
Introduction
In recent years the research in object detection models has attracted a lot of attention due to the boom in the computer vision market. To interpret an image or a video the computer has to first detect the objects and also precisely estimate their location in the image/video before classifying them. Object detection consists of several subtasks like face detection, pedestrian detection, skeleton detection, etc, and has popular use cases such as surveillance systems, self-driving cars. In this article, we will go through few different types of object detection algorithms that are popular nowadays.
There are various types of object detection algorithms, some are traditional techniques and some are modern techniques developed recently. These architectures differ from each other based on its accuracy, speed, and hardware resources required.

Object Detection Approaches
Before going through different types of object detection algorithms, it will be good if we understand how the old traditional techniques used to work and why the modern approaches, which we will discuss in this post, are so better. This will help you to appreciate the current state of art object detection algorithms better.
Traditional Approach
The traditional approach of object detection usually has three stages: i) informative region selection, ii) feature extraction, and iii) classification of the object.
- In the first stage, we try to find the object’s location. Objects have a different size and aspect ratio and may appear at different locations of an image. Due to this, we have to scan the whole image using a multiscale sliding window. But this method is computationally expensive and it produces many irrelevant candidates.
- In the second step, we do the feature extraction stage by using techniques like SIFT, HOG to extract the visual feature for recognizing the object. These visual features provide a semantic and robust representation. However, due to different illuminations conditions, viewpoint differences, and different backgrounds it is very difficult to manually design a robust feature descriptor to perfectly describe all types of objects.
- In the third classification stage we use Support Vector Machine(SVM) or Adaboost for the classification of target objects from all the other categories and to make the representations more hierarchical, semantic, and informative for visual recognition.
The problem with the traditional approach is that the generation of candidate bounding boxes using the sliding window technique is computationally expensive and also the hand-engineered features are not always sufficient to perfectly describe all types of objects.
Modern Approaches
The emergence of deep learning is able to tackle some drawbacks of traditional approaches. The deep learning architectures are able to learn more complex features as we have seen already in image classification tutorials.
In this article, we will focus on different deep learning based object detection models. There are two types of frameworks available in deep learning object detection models. The first framework is region proposal based and it consists of models like RCNN, SPP-NET, FRCNN, FasterRCNN and the second framework is regression-based and consists of MultiBox, AttentionNet, G-CNN, YOLO, SSD, YOLOV2.

In this article, we will only go through these modern object detection algorithms.
The Region proposal based framework
1) R-CNN
R-CNN was proposed by Ross Girshick in 2014 and obtained a mean average precision (mAP) of 53.3% with more than 30% improvement over the previous best result on PASCAL VOC 2012. It improves the quality of candidate bounding boxes and uses deep architecture to extract high-level features.
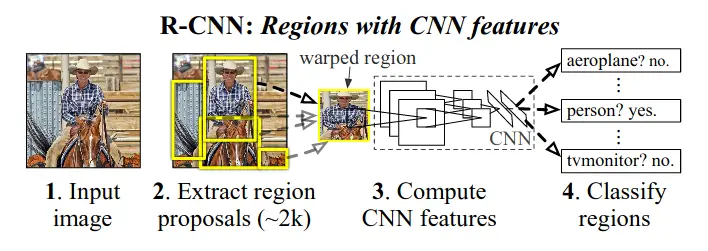
As we see in the above figure that RCNN architecture is divided into three stages –
- Regional Proposal Generation: RCNN uses selective search to generate 2k proposal for each image
- Feature Extraction: In this step, each region proposal is cropped into fixed resolution and a standard CNN model is used to extract a 4096-dimensional feature as a final representation. This feature has a robust high-level semantic representation for each region’s proposals.
- Classification and localization: The extracted features are fed into an SVM to classify the presence of the object within that candidate region proposal. In addition to predicting the presence of an object within the region proposals, the algorithm also predicts four values which are offset values to increase the precision of the bounding box.
Limitations:
- Training of R-CNN is a multi-stage process: i) At first, a convolutional network (ConvNet) on object proposals is fine-tuned. ii) After that, the softmax classifier learned by fine-tuning is replaced by SVMs to fit in with ConvNet features. iii) Finally, bounding-box regressors are trained.
