
Introduction
In this article, we will explain to you a very useful module of Sklearn – GridSearchCV. We will first understand what is GridSearchCV and what is its benefit. Then we will take you through some various examples of GridSearchCV for algorithms like Logistic Regression, KNN, Random Forest, and SVM. Finally, we will also discuss RandomizedSearchCV along with an example.
What is GridSearchCV?
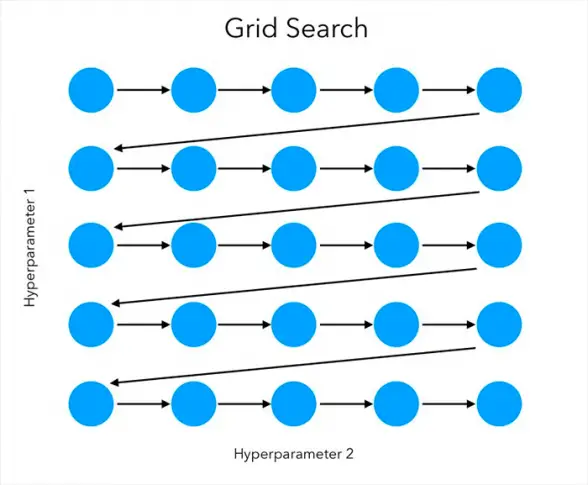
GridSearchCV is a module of the Sklearn model_selection package that is used for Hyperparameter tuning. Given a set of different hyperparameters, GridSearchCV loops through all possible values and combinations of the hyperparameter and fits the model on the training dataset. In this process, it is able to identify the best values and combination of hyperparameters (from the given set) that produces the best accuracy.
Why do we need GridSearchCV?
Normally, what we do is that we select hyperparameters based on intuition or by experience, or even by just wild guessing.
Usually, at first, we would be supplying values of hyperparameters of ML algorithm just by intuition, or a calculated guess. If the accuracy is not good, we then try other values and combinations of hyperparameters manually. But this manual process can be quite a time-consuming thing and you may not even be able to cover all combinations or leave it midway.
This is where Sklearn GridsearchCV can be very useful to automate this manual work. You can supply the list of different hyperparameters and it will do the heavy lifting for you and returns the best hyperparameter combinations and model as output.
How does GridSearchCV work?
We pass a range set of values for hyperparameters into the GridSearchCV function as a dictionary. For example in SVM (Support Vector Machines) the hyperparameters are supplied as –
{ ‘C’: [0.1, 1, 10, 100], ‘gamma’: [1, 0.1, 0.01, 0.001, 0.0001], ‘kernel’:[‘rbf’,’linear’,’poly’]}
Here C, gamma, and kernel are the possible hyperparameters of the SVM model.
The hyperparameters are set up in a discrete grid and then it uses every combination of the values in the grid, evaluating the performance using cross-validation. The point of the grid that maximizes the average value in cross-validation, is the optimum combination of values for the hyperparameters.
Common Parameters of Sklearn GridSearchCV Function
- estimator: Here we pass in our model instance.
- params_grid: It is a dictionary object that holds the hyperparameters we wish to experiment with.
- scoring: evaluation metric that we want to implement.e.g Accuracy,Jaccard,F1macro,F1micro.
- cv: The total number of cross-validations we perform for each hyperparameter.
- verbose: Detailed print out of your fit of the data to GridSearchCV, mostly we set it to 1.
- n_jobs: number of processes you wish to run in parallel for this task if it is -1 it will use all available processors.
Examples of Sklearn GridSearchCV
We will use a bank customer churn dataset to show you examples of Sklearn GridSearchCV for the following algorithms –
- Logistic Regression
- KNN
- Random Forest
- SVM
About Our Dataset
The data set contains details of bank customer churn. Customer churn refers to when a customer ceases his or her relationship with a company. The goal is to create a machine learning model to predict whether a customer will leave the bank services or not. The dataset consists of 1000 rows and 14 columns in total
Importing Necessary Libraries
We first load the libraries required to build our models.
