
Introduction
The world right now is seeing a global AI revolution across all industry. And one of the driving factor of this AI revolution is Deep Learning. Thanks to giants like Google and Facebook, Deep Learning now has become a popular term and people might think that it is a recent discovery. But you might be surprise to know that history of deep learning dates back to 1940s.
Indeed, deep learning has not appeared overnight, rather it has evolved slowly and gradually over seven decades. And behind this evolution, there are many machine learning researchers who worked with great determination even when no one believed that neural networks have any future.
This is our humble attempt to take you through the history of deep learning to relive the key discoveries made by the researchers and how all these small baby steps contributed to the modern era of deep learning boom.
Deep Learning History Timeline

McCulloch Pitts Neuron – Beginning

Walter Pitts and Warren McCulloch in their paper, “A Logical Calculus of the Ideas Immanent in Nervous Activity” shows the mathematical model of biological neuron. This McCulloch Pitts Neuron has very limited capability and has no learning mechanism. Yet it will lay the foundation for artificial neural network & deep learning.
Frank Rosenblatt creates Perceptron

In his paper “The Perceptron: A Perceiving and Recognizing Automaton”, Rosenblatt shows the new avatar of McCulloch-Pitts neuron – ‘Perceptron’ that had true learning capabilities to do binary classification on it’s own. This inspires the revolution in research of shallow neural network for years to come, till first AI winter.
The first Backpropagation Model

Henry J. Kelley in his paper, “Gradient Theory of Optimal Flight Paths” shows the first ever version of continuous backpropagation model. His model is in context to Control Theory, yet it lays the foundation for further refinement in the model and would be used in ANN in future years.
Backpropagation with Chain Rule

Stuart Dreyfus in his paper, “The numerical solution of variational problems” shows a backpropagation model that uses simple derivative chain rule, instead of dynamic programming which earlier backpropagation models were using. This is yet another small step that strengthens the future of deep learning.
Birth of Multilayer Neural Network
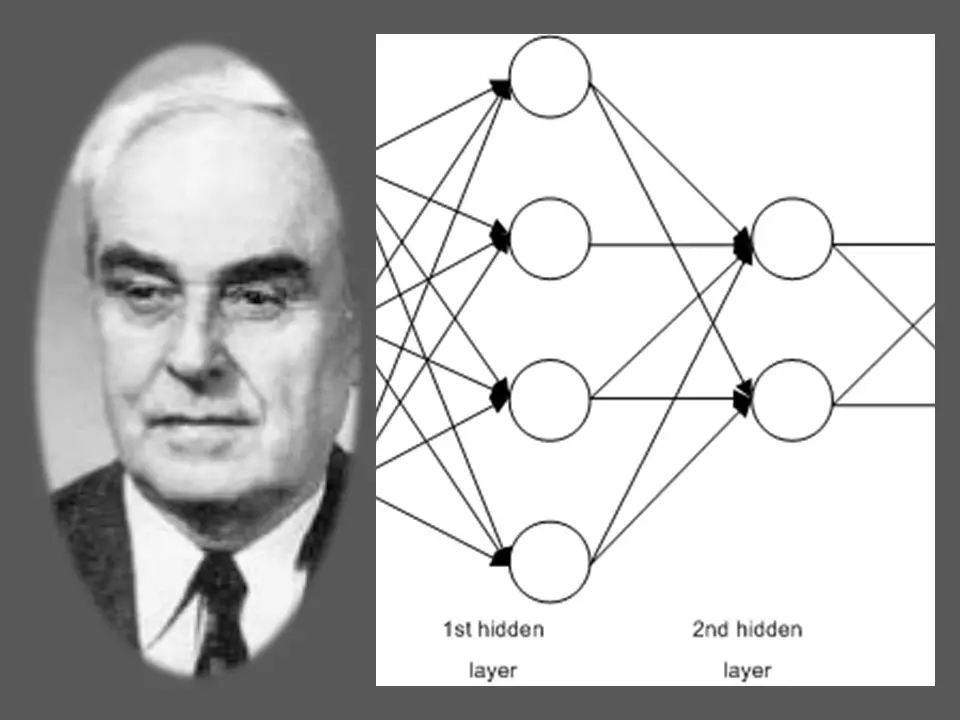
Alexey Grigoryevich Ivakhnenko along with Valentin Grigorʹevich Lapa, creates hierarchical representation of neural network that uses polynomial activation function and are trained using Group Method of Data Handling (GMDH). It is now considered as the first ever multi-layer perceptron and Ivakhnenko is often considered as father of deep learning.
The Fall of Perceptron

