
Introduction
In this tutorial, we will go through PyTorch optimizers which are used to reduce the error rate while training the neural networks. We will first understand what is optimization and then we will see different types of optimizers in PyTorch with their syntax and examples of usage.
What is Optimization?
During neural network training, its weights are randomly initialized initially and then they are updated in each epoch in a manner such that they increase the overall accuracy of the network.
In each epoch, the output of the training data is compared to actual data with the help of the loss function to calculate the error and then the weight is updated accordingly But how do we know how to update the weight such that it increases the accuracy? This is actually a problem of optimization where the goal is to optimize the loss function and get the ideal weights. And the method used for optimization is called Optimizer.
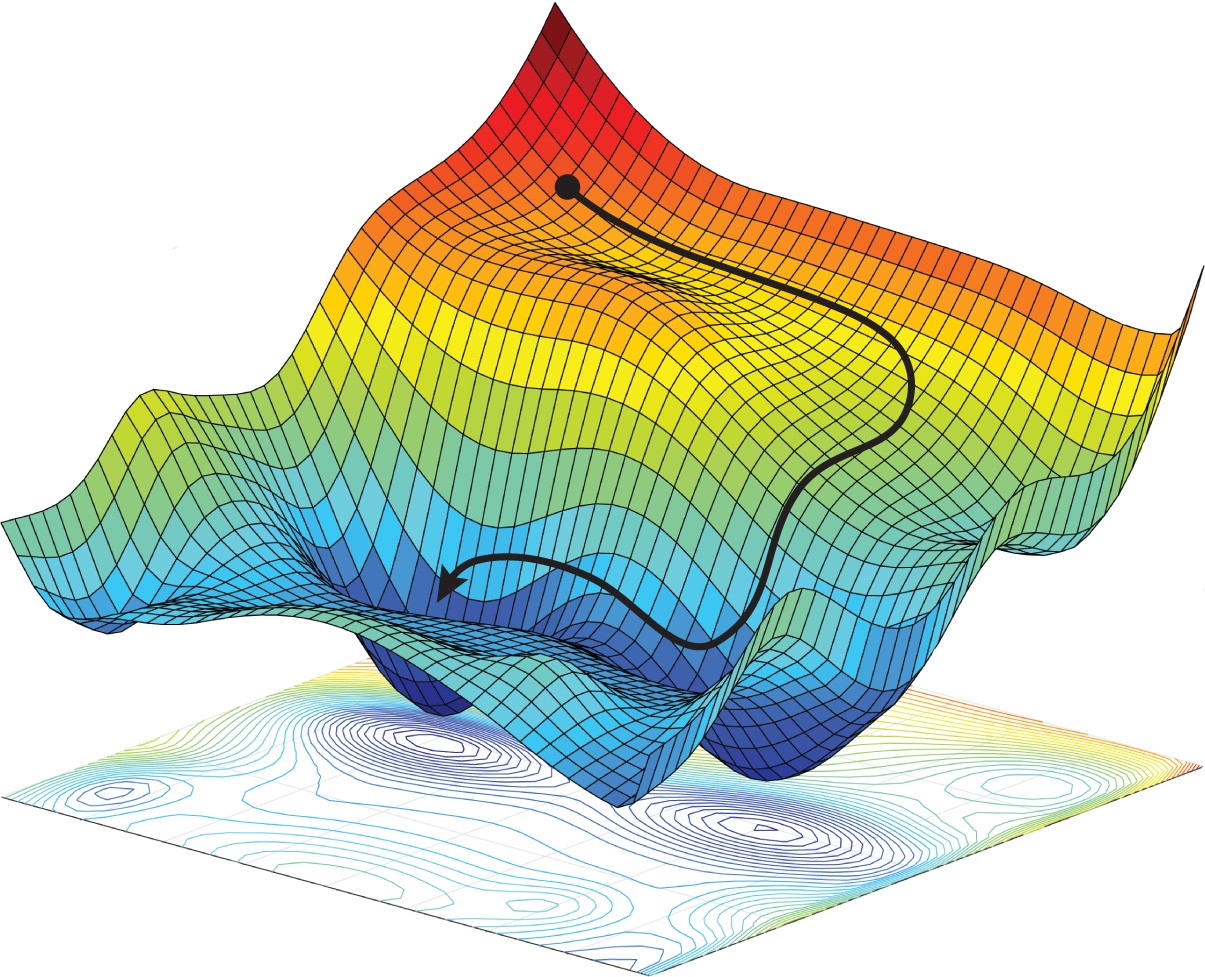
- Also Read – Dummies guide to Loss Functions in Machine Learning [with Animation]
- Also Read – Optimization in Machine Learning – Gentle Introduction for Beginner
Gradient Descent is the most commonly known optimizer but for practical purposes, there are many other optimizers. You will find many of these Optimizers in PyTorch library as well.