- Features are extracted from different region proposals and stored on the disk. It will take a long time to process a relatively small training set with very deep networks, such as VGG16. Because of this, training is expensive in space as well as time-consuming.
- In this model, a selective search is used to generate regional proposals. This technique of generating regional proposals generates redundant proposals and also this process has very high time complexity. (around 2 seconds to extract 2k region proposals)
- Due to the existence of FC layers, CNN requires a fixed-size input image which leads to the re-computation of the whole CNN for each evaluated region of interest and hence taking a great deal of time in the testing period
2) SPP-Net
In RCNN, due to the existence of FC layers, CNN requires a fixed size input, and due to this RCNN crops each region proposal into the same size. It may happen that objects may partially appear in the wrapped region and also unwanted geometric distortion may be produced due to wrapping operation. These content losses or distortions will reduce recognition accuracy, especially when the scales of objects vary.
To tackle this problem, researchers came up with a new model SPP-Net by considering the theory behind spatial pyramid matching (SPM). SPPNet has got 1st Runner Up in Object Detection, 2nd Runner Up in Image Classification, and 5th Place in Localization Task.
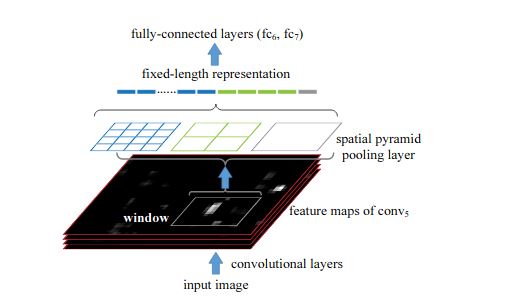
SPP-net is different from RCNN in such a way that SPP-net reuses feature maps of the 5th conv layer (conv5) to project region proposals of arbitrary sizes to fixed-length feature vectors. The layer after the final conv layer is referred to as the spatial pyramid pooling layer (SPP layer). If the number of feature maps in conv5 is 256, taking a 3-level pyramid, the final feature vector for each region proposal obtained after the SPP layer has a dimension of 256×(1^2+2^2+4^2) = 5376.
Advantages
SPP-net has achieved better results with a correct estimation of different region proposals in their corresponding scales, and also improves detection efficiency in testing periods with the sharing of computation cost before the SPP layer among different proposals.
Limitations
Although SPP-net has achieved impressive improvements in both accuracy and efficiency over R-CNN, it still has some notable drawbacks of being a multi-stage pipeline like R-CNN. This is because it also includes feature extraction, network fine-tuning, SVM training, and bounding-box regressor fitting. So an additional expense on storage space is still required and is also time-consuming.
3) Fast R-CNN
To tackle the above problems, Girshick introduced a multi-task loss on classification and bounding box regression by proposing a novel CNN architecture named Fast R-CNN.
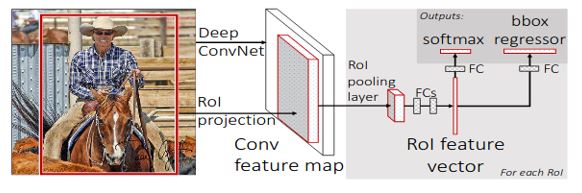
In Fast R-CNN, firstly the whole image is processed with standard convolution architecture like VGG16 to produce a feature map, this step is similar to SPP-Net and after that, a fixed-length feature vector is extracted from each region proposal with a region of interest (RoI) pooling layer.
The important point here is to note that the RoI pooling layer is a special case of the SPP layer, which has only one pyramid level.
After that, each feature vector is then fed into a sequence of FC layers before finally branching into two output layers.
One output layer is responsible for producing softmax probabilities for all C+ 1 categories (C object classes plus one ‘background’ class)
The other output layer encodes refined bounding-box positions with four real-valued numbers.
All parameters in these procedures (except the generation of region proposals) are optimized via a multi-task loss in an end-to-end way. The multi-tasks loss is defined as below to jointly train classification and bounding-box regression.
