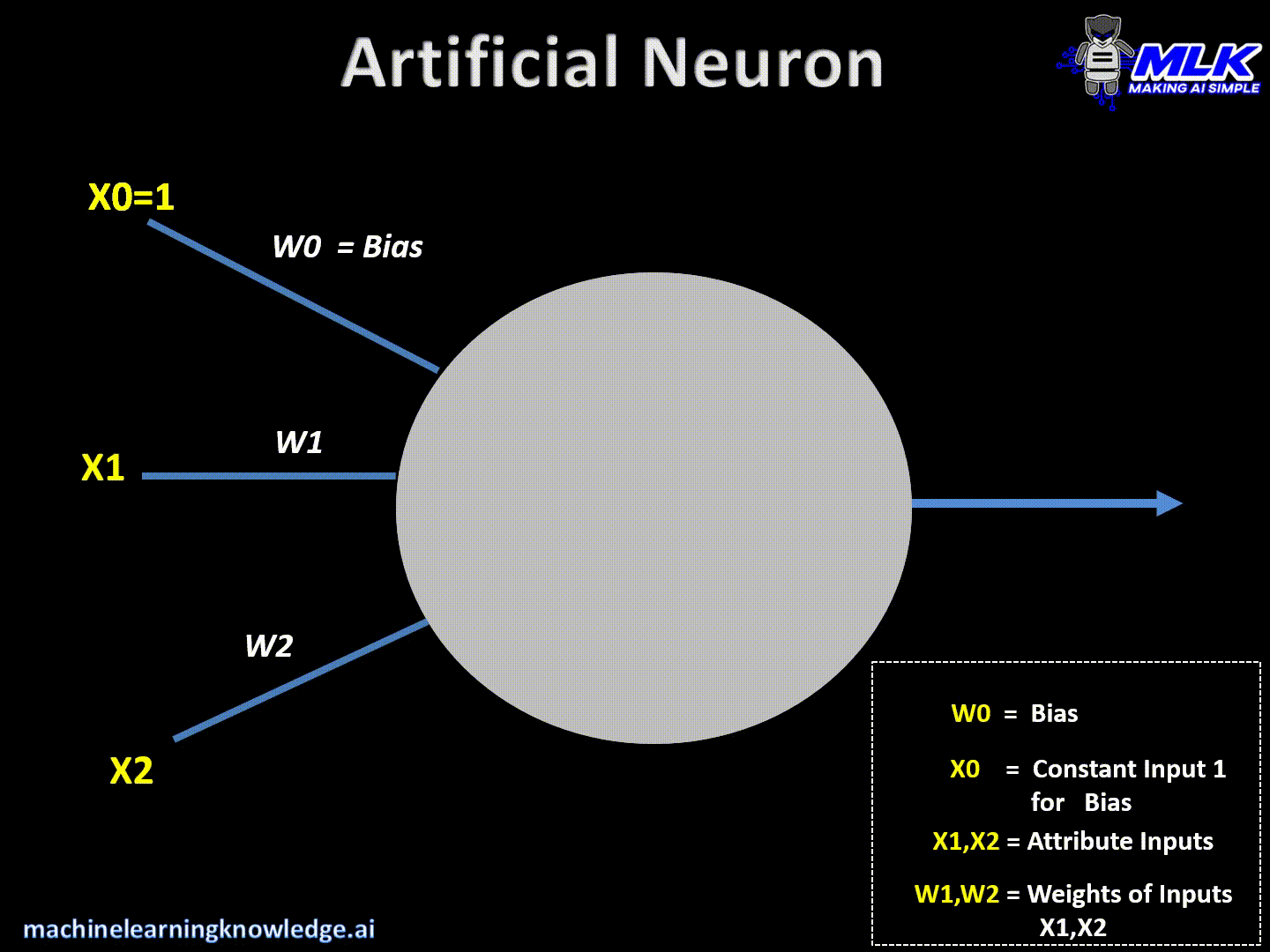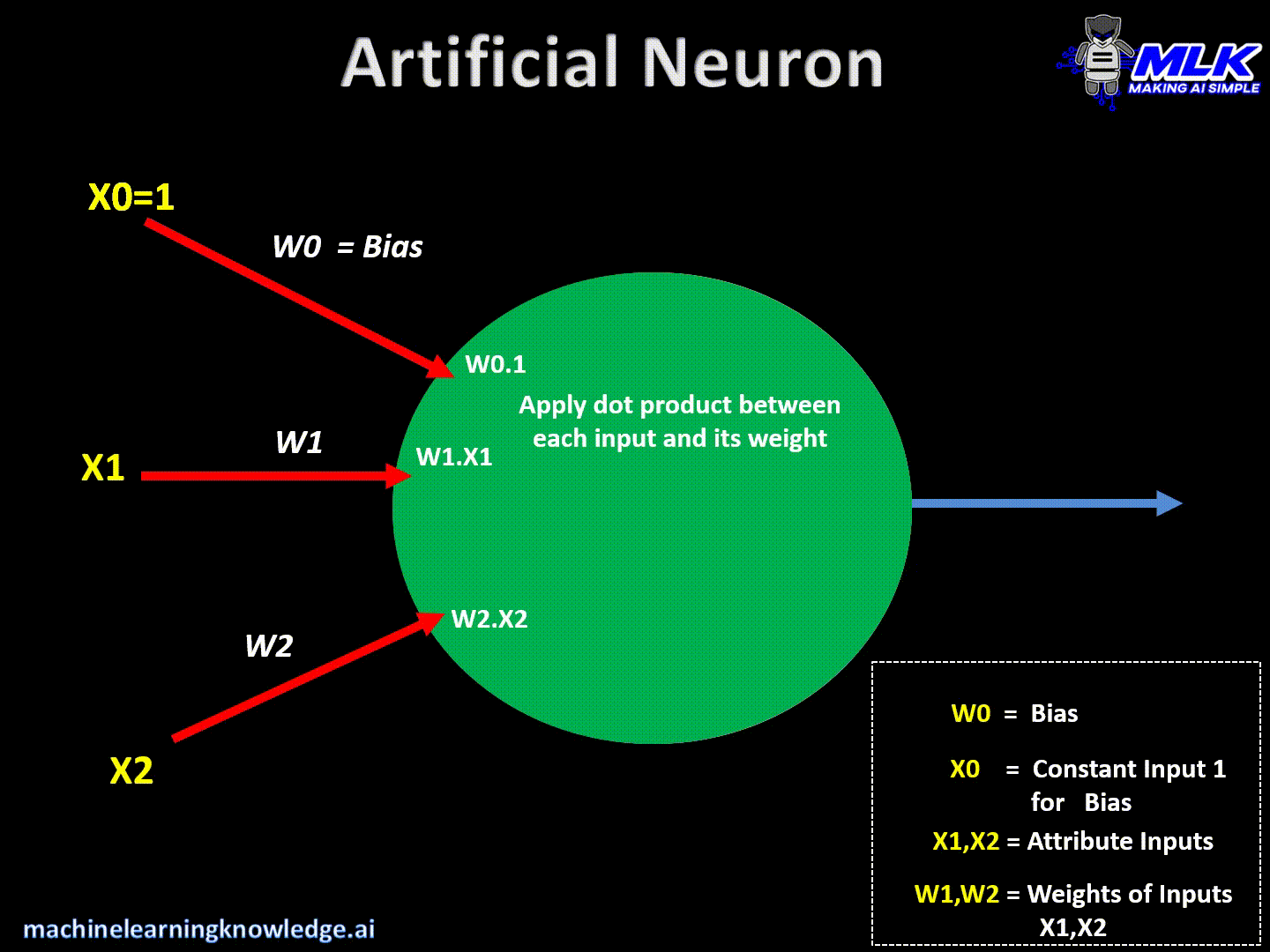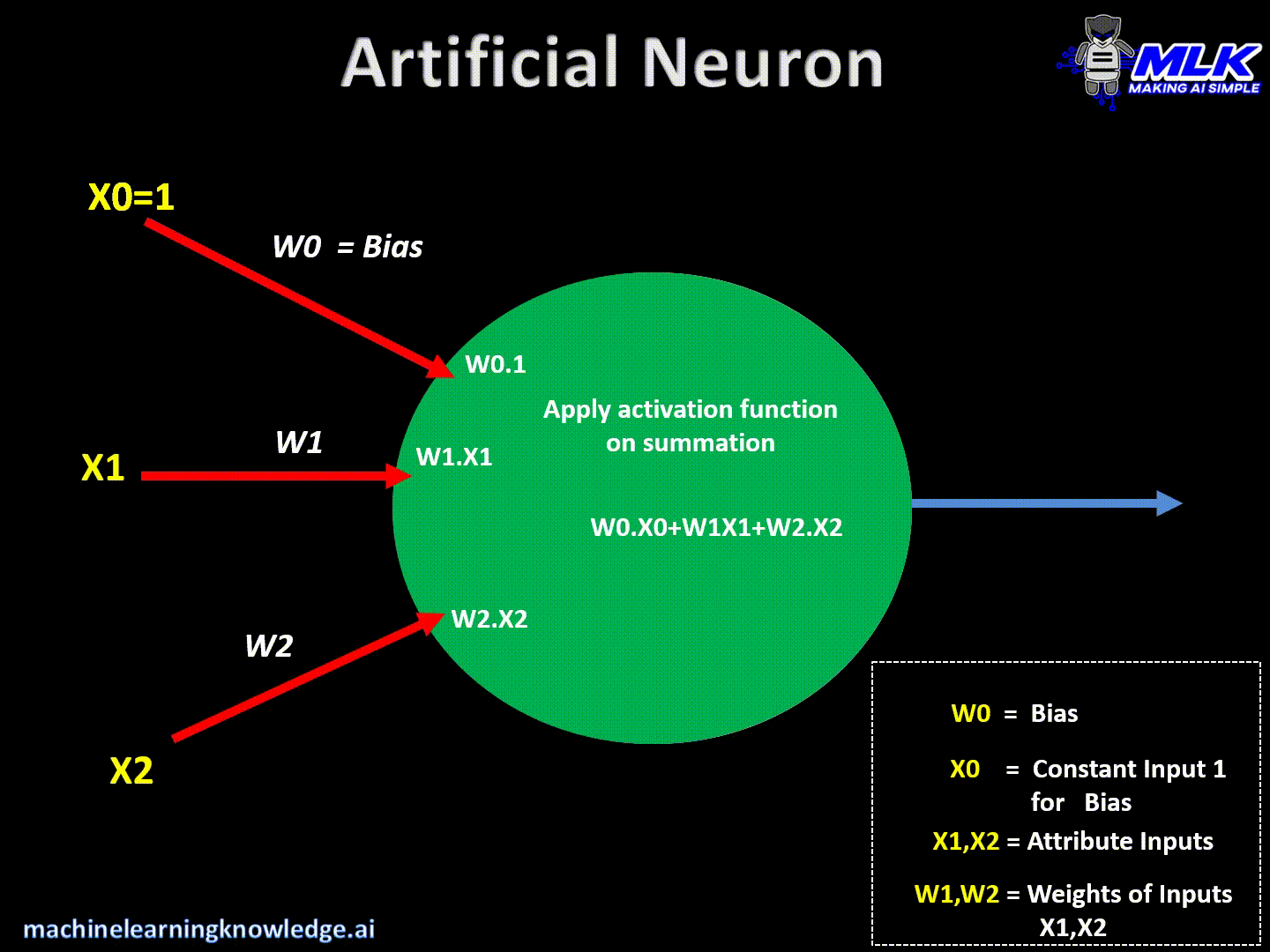