Types of PyTorch Optimizers
In this PyTorch optimizer tutorial, we will cover the following optimizers –
- SGD
- Adam
- Adadelta
- Adagrad
- AdamW
- Adamax
- RMSProp
1. SGD Optimizer
The SGD or Stochastic Gradient Optimizer is an optimizer in which the weights are updated for each training sample or a small subset of data.
Syntax
The following shows the syntax of the SGD optimizer in PyTorch.
torch.optim.SGD(params, lr=<required parameter>, momentum=0, dampening=0, weight_decay=0, nesterov=False)
Parameters
- params (iterable) — These are the parameters that help in the optimization.
- lr (float) — This parameter is the learning rate
- momentum (float, optional) — Here we pass the momentum factor
- weight_decay (float, optional) — This argument is containing the weight decay
- dampening (float, optional) — To dampen the momentum, we use this parameter
Example of PyTorch SGD Optimizer
In the below example, we will generate random data and train a linear model to show how we can use the SGD optimizer in PyTorch.
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
# Let's make some data for a linear regression.
A = 5.1213945
b = 3.2047893
error = 0.1
N = 100 # number of data points
# Data
X = Variable(torch.randn(N, 1))
# (noisy) Target values that we want to learn.
t = A * X + b + Variable(torch.randn(N, 1) * error)
# Creating a model, making the SGD optimizer, defining loss
model = nn.Linear(1, 1)
optimizer = optim.SGD(model.parameters(), lr=0.05)
loss_fn = nn.MSELoss()
# Run training
niter = 10
for _ in range(0, niter):
optimizer.zero_grad()
predictions = model(X)
loss = loss_fn(predictions, t)
loss.backward()
optimizer.step()
print("-" * 10)
#print("error = {}".format(loss.data[0]))
print("learned A = {}".format(list(model.parameters())[0].data[0, 0]))
print("learned b = {}".format(list(model.parameters())[1].data[0]))
---------- learned A = 0.7186790704727173 learned b = 1.0296704769134521 ---------- learned A = 1.109492540359497 learned b = 1.1512773036956787 ---------- learned A = 1.4640446901321411 learned b = 1.2692015171051025 ---------- learned A = 1.7858648300170898 learned b = 1.38302481174469 ---------- learned A = 2.0781219005584717 learned b = 1.4924471378326416 ---------- learned A = 2.343663215637207 learned b = 1.5972672700881958 ---------- learned A = 2.585047721862793 learned b = 1.6973659992218018 ---------- learned A = 2.804577589035034 learned b = 1.7926912307739258 ---------- learned A = 3.0043246746063232 learned b = 1.8832463026046753 ---------- learned A = 3.18615460395813 learned b = 1.9690791368484497
2. Adam Optimizer
Adam Optimizer uses both momentum and adaptive learning rate for better convergence. This is one of the most widely used optimizer for practical purposes for training neural networks.
