
Introduction
If you are a part of the machine learning community then you would have seen that MLOPs was one of the most prominent ML topics of 2020. The below Google trend graph also shows that MLOPs popularity has been peaking throughout 2020. In fact, Gartner has identified MLOPs in the top 10 trends of data analytics. In spite of this aroused curiosity, there is still a lot of confusion around what is MLOPs, why is it so important and what is the advantage of implementing MLOPs in the machine learning project.
In this article, we will break down this confusion, we will understand the state of machine learning projects since the last few years that led to the birth of MLOPs. We will then explain what is MLOPs, understand its basics and also do a comparison between MLOPs vs DevOPs.
Is this MLOPs Trend just Hype or Real?
(Bad) State of Machine Learning Projects
Somewhere around 2016-2017 just when the Big Data and Hadoop hype was fizzling out, a new trend of Machine Learning and Data Science took over the market across all industries.
Suddenly every major enterprise started investing in machine learning projects, there was a factor of Fear of Missing Out (FOMO) because everyone seemed to be doing machine learning. Hence budgets got approved overnight in the organizations, the team of data scientists and machine learning engineers got formed and the management waited for them to deliver the promise they expected. But for most of these companies, this wait never got over even after months or years!
So what went wrong?
Shocking Stats of ML Projects
Let me put some shocking stats of survey reports of 2019-2020 below regarding machine learning projects:
- Only 22% of projects saw the machine learning models getting deployed in production successfully in the companies that invested in ML projects.
- 39% of data scientists face challenges to effectively manage dependencies and environments while deploying models.
- 38% of data scientists admit they have skill gaps required for deploying ML models in production.
- 43% of respondents said they find it difficult to scale up their machine learning models to meet the organization’s needs.
Also Read – 23 Must See Facts about State of Data Science and its Challenges in 2020 – 2021
Is Data Scientist to be Blamed?
The above stats pose a question that does the blame goes to the data scientists?
Does the current breed of data scientists lack the competency to deliver the ML project into production?
You may feel so by looking at the surface but these numbers do not give the right reason for ML project failures. An ML project does not consist of only creating and training ML models, in fact, there are many areas in the end-to-end project where a data scientist may not be an expert.
For e.g. we cannot expect a data scientist to create data pipelines to collect data or design the scalable deployment architecture. There has to be a separation of concern and the right team should be engaged at the various stage of the project.
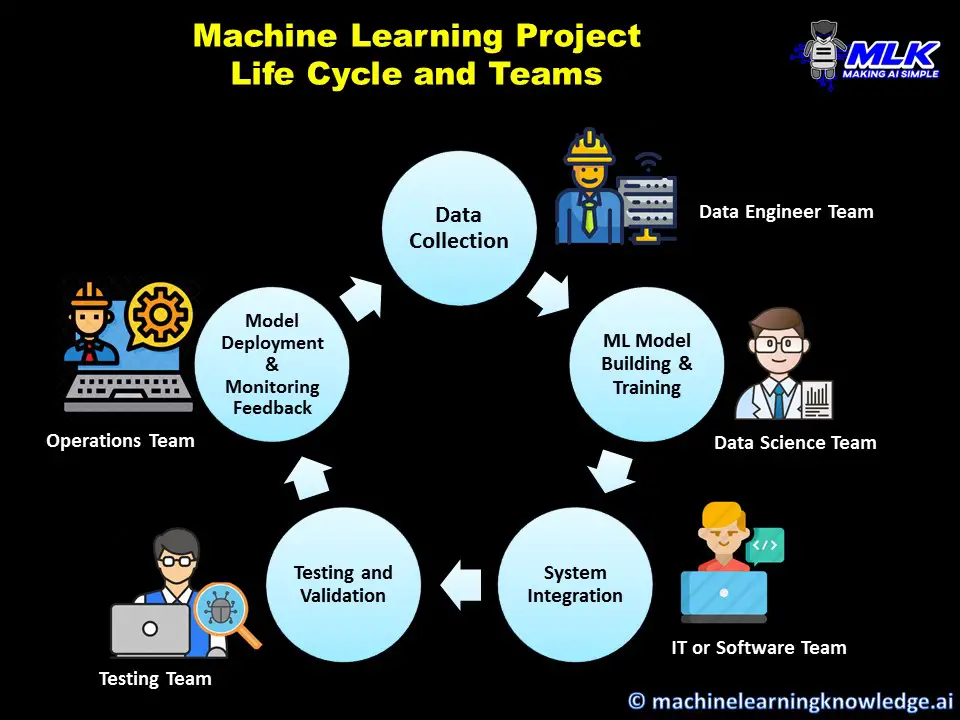
Let us see different types of teams or people that are involved in a typical ML project. This however can vary as there can be fewer or more teams involved in your projects.