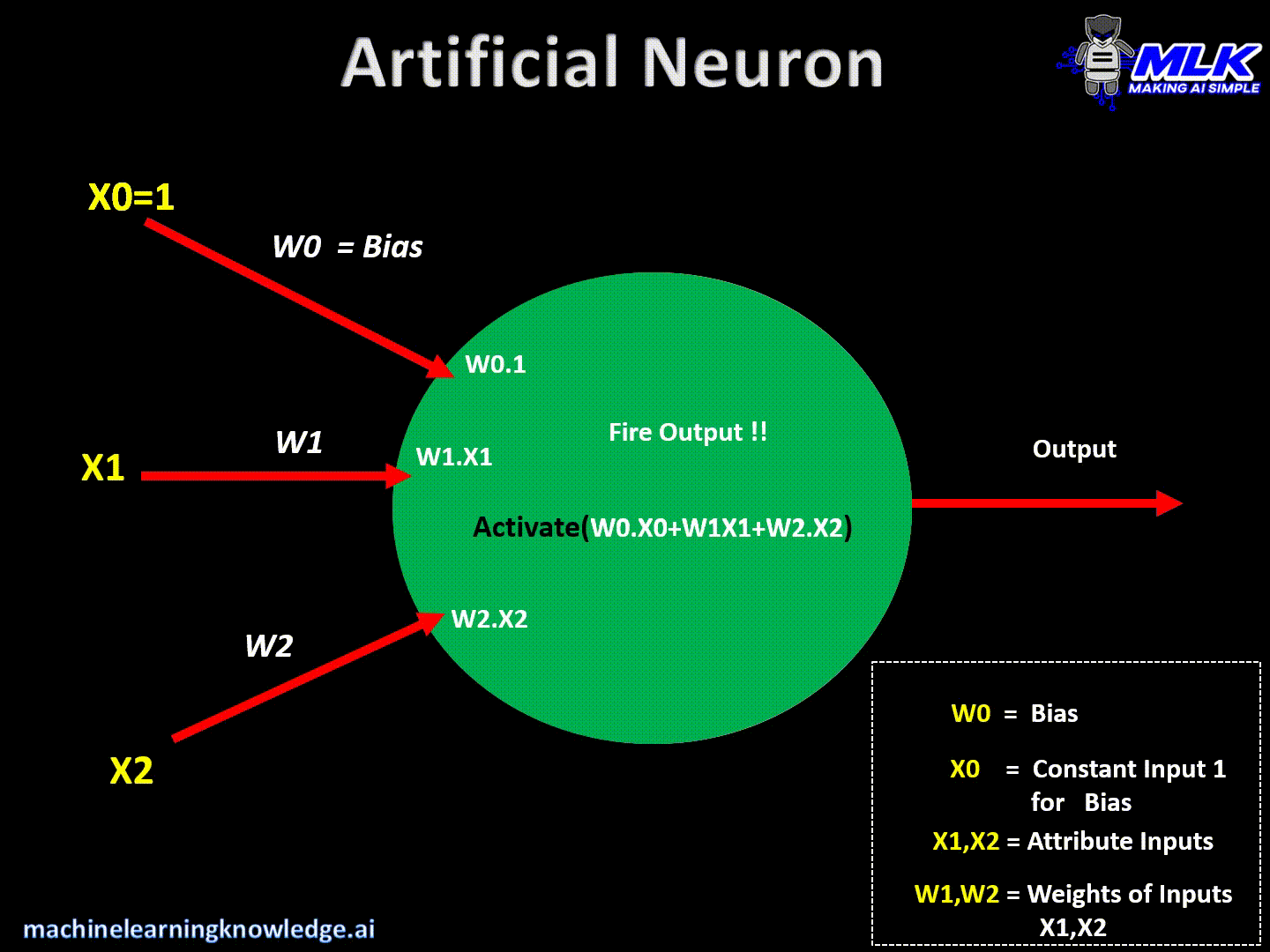
Artificial neurons are the basic building blocks of a neural network. It can be considered as a computational unit that takes some inputs, applies some transformation on the input and fires the output. Below are typical steps for computation inside the neuron.