Syntax
The following shows the syntax of the Adam optimizer in PyTorch.
torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)
Parameters
- params (Union[Iterable[Tensor], Iterable[Dict[str, Any]]]) – These are the iterable parameters that help in optimization
- lr (float) – Learning rate helping optimization (default: 1e-3)
- betas (Tuple[float, float]) – This parameter is used for calculating and running the averages for gradient (default: (0.9, 0.999))
- beta3 (float) – Smoothing coefficient (default: 0.9999)
- eps (float) – For improving the numerical stability (default: 1e-8)
- weight_decay (float) – For adding the weight decay (L2 penalty) (default: 0)
Example of Pytorch Adam Optimizer
In the below example, we will generate random data and train a linear model to show how we can use the Adam optimizer in PyTorch.
A = 2.4785692
b = 7.3256987
error = 0.1
N = 100 # number of data points
# Data
X = Variable(torch.randn(N, 1))
# (noisy) Target values that we want to learn.
t = A * X + b + Variable(torch.randn(N, 1) * error)
# Creating a model, making the optimizer, defining loss
model = nn.Linear(1, 1)
optimizer = optim.Adam(model.parameters(), lr=0.05)
loss_fn = nn.MSELoss()
# Run training
niter = 10
for _ in range(0, niter):
optimizer.zero_grad()
predictions = model(X)
loss = loss_fn(predictions, t)
loss.backward()
optimizer.step()
print("-" * 10)
print("learned A = {}".format(list(model.parameters())[0].data[0, 0]))
print("learned b = {}".format(list(model.parameters())[1].data[0]))
---------- learned A = -0.17196281254291534 learned b = -0.37717658281326294 ---------- learned A = -0.12198808789253235 learned b = -0.32718542218208313 ---------- learned A = -0.07205606997013092 learned b = -0.2772090435028076 ---------- learned A = -0.022184573113918304 learned b = -0.22725342214107513 ---------- learned A = 0.0276082344353199 learned b = -0.17732453346252441 ---------- learned A = 0.07730387151241302 learned b = -0.12742836773395538 ---------- learned A = 0.12688355147838593 learned b = -0.07757088541984558 ---------- learned A = 0.17632828652858734 learned b = -0.027758032083511353 ---------- learned A = 0.2256188839673996 learned b = 0.022004306316375732 ---------- learned A = 0.2747359871864319 learned b = 0.07171027362346649
3. Adagrad Optimizer
Adaptive Gradient Algorithm (Adagrad) is an algorithm for gradient-based optimization where each parameter has its own learning rate that improves performance on problems with sparse gradients.
Syntax
The following shows the syntax of the Adagrad optimizer in PyTorch.
torch.optim.Adagrad(params, lr=0.01, lr_decay=0, weight_decay=0, initial_accumulator_value=0, eps=1e-10)
Parameters
- params (Union[Iterable[Tensor], Iterable[Dict[str, Any]]]) – These are the iterable parameters that help in optimization
- lr (float) – Learning rate helping optimization (default: 1e-3)
- lr_decay (float, optional) – learning rate decay (default: 0)
- eps (float) – For improving the numerical stability (default: 1e-8)
- weight_decay (float) – For adding the weight decay (L2 penalty) (default: 0)
Example of PyTorch Adagrad Optimizer
In the below example, we will generate random data and train a linear model to show how we can use the Adagrad optimizer in PyTorch.