Advantages
- In the Fast R-CNN, the training of all network layers can be processed in a single-stage with a multi-task loss except for region proposal generation. It saves the additional expense on storage space and improves both accuracy and efficiency
- The “Fast R-CNN” is faster than R-CNN is because in R-CNN 2000 region proposals are fed to the convolutional neural network every time but in Fast-RCNN the convolution operation is done only once per image and a feature map is generated from it.
Disadvantages
Similar to RCNN, Fast-RCNN uses selective search to find out the region’s proposals. We know that Selective search is a slow and time-consuming process and hence affecting the performance of the network. So that’s why region proposal computation is also a bottleneck here in improving efficiency.
4) Faster R-CNN
To solve this problem, Ren et al. introduced an additional Region Proposal Network(RPN), which acts in a nearly cost-free way by sharing full-image conv features with detection networks i.e instead of using a selective search algorithm on the feature map to identify the region proposals, a separate network is used to predict the region proposals.
RPN is achieved with a fully convolutional network, which has the ability to predict object bounds and scores at each position simultaneously.
RPN takes an image of arbitrary size to generate a set of rectangular object proposals. The important point here is to note that RPN operates on a specific conv layer with the preceding layers shared with the object detection network. In other words, to generate “proposals” for the region where the object lies, a small network is slide over a convolutional feature map that is the output by the last convolutional layer.
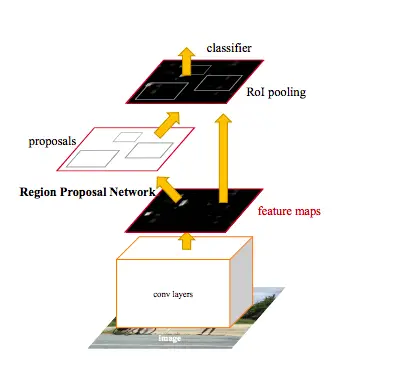
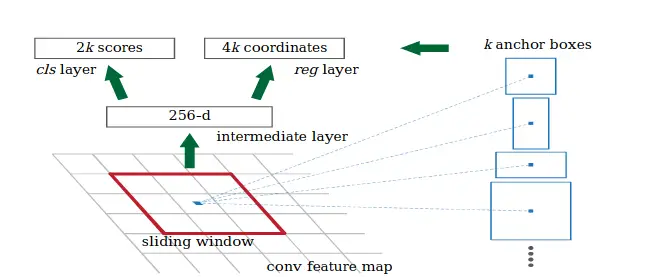
In RPN, K anchor boxes are convoluted with each sliding window to produce fixed-length vectors that are taken by the class layer and regressor layer to obtain the corresponding output.
The network slides over the conv feature map and fully connects to an n* n spatial window. A low dimensional vector is obtained in each sliding window and fed into two FC layers, namely box-classification layer (cls) and box-regression layer (reg). To increase non-linearity, ReLU is applied to the output of the n *n conv layer.
Advantages
With the proposal of Faster R-CNN, region proposal based CNN architectures for object detection can really be trained in an end-to-end way. Also, a frame rate of 5 FPS (FramePer Second) on a GPU is achieved with state-of-the-art object detection accuracy on PASCAL VOC 2007 and 2012. However, the alternate training algorithm is very time-consuming and RPN produces object-like regions (including backgrounds) instead of object instances and is not skilled in dealing with objects with extreme scales or shapes.
Regression/Classification Based Framework
As we saw above that region proposal based frameworks are time-consuming and may not be suitable for real-time applications. One-step frameworks based on global regression/classification maps straightly from image pixels to bounding box coordinates and class probabilities can reduce time expense. These are really good for real-time object detection. Let us understand two of its most popular types of object detection algorithms.
5) YOLO (You Only Look Once)
All of the previous object detection algorithms use regions to localize the object within the image. The network does not look at the complete image, instead, it looks at parts of the image which have high probabilities of containing the object. YOLO or You Only Look Once, proposed by Redmon et al. is a novel object detection algorithm much different from the region based algorithms seen above. In YOLO a single convolutional network predicts the bounding boxes and the class probabilities for these boxes.