Marvin Minsky and Seymour Papert publishes the book “Perceptrons” in which they show that Rosenblatt’s perceptron cannot solve complicated functions like XOR. For such function perceptrons should be placed in multiple hidden layers which compromises perceptron learning algorithm. This setback triggers the winter of neural network research.
Backpropagation is computer coded

Seppo Linnainmaa publishes general method for automatic differentiation for backpropagation and also implements backpropagation in computer code. The research in backpropagation has now come very far, yet it would not be implemented in neural network till next decade.
Neural Network goes Deep

Alexey Grigoryevich Ivakhnenko continues his research in Neural Network. He creates 8-layer Deep neural network using Group Method of Data Handling (GMDH).
Hopfield Network – Early RNN
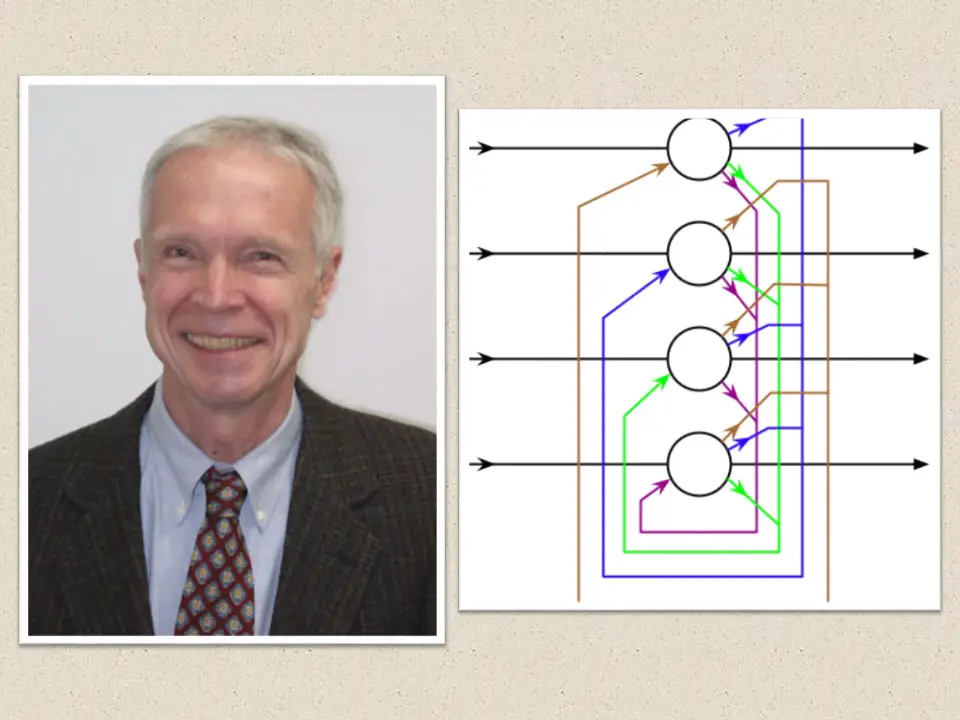
John Hopfield creates Hopfield Network, which is nothing but a recurrent neural network. It serves as a content-addressable memory system, and would be instrumental for further RNN models of modern deep learning era.
Proposal for Backpropagation in ANN