A = 9.2478
b = 6.7325
error = 0.1
N = 100 # number of data points
# Data
X = Variable(torch.randn(N, 1))
# (noisy) Target values that we want to learn.
t = A * X + b + Variable(torch.randn(N, 1) * error)
# Creating a model, making the optimizer, defining loss
model = nn.Linear(1, 1)
optimizer = optim.Adagrad(model.parameters(), lr=0.05)
loss_fn = nn.MSELoss()
# Run training
niter = 10
for _ in range(0, niter):
optimizer.zero_grad()
predictions = model(X)
loss = loss_fn(predictions, t)
loss.backward()
optimizer.step()
print("-" * 10)
print("learned A = {}".format(list(model.parameters())[0].data[0, 0]))
print("learned b = {}".format(list(model.parameters())[1].data[0]))
---------- learned A = -0.836931049823761 learned b = 0.016164232045412064 ---------- learned A = -0.8016587495803833 learned b = 0.051380738615989685 ---------- learned A = -0.7729004621505737 learned b = 0.08006558567285538 ---------- learned A = -0.7480223774909973 learned b = 0.1048615574836731 ---------- learned A = -0.7257911562919617 learned b = 0.12700554728507996 ---------- learned A = -0.7055131793022156 learned b = 0.14719286561012268 ---------- learned A = -0.6867529153823853 learned b = 0.16585998237133026 ---------- learned A = -0.6692158579826355 learned b = 0.18330201506614685 ---------- learned A = -0.6526918411254883 learned b = 0.19972950220108032 ---------- learned A = -0.6370247602462769 learned b = 0.2152988314628601
4. Adadelta Optimizer
Adadelta is an extension of the Adagrad optimizer which adapts learning rate based on a moving window of gradient updates instead of accumulating all previous gradients.
Syntax
torch.optim.Adadelta(params, lr=1.0, rho=0.9, eps=1e-06, weight_decay=0)
Parameters
- params (Union[Iterable[Tensor], Iterable[Dict[str, Any]]]) – These are the iterable parameters that help in optimization
- lr (float) – Learning rate helping optimization (default: 1e-3)
- betas (Tuple[float, float]) – This parameter is used for calculating and running the averages for gradient (default: (0.9, 0.999))
- beta3 (float) – Smoothing coefficient (default: 0.9999)
- eps (float) – For improving the numerical stability (default: 1e-8)
- weight_decay (float) – For adding the weight decay (L2 penalty) (default: 0)
Example of PyTorch Adadelta Optimizer
In the below example, we will generate random data and train a linear model to show how we can use the Adadelta optimizer in PyTorch.
A = 5.5692478
b = 4.6987325
error = 0.1
N = 100 # number of data points
# Data
X = Variable(torch.randn(N, 1))
# (noisy) Target values that we want to learn.
t = A * X + b + Variable(torch.randn(N, 1) * error)
# Creating a model, making the optimizer, defining loss
model = nn.Linear(1, 1)
optimizer = optim.Adadelta(model.parameters(), lr=0.05)
loss_fn = nn.MSELoss()
# Run training
niter = 10
for _ in range(0, niter):
optimizer.zero_grad()
predictions = model(X)
loss = loss_fn(predictions, t)
loss.backward()
optimizer.step()
print("-" * 10)
print("learned A = {}".format(list(model.parameters())[0].data[0, 0]))
print("learned b = {}".format(list(model.parameters())[1].data[0]))
---------- learned A = 0.4119051992893219 learned b = 0.6083362698554993 ---------- learned A = 0.4120674133300781 learned b = 0.6084985136985779 ---------- learned A = 0.4122324585914612 learned b = 0.6086635589599609 ---------- learned A = 0.41239967942237854 learned b = 0.6088307499885559 ---------- learned A = 0.41256871819496155 learned b = 0.6089997887611389 ---------- learned A = 0.4127393066883087 learned b = 0.6091703772544861 ---------- learned A = 0.4129112958908081 learned b = 0.6093423366546631 ---------- learned A = 0.41308456659317017 learned b = 0.6095156073570251 ---------- learned A = 0.41325899958610535 learned b = 0.6096900105476379 ---------- learned A = 0.4134345054626465 learned b = 0.6098655462265015
5. AdamW Optimizer
AdamW optimizer is a variation of Adam optimizer that performs the optimization of both weight decay and learning rate separately. It is supposed to converge faster than Adam in certain scenarios.