#import all necessary libraries
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score, plot_confusion_matrix
from sklearn.model_selection import GridSearchCV
Reading CSV File
Now we load the CSV file of the dataset into Pandas Dataframe.
df=pd.read_csv(r"Churn_Modelling.csv")
df.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 10000 entries, 0 to 9999 Data columns (total 14 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 RowNumber 10000 non-null int64 1 CustomerId 10000 non-null int64 2 Surname 10000 non-null object 3 CreditScore 10000 non-null int64 4 Geography 10000 non-null object 5 Gender 10000 non-null object 6 Age 10000 non-null int64 7 Tenure 10000 non-null int64 8 Balance 10000 non-null float64 9 NumOfProducts 10000 non-null int64 10 HasCrCard 10000 non-null int64 11 IsActiveMember 10000 non-null int64 12 EstimatedSalary 10000 non-null float64 13 Exited 10000 non-null int64 dtypes: float64(2), int64(9), object(3) memory usage: 1.1+ MB
We need to get rid of some extraneous features that we won’t be using in our predictions, thus we use the drop method to remove certain unnecessary columns.
df.drop(['RowNumber', 'CustomerId', 'Surname', 'Geography'], axis=1, inplace=True)
df.Gender = [1 if each == 'Male' else 0 for each in df.Gender]
df.head()
| CreditScore | Gender | Age | Tenure | Balance | NumOfProducts | HasCrCard | IsActiveMember | EstimatedSalary | Exited | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 619 | 0 | 42 | 2 | 0.00 | 1 | 1 | 1 | 101348.88 | 1 |
| 1 | 608 | 0 | 41 | 1 | 83807.86 | 1 | 0 | 1 | 112542.58 | 0 |
| 2 | 502 | 0 | 42 | 8 | 159660.80 | 3 | 1 | 0 | 113931.57 | 1 |
| 3 | 699 | 0 | 39 | 1 | 0.00 | 2 | 0 | 0 | 93826.63 | 0 |
| 4 | 850 | 0 | 43 | 2 | 125510.82 | 1 | 1 | 1 | 79084.10 |
Splitting dataset into Training and Testing Set
Next, we separate the independent predictor variables and the target variable into x and y. And then split both x and y into training and testing sets with the help of the train_test_split() function.
from sklearn.model_selection import train_test_split
x=df.drop('Exited', axis=1)
y = df['Exited']
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.20, random_state=7)
Logistic Regression with GridSearchCV
Now we will show you an example of using GridSearchCV with logistic regression.
# Grid search cross validation
from sklearn.linear_model import LogisticRegression
grid={"C":np.logspace(-3,3,20), "penalty":["l2"]}
logreg=LogisticRegression()
grid_logreg=GridSearchCV(logreg,grid,cv=10)
grid_logreg.fit(x_train,y_train)
print("tuned hpyerparameters :(best parameters) ",grid_logreg.best_params_)
print("accuracy :",grid_logreg.best_score_*100)
tuned hpyerparameters :(best parameters) {'C': 0.00206913808111479, 'penalty': 'l2'}
accuracy : 79.06249999999999
# make predictions on test data
grid_predictions = grid_logreg.predict(x_test)
test_accuracy=accuracy_score(y_test,grid_predictions)*100
print("Accuracy for our testing dataset with tuning is : {:.2f}%".format(test_accuracy) )
Accuracy for our testing dataset with tuning is : 78.85%
KNN with GridSearchCV
Next, we show you an example of using GridSearchCV with the KNN algorithm.
k_range = list(range(1, 31))
param_grid = dict(n_neighbors=k_range)
grid_knn = GridSearchCV(knn, param_grid, cv=5, scoring='accuracy', return_train_score=False)
grid_knn.fit(x_train,y_train)
print("tuned hyperparameters :(best parameters) ",grid_knn.best_params_)
print("accuracy :",grid_knn.best_score_*100)
tuned hyperparameters :(best parameters) {'n_neighbors': 30}
accuracy : 79.66250000000001
# make predictions on test data
grid_predictions = grid_knn.predict(x_test)
test_accuracy=accuracy_score(y_test,grid_predictions)*100
print("Accuracy for our testing dataset with tuning is : {:.2f}%".format(test_accuracy) )
Accuracy for our testing dataset with tuning is : 79.45%
Random Forest with GridSearchCV
Now we will show you an example of using GridSearchCV with Random Forest.