Paul Werbos, based on his 1974 Ph.D. thesis, publicly proposes the use of Backpropagation for propagating errors during the training of Neural Networks. His results of the Ph.D. thesis will eventually lead to the practical adoption of backpropagation by the neural network community in the future.
Boltzmann Machine

David H. Ackley, Geoffrey Hinton and Terrence Sejnowski create Boltzmann Machine that is a stochastic recurrent neural network. This neural network has only input layer and hidden layer but no output layer.
Implementation of Backpropagation

Geoffrey Hinton, Rumelhart, and Williams in their paper “Learning Representations by back-propagating errors” show the successful implementation of backpropagation in the neural network. It opened gates for training complex deep neural network easily which was the main obstruction in earlier days of research in this area.
Restricted Boltzmann Machine
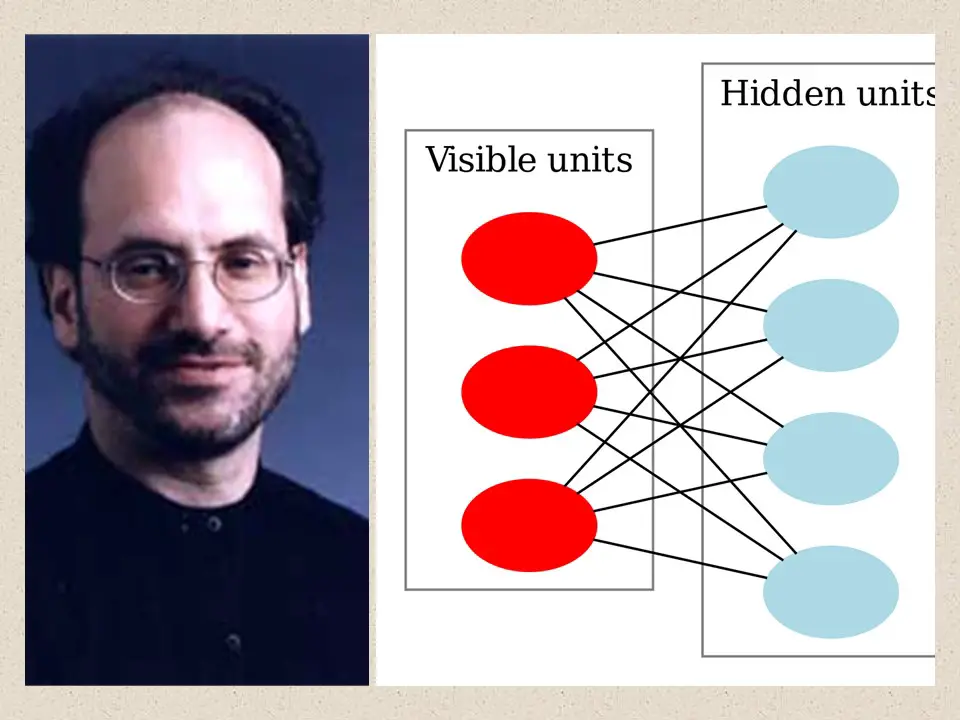
Paul Smolensky comes up with a variation of Boltzmann Machine where there is not intra layer connection in input and hidden layer. It is known as Restricted Boltzmann Machine (RBM). It would become popular in years to come especially for building recommender systems.
Universal Approximators Theorem

George Cybenko publishes earliest version of the Universal Approximation Theorem in his paper “Approximation by superpositions of a sigmoidal function“. He proves that feed forward neural network with single hidden layer containing finite number of neurons can approximate any continuous function. It further adds credibility to Deep Learning.
Vanishing Gradient Problem Appears

Sepp Hochreiter identifies the problem of vanishing gradient which can make the learning of deep neural network extremely slow and almost impractical. This problem will continue to annoy deep learning community for many more years to come.
The Milestone of LSTM

Sepp Hochreiter and Jürgen Schmidhuber publishes a milestone paper on “Long Short-Term Memory” (LSTM). It is a type of recurrent neural network architecture which will go on to revolutionize deep learning in decades to come.
Deep Belief Network