Syntax
torch.optim.AdamW(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0.01, amsgrad=False)
Parameters
- params (Union[Iterable[Tensor], Iterable[Dict[str, Any]]]) – These are the iterable parameters that help in optimization
- lr (float) – Learning rate helping optimization (default: 1e-3)
- betas (Tuple[float, float], optional) – It helps in calculation of averages for the gradient squares (default: (0.9, 0.999))
- eps (float) – For improving the numerical stability (default: 1e-8)
- weight_decay (float) – For adding the weight decay (L2 penalty) (default: 0)
- amsgrad (boolean, optional) – This parameter helps in deciding whether AMSgrad algorithm will be used or not(default: False)
Example of PyTorch AdamW Optimizer
In the below example, we will generate random data and train a linear model to show how we can use the AdamW optimizer in PyTorch.
A = 4.785237
b = 9.136489
error = 0.1
N = 100 # number of data points
# Data
X = Variable(torch.randn(N, 1))
# (noisy) Target values that we want to learn.
t = A * X + b + Variable(torch.randn(N, 1) * error)
# Creating a model, making the optimizer, defining loss
model = nn.Linear(1, 1)
optimizer = optim.AdamW(model.parameters(), lr=0.05)
loss_fn = nn.MSELoss()
# Run training
niter = 10
for _ in range(0, niter):
optimizer.zero_grad()
predictions = model(X)
loss = loss_fn(predictions, t)
loss.backward()
optimizer.step()
print("-" * 10)
print("learned A = {}".format(list(model.parameters())[0].data[0, 0]))
print("learned b = {}".format(list(model.parameters())[1].data[0]))
---------- learned A = 0.31510043144226074 learned b = 0.04932275414466858 ---------- learned A = 0.3649296164512634 learned b = 0.09929023683071136 ---------- learned A = 0.4147116541862488 learned b = 0.1492196023464203 ---------- learned A = 0.4644375741481781 learned b = 0.19910559058189392 ---------- learned A = 0.5140982866287231 learned b = 0.24894294142723083 ---------- learned A = 0.5636847019195557 learned b = 0.2987263798713684 ---------- learned A = 0.6131876707077026 learned b = 0.3484507203102112 ---------- learned A = 0.662598192691803 learned b = 0.3981107473373413 ---------- learned A = 0.7119070887565613 learned b = 0.4477013051509857 ---------- learned A = 0.761105477809906 learned b = 0.4972173571586609
6. Adamax
Adamax optimizer is a variant of Adam optimizer that uses infinity norm. Though it is not used widely in practical work some research shows Adamax results are better than Adam optimizer.
Syntax
torch.optim.Adamax(params, lr=0.002, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)
Parameters
- params (Union[Iterable[Tensor], Iterable[Dict[str, Any]]]) – These are the iterable parameters that help in optimization
- lr (float) – Learning rate helping optimization (default: 1e-3)
- betas (Tuple[float, float], optional) – It helps in calculation of averages for the gradient squares (default: (0.9, 0.999))
- eps (float) – For improving the numerical stability (default: 1e-8)
- weight_decay (float) – For adding the weight decay (L2 penalty) (default: 0)
Example of PyTorch Adamax Optimizer
In the below example, we will generate random data and train a linear model to show how we can use the Adamax optimizer in PyTorch.
A = 6.5692478
b = 3.6987325
error = 0.1
N = 100 # number of data points
# Data
X = Variable(torch.randn(N, 1))