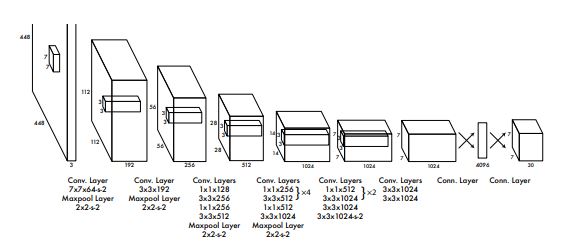
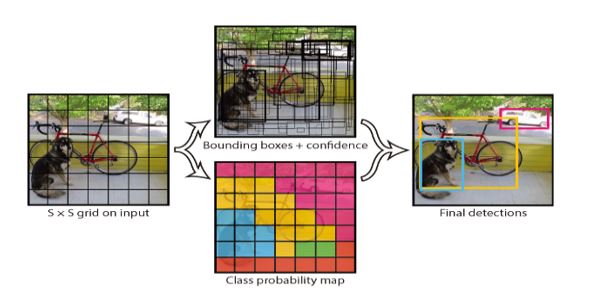
YOLO makes use of the whole topmost feature map to predict both confidences for multiple categories and bounding boxes. YOLO divides the input image into an S×S grid and each grid cell is responsible for predicting the object centered in that grid cell. Each grid cell predicts bounding boxes and their corresponding confidence scores.
YOLO was the original algorithm but now improved versions of YOLOv4 and YOLOv5 have come up recently.
- Also Read – YOLOv4 Object Detection Tutorial with Image and Video : A Beginners Guide
- Also Read – YOLOv5 Object Detection with Tutorial
Limitation
- Since object detection takes place in one step only, hence it is fast compared to R-CNN family of algorithms, but sometimes shows lesser accuracy.
- YOLO has difficulty in dealing with small objects in groups, which is caused by strong spatial constraints imposed on bounding box predictions.
- YOLO also struggles to generalize to objects in new/unusual aspect ratios/configurations and produces relatively coarse features due to multiple downsampling operations.
6) SSD – Single Shot Detector
To avoid some of the limitations of YOLO, Liu et al. proposed a Single Shot MultiBox Detector (SSD), which was inspired by the anchors adopted in MultiBox, RPN, and multi-scale representation. Given a specific feature map, instead of fixed grids adopted in YOLO, the SSD takes advantage of a set of default anchor boxes with different aspect ratios and scales to discretize the output space of bounding boxes. To handle objects of various sizes, the network fuses predictions from multiple feature maps with different resolutions.
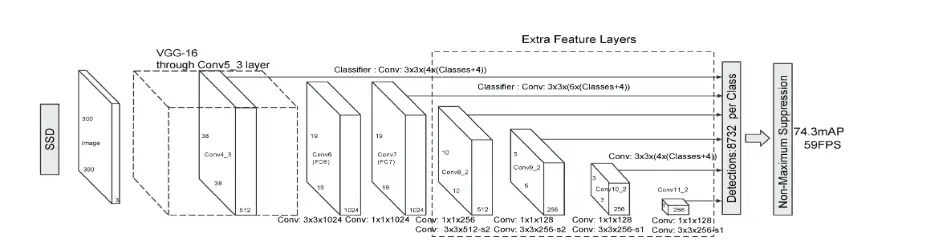
Limitation
- Just like YOLO, Single Shot Detector is fast but this comes at the cost of accuracy.
Conclusion
In this article, we touched upon the traditional and modern approaches of object detection techniques. Then we covered different types of object detection algorithms under the modern approaches which are quite popular today. Hope you found this nutshell view of object detection algorithms useful.
- Also Read – 14 Computer Vision Applications Beginners Should Know
- Also Read – 13 Cool Computer Vision GitHub Projects To Inspire You
References –
- R-CNN – https://arxiv.org/abs/1311.2524
- SPP Net – https://arxiv.org/abs/1406.4729
- Fast – RCNN – https://arxiv.org/abs/1504.08083
- Faster-RCNN – https://arxiv.org/abs/1506.01497
- YOLO – https://arxiv.org/abs/1506.02640
- SSD – https://arxiv.org/abs/1512.02325