Geoffrey Hinton, Ruslan Salakhutdinov, Osindero and Teh publishes the paper “A fast learning algorithm for deep belief nets” in which they stacked multiple RBMs together in layers and called them Deep Belief Networks. The training process is much more efficient for large amount of data.
GPU Revolution Begins

Andrew NG’s group in Stanford starts advocating for the use of GPUs for training Deep Neural Networks to speed up the training time by many folds. This could bring practicality in the field of Deep Learning for training on huge volume of data efficiently.
ImageNet is launched

Finding enough labeled data has always been a challenge for Deep Learning community. In 2009 Fei-Fei Li, a professor at Stanford, launches ImageNet which is a database of 14 million labeled images. It would serve as a benchmark for the deep learning researchers who would participate in ImageNet competitions (ILSVRC) every year.
Combat for vanishing gradient

Yoshua Bengio, Antoine Bordes, Xavier Glorot in their paper “Deep Sparse Rectifier Neural Networks” shows that ReLU activation function can avoid vanishing gradient problem. This means that now, apart from GPU, deep learning community has another tool to avoid issues of longer and impractical training times of deep neural network.
AlexNet Starts Deep Learning Boom
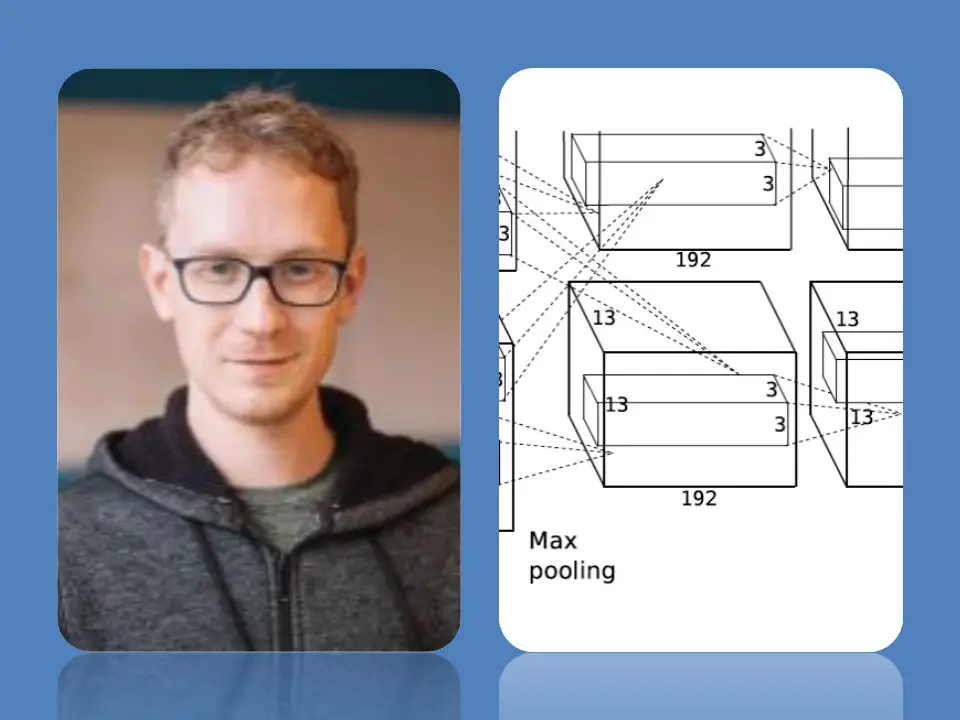
AlexNet, a GPU implemented CNN model designed by Alex Krizhevsky, wins Imagenet’s image classification contest with accuracy of 84%. It is a huge jump over 75% accuracy that earlier models had achieved. This win triggers a new deep learning boom globally.
The birth of GANs