# (noisy) Target values that we want to learn.
t = A * X + b + Variable(torch.randn(N, 1) * error)
# Creating a model, making the optimizer, defining loss
model = nn.Linear(1, 1)
optimizer = optim.Adamax(model.parameters(), lr=0.05)
loss_fn = nn.MSELoss()
# Run training
niter = 10
for _ in range(0, niter):
optimizer.zero_grad()
predictions = model(X)
loss = loss_fn(predictions, t)
loss.backward()
optimizer.step()
print("-" * 10)
print("learned A = {}".format(list(model.parameters())[0].data[0, 0]))
print("learned b = {}".format(list(model.parameters())[1].data[0]))
---------- learned A = 0.8950639367103577 learned b = 0.18595246970653534 ---------- learned A = 0.9448832273483276 learned b = 0.23563465476036072 ---------- learned A = 0.9945142865180969 learned b = 0.28498774766921997 ---------- learned A = 1.0439497232437134 learned b = 0.33400067687034607 ---------- learned A = 1.0931823253631592 learned b = 0.3826625645160675 ---------- learned A = 1.142204761505127 learned b = 0.43096283078193665 ---------- learned A = 1.1910099983215332 learned b = 0.47889119386672974 ---------- learned A = 1.2395912408828735 learned b = 0.5264376997947693 ---------- learned A = 1.2879416942596436 learned b = 0.5735926628112793 ---------- learned A = 1.3360549211502075 learned b = 0.6203468441963196
7. RMSProp
RMSProp applies stochastic gradient with mini-batch and uses adaptive learning rates which means it adjusts the learning rates over time.
Syntax
torch.optim.RMSprop(params, lr=0.01, alpha=0.99, eps=1e-08, weight_decay=0, momentum=0, centered=False)
Parameters
- params (Union[Iterable[Tensor], Iterable[Dict[str, Any]]]) – These are the iterable parameters that help in optimization
- lr (float) – Learning rate helping optimization (default: 1e-3)
- betas (Tuple[float, float], optional) – It helps in calculation of averages for the gradient squares (default: (0.9, 0.999))
- eps (float) – For improving the numerical stability (default: 1e-8)
- momentum (float, optional) – momentum factor (default: 0)
- alpha (float, optional) – smoothing constant (default: 0.99)
- centered (bool, optional) – if True, compute the centered RMSProp, the gradient is normalized by an estimation of its variance
- weight_decay (float) – For adding the weight decay (L2 penalty) (default: 0)
Example of PyTorch RMSProp Optimizer
In the below example, we will generate random data and train a linear model to show how we can use the RMSProp optimizer in PyTorch.
A = 2.1234567
b = 7.5625896
error = 0.1
N = 100 # number of data points
# Data
X = Variable(torch.randn(N, 1))
# (noisy) Target values that we want to learn.
t = A * X + b + Variable(torch.randn(N, 1) * error)
# Creating a model, making the optimizer, defining loss
model = nn.Linear(1, 1)
optimizer = optim.RMSprop(model.parameters(), lr=0.05)
loss_fn = nn.MSELoss()
# Run training
niter = 10
for _ in range(0, niter):
optimizer.zero_grad()
predictions = model(X)
loss = loss_fn(predictions, t)
loss.backward()
optimizer.step()
print("-" * 10)
print("learned A = {}".format(list(model.parameters())[0].data[0, 0]))
print("learned b = {}".format(list(model.parameters())[1].data[0]))
---------- learned A = -0.11640959978103638 learned b = -0.11571937799453735 ---------- learned A = 0.20982813835144043 learned b = 0.22625604271888733 ---------- learned A = 0.46188482642173767 learned b = 0.49985402822494507 ---------- learned A = 0.67011958360672 learned b = 0.7331075668334961 ---------- learned A = 0.8484358787536621 learned b = 0.9389881491661072 ---------- learned A = 1.0045568943023682 learned b = 1.1247366666793823 ---------- learned A = 1.1432981491088867 learned b = 1.294876217842102 ---------- learned A = 1.2679041624069214 learned b = 1.4524540901184082 ---------- learned A = 1.3806874752044678 learned b = 1.5996379852294922 ---------- learned A = 1.483367919921875 learned b = 1.7380346059799194
Conclusion
We have reached the conclusion of this tutorial where we learned about different types of PyTorch optimizers, their syntaxes, and examples of usage.
Reference – PyTorch Documentation