- An artificial neuron takes the inputs and their respective weights.
- It then applies dot products between input values & its weights and sums them up.
- Finally, it applies activation function on above summation and fires the output
This can be written in a crude way as below –
Output = Activation(Summation(Inputs*Weights + bias))
For more, read our earlier post on Artificial Neuron
Why we need Activation Functions in Neural Network
As you can see in the above animation, the activation function is applying transformation on inputs of the artificial neuron to produce the output. But the question is why this transformation is required. What will happen without an activation function? Let us try to understand all this in the following sections.
Neural Network without Activation Function
An artificial neuron without an activation function will just produce the sum of dot products between all inputs and their weights.
Input : X0,X1,X2 then Output = W0X0+W1X1+W2X2 [without activation function].
Observe here, that the linear input has only produced a linear output. No matter how many such artificial neurons you stack up in the neural networks, without activation functions the network will only produce a linear output.
To put this in other words, the neural network would try to map input and output data during the training phase with only linear functions. No matter how hard it tries to learn the relation between input and output data during the training phase at the most neural network can only come up with a linear mapping function.
Real world data is almost always Non-Linear
In the real world, hardly any data is so simple that it can be represented with just a linear mapping function. You may just look around or give good thought and try to come up with some real-life examples of data that has only a linear relationship. I bet, you would not be able to come with more than a few if at all.
In fact, the relationship between real-world data is so complicated that at the time we need very complex non-linear functions to represent them.
Activation Function adds Non linearity to Neural Network
So how can neural networks learn the non-linear relationships between data? Well, this is where the activation function plays an important role. By using appropriate nonlinear activation function we can help the neural networks to understand this nonlinear relationship.
In fact, the neural network is actually proven to be Universal Function Approximators. This means that given enough training data and training time, the neural network can come up with an approximate function to represent any complex relationship within data. This is why neural networks have created a new era of Deep Learning and opened doors for the AI boom in the last few years.
Characteristics of good Activation Functions in Neural Network
There are many activation functions that can be used in neural networks. Before we take a look at the popular ones let us understand what is an ideal activation function.
- Non-Linearity – Activation function should be able to add nonlinearity in neural network especially in the neurons of hidden layers. The reason behind this already explained in the above section.
- Differentiable – Activation function should be differentiable. During the training phase, the neural network learns by back-propagating error from the output layer to hidden layers. The backpropagation algorithm uses derivative of activation function of neurons in hidden layers, to adjust their weights so that error in the next training epoch can be reduced.
[adrotate banner=”3″]
Types of Activation Functions in Neural Network
Many types of activation functions have been used or proposed over the years. Some have certain specific use cases and some have lost popularity over the years with the advent of better activation functions.
In this section, we will see some of the most common or popular activation functions.
Step Function
- This is a very intuitive activation function which only enables or disables artificial neuron.
- It can only produce two values 0 or 1. If it is 0 it means neuron has not fired, if it is 1 it means neuron has fired.
- It produces output 1 only when the sum of dot products of inputs & weights is more than a threshold value, else it will be 0.
- The step function is not smooth and has a sudden change at the threshold value.
- It is non-differentiable and it can neither add nonlinearity in the neural network This means it does not comply with good characteristics of activation functions that we discussed above.
- Step function has historical importance as it was used in McCulloch Pitts Neuron & Perceptron that were the earliest models of an artificial neuron.
Also Read – Neural Network Primitives Part 1 – McCulloch Pitts Neuron Model (1943)
Also Read – Neural Network Primitives Part 2 – Perceptron Model (1957)

Sigmoid Function
- Unlike step function, the sigmoid function is S-Shaped and is smooth, there is no sudden spike.
- The range of output is between 0 and 1 which is usually interpreted as probability if used in the output layer.
- This function is both non-linear and is differentiable which is a great thing as we discussed in the earlier section.