Generative Adversarial Neural Network also known as GAN is created by Ian Goodfellow. GANs open a whole new doors of application of deep learning in fashion, art, science due it’s ability to synthesize real like data.
AlphaGo beats human

Deepmind’s deep reinforcement learning model beats human champion in the complex game of Go. The game is much more complex than chess, so this feat captures the imagination of everyone and takes the promise of deep learning to whole new level.
Trio win Turing Award

Yoshua Bengio, Geoffrey Hinton, and Yann LeCun wins Turing Award 2018 for their immense contribution in advancements in area of deep learning and artificial intelligence. This is a defining moment for those who had worked relentlessly on neural networks when entire machine learning community had moved away from it in 1970s.
[adrotate banner=”3″]
Disclaimer-
There would be countless researchers whose results, directly or indirectly, would have contributed to the emergence and boom of deep learning. This article only attempts to discover a brief history of deep learning by highlighting some key moments and events. Efforts have been made to reproduce the chronological events of deep learning history as accurately as possible. If you have any concerns or feedback, then please do write to us.
Sources-
- https://news.cornell.edu/stories/2019/09/professors-perceptron-paved-way-ai-60-years-too-soon
- https://en.wikipedia.org/wiki/Frank_Rosenblatthttps://en.wikipedia.org/wiki/Perceptron
- http://alchessmist.blogspot.com/2009/06/stuart-dreyfus-on-mathematics-chess.html
- https://www.sciencedirect.com/science/article/pii/0022247X62900045?via%3Dihub
- https://en.wikipedia.org/wiki/Backpropagation
- https://www.gwern.net/docs/statistics/decision/1960-kelley.pdf
- https://en.wikipedia.org/wiki/AI_winter
- http://beamandrew.github.io/deeplearning/2017/02/23/deep_learning_101_part1.html
- https://mailman.srv.cs.cmu.edu/pipermail/connectionists/2014-July/027158.html
- https://en.wikipedia.org/wiki/Alexey_Ivakhnenko
- https://www.abebooks.com/Perceptrons-Introduction-Computational-Geometry-Marvin-Minsky/30050854532/bd
- http://people.idsia.ch/~juergen/linnainmaa1970thesis.pdf
- http://personalpage.flsi.or.jp/fukushima/index-e.html
- https://en.wikipedia.org/wiki/Convolutional_neural_network#History
- https://bulletin.swarthmore.edu/bulletin-issue-archive/index.html%3Fp=336.html
- https://en.wikipedia.org/wiki/Hopfield_network
- http://www.iro.umontreal.ca/~vincentp/ift3395/lectures/backprop_old.pdf
- http://www.andreykurenkov.com/writing/ai/a-brief-history-of-neural-nets-and-deep-learning/
- http://www.cs.toronto.edu/~hinton/absps/cogscibm.pdf
- http://www.scholarpedia.org/article/Boltzmann_machine
- https://medium.com/@tanaykarmarkar/explainable-restricted-boltzmann-machine-for-collaborative-filtering-6f011035352d
- https://link.springer.com/article/10.1007%2FBF02551274
- https://en.wikipedia.org/wiki/Universal_approximation_theorem#
- https://en.wikipedia.org/wiki/J%C3%BCrgen_Schmidhuber
- https://en.wikipedia.org/wiki/Sepp_Hochreiter
- http://people.idsia.ch/~juergen/
- https://slideslive.com/38906590/deep-learning-is-revolutionizing-artificial-intelligence
- http://www.cs.toronto.edu/~hinton/absps/fastnc.pdf
- https://en.wikipedia.org/wiki/Deep_belief_network
- https://www.quora.com/What-does-Andrew-Ng-think-about-Deep-Learning
- https://qz.com/1307091/the-inside-story-of-how-ai-got-good-enough-to-dominate-silicon-valley/
- https://en.wikipedia.org/wiki/AlexNethttps://papers.nips.cc/paper/5423-generative-adversarial-nets.pdfhttp://proceedings.mlr.press/v15/glorot11a/glorot11a.pdf