Teams in a Machine Learning Project
In organizations that have a matured IT platform, a machine learning project is not carried out in isolation by data scientists. There are various teams involved who take care of various responsibilities in the company’s IT ecosystem.
1. Data Engineer Team
This team is responsible for building data pipelines within various applications in the organization and is the go-to team to bring data to the data warehouse or data lake so that it can be used for performing data analytics or data science.
2. IT or Software Team
An ML model cannot exist in isolation, it either has to be integrated with an application or interacts with another system in production. And more so ever it needs to comply with IT security standards as well. This is where the IT or software team comes into the picture since a data scientist cannot do all these things on its own.
3. Testing Team
This team carries out testing of the ML model’s accuracy created by data scientists to ensure a minimum model benchmark for deploying in the production. Of course, a data scientist does carry out testing of the model, but a testing team can carry out the testing at a wider enterprise level.
4. Operations Team
The operations team is responsible to maintain the system in production and look into its day-to-day operations. As a matter of fact, their feedback on how the model is performing in the production is quite important for data scientists to work on further improvement of the data.
5. Data Scientist Team
Finally, our data scientist guys are responsible to create and train predictive ML models. But their work is not complete here. They also have to collaborate with all the teams we discussed above to ensure a successful start to the end of their ML project.
Why Machine Learning Projects are Failing?
There are multiple but some glaring patterns behind the failure of ML projects in these organizations in spite of pumping millions of dollars into it.
1. Lack of Team Collaboration
We discussed how data scientists have to work with multiple teams in synergy but more often than not they end up working in isolation. This can be unintentional or intentional both on the data scientist and other team’s part. The reason can vary from team politics to just a simple lack of communications and coordination.
Whatever the reason can be but if there is a lack of coordination between multiple teams the project quality and delivery go downhill leading to failures.
2. Lack of Continuous Improvements
An ML model is not always perfect at the first go, it needs to be evaluated and improved over a period of time by acting on the feedback from production or when the data changes. However, data scientists struggle a lot to deliver improvements in a timely manner. This is because each time they have to undertake the complete cycle of data collection, ML model building, testing, deployment, etc that requires touchpoints and collaboration with multiple teams.
A successful ML project depends on how quickly you can take initial ideas and subsequent improvements to production. If the organization lacks this then the ML project becomes more of an investment liability without any ROI and soon the project is declared a failure and shut down.
A few years back even the traditional software industry was seeing these bottlenecks in the software development life cycle and they came up with a set of tools and best practices to streamline the end-to-end cycle. This is known as DevOps.
But a machine learning development life cycle is quite different than the traditional software and we cannot use DevOPs here as it is. So what the industry leader did, they borrowed the concept of DevOPs and repurposed it in a machine learning context, and a new term and discipline MLOps was born!
What is MLOPs
MLOps is a set of tools and best practices for better collaboration between teams and automating the end-to-end machine learning life cycle for better streamlining of continuous integration and deployment.
MLOPs vs DevOps
Since the idea of MLOPs has been derived from DevOps, it often confuses what is the difference between MLOPs vs DevOPs then. The difference comes from the fact that the machine learning model differs a lot from the traditional software system.
- In MLOPs data is the essential input for building the ML model whereas in DevOPs data is just an output of the software, it is not used to create it.
- In MLOPs the model needs to be continuously monitored in production for performance degradation due to new data over a period of time. In DevOPs the software system does not degrade, it is monitored only for health maintenance.
- The concepts like model training, model testing/validation, hyperparameter tuning, etc. are intrinsic to MLOPs only and are not relevant in the traditional software world of DevOPs.