- This activation is a good candidate for using in neurons of hidden layers of neural networks.
- But sigmoid function suffers from phenomena of vanishing gradient which results in slow and poor learning of neural networks during the training phase.
- Now with the discovery of better activation functions in recent years which avoids this phenomenon, the sigmoid function has lost its place and is hardly used in hidden layers of neural networks.
- Sigmoid function, however, is still used in output neurons in case of binary classification problem to convert the incoming signal into a range of 0 to 1 so that it can be interpreted as a probability.
Also Read – Neural Network Primitives Part 3 – Sigmoid Neuron

Tanh Function
- Sigmoid function varies from 0 to 1, but there might be scenarios where we would like to introduce a negative sign to the output of the artificial neuron.
- This is where Tanh (hyperbolic tangent function) becomes useful. Tanh function is similar to sigmoid function but its output varies from +1 to -1 and is centered at zero.
- This is non-linear and differentiable but still suffers from phenomena of vanishing gradient similar to a sigmoid function.
- Hence Tanh is also not used much in the neural networks since recent years unless there is a pressing need to use.

ReLU Function
- In the above sections, we discussed a few activation functions but always concluded that these are not used nowadays. So you might be thinking what is that activation function which is actually used in current times. Well, here enters the ReLU function !!
- ReLU might look deceptive at first look but is actually non-linear and differentiable.
- What makes it stand out is that it does not suffer from phenomena of vanishing gradient. This is really great as this means the neural network will not learn slowly and poorly.
- ReLU, however, suffers from another problem. For any negative value of X, the derivative is 0 and this hinders the learning process so the particular neuron effectively dies out. There might be a scenario where most of the neurons in the neural network start dying and this can become another issue.
- In spite of dying neurons possibility, ReLU is computationally fast and shows great results when used in hidden layers.

Leaky ReLU
- The name suggests that Leaky ReLU or LReLU has something to do with ReLU that we discussed above. And yes, it does!
- Leaky ReLU tries to address the problem of neurons dying out in the case of the ReLU function.
- As you can see, that in the negative part, there is a small tiny bit of extension in the negative area instead of a zero. This means even derivative would be a very small fraction and not zero. This ensures that learning of the neuron does not stop during backpropagation.

Softmax Function
- Remember, I told you that in the case of binary classification Sigmoid function can be used in the output layer to transform incoming signals in the probability range.
- What if it is a case of multi-class classification. Well, we have Softmax function to help us.
- Softmax function comes from the family of Sigmoid functions only.
- Softmax function squashes the incoming signals for multiple classes in a probability distribution. The sum of this probability distribution would obviously be 1.

Summarizing everything
- Activation functions are important because they add non-linearity in the neural network which helps the network to learn the complex relationships between real-world data.
- The step function is an On-Off type of activation function that was used in first artificial neurons – McCulloch Pitt neuron and Perceptron more than 5 decades ago. It has no relevance in the modern deep learning era.
- Sigmoid and Tanh functions should be avoided in hidden layers as it might lead to a vanishing gradient problem.
- Sigmoid and softmax functions are now generally used in the output layer in case of binary and multi-class classification respectively.
- ReLU is now popularly used in the hidden layer as it is computationally faster and does not suffers from vanishing gradient problems.
- ReLU can suffer from dying neurons problem, to avoid this Leaky ReLU is used sometimes.
Also Read – Animated guide to Cost Functions in Machine Learning
In The End…
So we have just covered activation functions in neural networks and saw why they are used, their types and their pros and cons. I hope this knowledge will help you to configure your own neural network with an appropriate activation function. I consider activation functions like DNA of an artificial neuron. Just like biological DNA defines characteristics of a cell, even activation function also defines the characteristics of the artificial neuron.
Do share your feedback about this post in the comments section below. If you found this post informative, then please do share this and subscribe to us by clicking on the bell icon for quick notifications of new upcoming posts. And yes, don’t forget to join our new community MLK Hub and Make AI Simple together.