param_grid = {
'n_estimators': [200, 700],
'max_features': ['auto', 'sqrt', 'log2']
}
CV_rfc = GridSearchCV(estimator=rf,param_grid=param_grid, cv= 5,scoring='accuracy')
CV_rfc.fit(x_train, y_train)
print("tuned hyperparameters :(best parameters) ",CV_rfc.best_params_)
print("accuracy :",CV_rfc.best_score_*100)
tuned hyperparameters :(best parameters) {'max_features': 'log2', 'n_estimators': 700}
accuracy : 85.3
# make predictions on test data
grid_predictions = CV_rfc.predict(x_test)
test_accuracy=accuracy_score(y_test,grid_predictions)*100
print("Accuracy for our testing dataset with tuning is : {:.2f}%".format(test_accuracy) )
Accuracy for our testing dataset with tuning is : 84.90%
SVM with GridSearchCV
Finally, we have an example of using GridSearchCV with SVM.
# defining parameter range
param_grid = {'C': [0.1, 1, 10, 100, 1000],
'gamma': [1, 0.1, 0.01, 0.001, 0.0001],
'kernel': ['rbf']}
grid = GridSearchCV(svm, param_grid, refit = True, verbose =0,cv=5)
# fitting the model for grid search
grid.fit(x_train, y_train)
print("tuned hyperparameters :(best parameters) ",grid.best_params_)
print("accuracy :",grid.best_score_*100)
tuned hyperparameters :(best parameters) {'C': 0.1, 'gamma': 1, 'kernel': 'rbf'}
accuracy : 79.67500000000001
# make predictions on test data
grid_predictions = grid.predict(x_test)
test_accuracy=accuracy_score(y_test,grid_predictions)*100
print("Accuracy for our testing dataset with tuning is : {:.2f}%".format(test_accuracy) )
Accuracy for our testing dataset with tuning is : 79.55%
Limitations of Sklearn GridSearchCV
Although GridSearchCV serves as a lifesaver from doing manual permutation and combination of hyperparameters, it also has few disadvantages –
- It is as good as the set of hyperparameters provided by you as input. It does not magically search for all possible hyperparameters unless you give them as part of the input.
- To go through all combinations of hyperparameters GrisSearchCV can take too much computing resources.
Sklearn RandomizedSearchCV
When execution time is a high priority, one may struggle using GridSearchCV, since every parameter is tested and several cross-validations are done. However, to overcome this issue, there is another function in Sklearn called RandomizedSearchCV. It does not test all the hyperparameters, instead, they are chosen at random.
RandomizedSearchCV allows us to specify the number of parameters we wish to randomly test and this is done with the help of a parameter we pass called ‘n_iter’.
Example of Sklearn RandomizedSearchCV
Let us quickly see an example of RandomizedSearchCV in Skleaen. We are using the same dataset that we used in the above examples for GridSearchCV.
from sklearn.model_selection import RandomizedSearchCV
rs = RandomizedSearchCV(SVC(gamma='auto'), {
'C': [1,20,30],
'kernel': ['rbf']
},
cv=2,
return_train_score=False,
n_iter=2
)
rs.fit(x_train, y_train)
print("tuned hyperparameters :(best parameters) ",rs.best_params_)
print("accuracy :",rs.best_score_*100)
tuned hyperparameters :(best parameters) {'kernel': 'rbf', 'C': 30}
accuracy : 79.675
# make predictions on test data
grid_predictions =rs.predict(x_test)
test_accuracy=accuracy_score(y_test,grid_predictions)*100
print("Accuracy for our testing dataset with tuning is : {:.2f}%".format(test_accuracy) )
Accuracy for our testing dataset with tuning is : 79.45%
Conclusion
We hope you liked our tutorial and now better understand the implementation of GridSearchCV and RandomizedSearchCV using Sklearn (Scikit Learn) in Python, to perform hyperparameter tuning. Here, we have illustrated an end-to-end example of using a dataset (bank customer churn) and performed a comparative analysis of multiple models including Logistic regression, KNN, Random Forest, and SVM.
- Reference – Sklearn Documentation