Basics of MLOPs
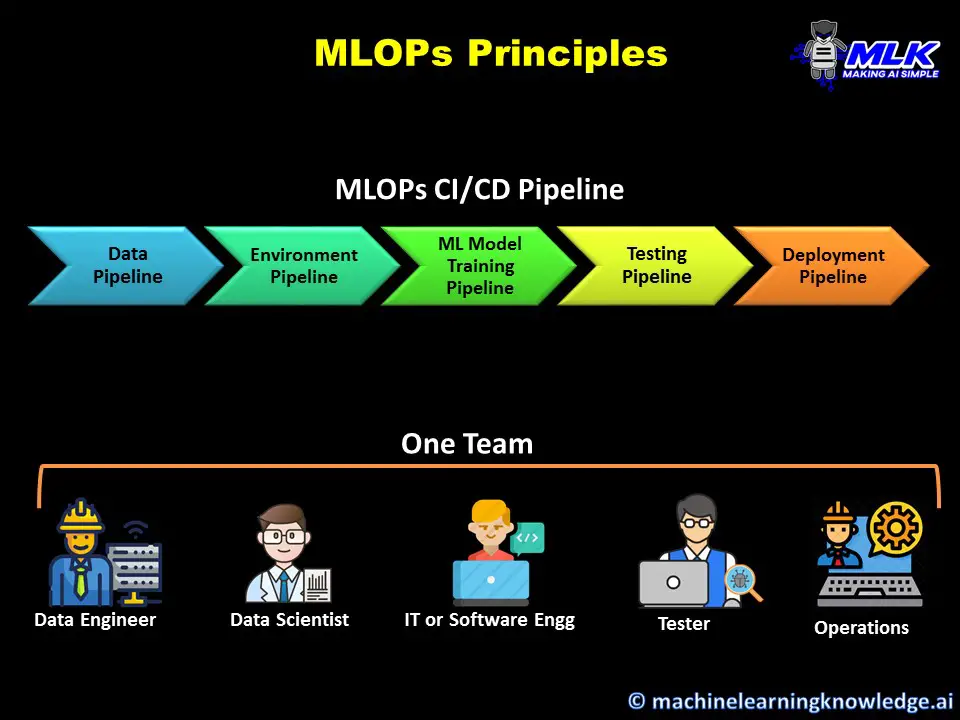
The basic principles of MLOps are heavily borrowed from DevOps and focus on the following tools and practices –
1. CI/CD
CI/CD is an acronym for Continuous Integration and Continuous Deployment or Delivery. The concept states that the tools and practices should be in place to enable small incremental improvements of the ML model and deployment in a continuous manner. To ensure this happens seamlessly we have to employ automation tools in MLOPs since manual touchpoints can slow down things.
2. MLOPs Pipelines
MLOPs Pipelines are nothing but sequential steps that are triggered and executed automatically. Pipelines are the biggest enablers of CI/CD that we discussed above since it helps to expedite the time taken from ideation to deployment of ML model changes.
The MLOPs CI/CD pipelines may consist of these smaller pipelines –
i) Data Pipeline
This pipeline is usually responsible for performing ETL and bring the required data automatically to the model. The pipeline may fetch data from one or different sources, combine and clean it, preprocess it, and finally load it to the target datastore.
ii) Environment Pipeline
Managing environmental dependencies can give nightmares especially when shifting the model to different lower environments before production. The environment pipeline ensures that the right dependencies are loaded every time for the mode.
iii) Training Pipeline
This pipeline puts your model on training automatically and depending on your MLOPs pipeline architecture it may require the data pipeline and training pipeline to load data and dependencies. After training is completed it saves the weight of the model. This pipeline may also be responsible for the hyperparameter tuning of the model.
iv) Testing Pipeline
The trained model should have a minimum quality for production and this is validated in the testing pipeline. It usually has automated test cases that are triggered and executed automatically. This pipeline can serve as a quality gateway that can reject the model from progressing towards deployment in the MLOPs pipeline if the minimum quality is not met.
v) Deployment Pipeline
This pipeline is responsible to deploy and serve the ML model. Usually, this is the last step in the end-to-end MLOPs pipeline and is triggered when all earlier pipelines we discussed above are successfully executed. Depending on the configuration the deployment can be done in the pre-prod environment or in the production environment.
All these pipelines can be integrated together into the bigger end-to-end pipeline. All these pipelines can be set up once and then you can enjoy the automation while you focus only on ML model building.
3. Version Control
Since we deliver continuous changes to the production, in MLOPs it becomes very essential to have the right version controlling strategy in place with the right tools. It is not only the ML model’s version that needs to be controlled it is even the data on which it was trained. This is because with time data changes in production and new models have to be trained on the new version of data. Also, you may deploy multiple versions of the models the model to perform A/B testing to understand which model is working better.
4. Co-Team or Single Team
We discussed earlier how lack of collaboration between various teams is the perfect recipe for ML project failure. The MLOPs philosophy demands that the members of various teams are brought together to form a single team and better if they are colocated. For example, the team may consist of a data engineer, data scientist, IT person, Tester, Ops person who collaboratively work together in day-to-day activity.
MLOPs Tools
With a shift towards the adoption of MLOPs, many tools and platforms have come up in recent times that offer various MLOPs tools. You can either choose various tools for building your MLOPs pipelines or you can work on a single platform that provides one shop solution for all your MLOPs needs.
In fact, all major cloud platforms like Google Cloud Platform (GCP), AWS, Microsoft Azure, etc. provide end-to-end solutions for MLOPs as services that are completely managed. You don’t need to worry much about its setup and infrastructure. At the same time, these platforms are flexible enough if you just want to use selective MLOPs services instead of end-to-end.
If you are looking for open-source solutions then there are platforms like Kubeflow, Seldon, MLflow that can work both on-premise or on the cloud.
Conclusion
Hope this article helped you to understand what is MLOPs and why it is important. We explained the driving factors of ML project failures that led to the adoption of MLOPs. We then did an in-depth understanding of the basics of MLOPs principles and tools along with the comparison between MLOPs vs DevOPs.


