
The Part of speech tagging or POS tagging is the process of marking a word in the text to a particular part of speech based on both its context and definition. In simple language, we can say that POS tagging is the process of identifying a word as nouns, pronouns, verbs, adjectives, etc.
Why POS tag is used
Some words can function in more than one way when used in different circumstances. The POS Tagging here plays a crucial role to understand in what context the word is used in the sentence. POS Tagging is useful in sentence parsing, information retrieval, sentiment analysis, etc.
POS Tagging in Spacy Library
Spacy provides a bunch of POS tags such as NOUN (noun), PUNCT (punctuation), ADJ(adjective), ADV(adverb), etc. It has a trained pipeline and statistical models which enable spaCy to make classification of which tag or label a token belongs to. For example, a word following “the” in English is most likely a noun.
Spacy POS Tags List
Every token is assigned a POS Tag in Spacy from the following list:
| POS | DESCRIPTION | EXAMPLES |
|---|---|---|
| ADJ | adjective | *big, old, green, incomprehensible, first* |
| ADP | adposition | *in, to, during* |
| ADV | adverb | *very, tomorrow, down, where, there* |
| AUX | auxiliary | *is, has (done), will (do), should (do)* |
| CONJ | conjunction | *and, or, but* |
| CCONJ | coordinating conjunction | *and, or, but* |
| DET | determiner | *a, an, the* |
| INTJ | interjection | *psst, ouch, bravo, hello* |
| NOUN | noun | *girl, cat, tree, air, beauty* |
| NUM | numeral | *1, 2017, one, seventy-seven, IV, MMXIV* |
| PART | particle | *’s, not,* |
| PRON | pronoun | *I, you, he, she, myself, themselves, somebody* |
| PROPN | proper noun | *Mary, John, London, NATO, HBO* |
| PUNCT | punctuation | *., (, ), ?* |
| SCONJ | subordinating conjunction | *if, while, that* |
| SYM | symbol | *$, %, §, ©, +, −, ×, ÷, =, :), 😝* |
| VERB | verb | *run, runs, running, eat, ate, eating* |
| X | other | *sfpksdpsxmsa* |
| SPACE | space |
Spacy POS Tagging Example
POS Tagging in Spacy library is quite easy as seen in the below example. We just instantiate a Spacy object as doc. We iterate over doc object and use pos_ , tag_, to print the POS tag. Spacy also lets you access the detailed explanation of POS tags by using spacy.explain() function which is also printed in the same iteration along with POS tags.
import spacy
nlp = spacy.load("en_core_web_sm")
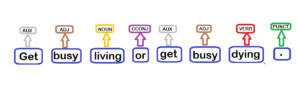
doc = nlp("Get busy living or get busy dying.")
print(f"{'text':{8}} {'POS':{6}} {'TAG':{6}} {'Dep':{6}} {'POS explained':{20}} {'tag explained'} ")
for token in doc:
print(f'{token.text:{8}} {token.pos_:{6}} {token.tag_:{6}} {token.dep_:{6}} {spacy.explain(token.pos_):{20}} {spacy.explain(token.tag_)}')
[Out] :
Fine Grained POS Tag
Spacy also provides a fine-grained tag that further categorizes a token in different sub-categories. For example, when a word is an adjective it further categorizes it as JJR (comparative adjective), JJS (superlative adjective), or AFX (affix adjective). We can get the list of fine grained tags in Spacy by using nlp.pipe_labels[‘tagger’] as shown in the below example.
In [2]
import spacy
nlp = spacy.load("en_core_web_sm")
tag_lst = nlp.pipe_labels['tagger']
print(len(tag_lst))
print(tag_lst)
[Out] :
50 ['$', "''", ',', '-LRB-', '-RRB-', '.', ':', 'ADD', 'AFX', 'CC', 'CD', 'DT', 'EX', 'FW', 'HYPH', 'IN', 'JJ', 'JJR', 'JJS', 'LS', 'MD', 'NFP', 'NN', 'NNP', 'NNPS', 'NNS', 'PDT', 'POS', 'PRP', 'PRP$', 'RB', 'RBR', 'RBS', 'RP', 'SYM', 'TO', 'UH', 'VB', 'VBD', 'VBG', 'VBN', 'VBP', 'VBZ', 'WDT', 'WP', 'WP$', 'WRB', 'XX', '_SP', '``']
Fine Grained POS Tag list
Below is a POS tag list, their description, Fine-grained Tag, their description, Morphology, and some examples.
| POS | POS_Description | Fine-grained Tag | Description | Morphology | EXAMPLE | |
|---|---|---|---|---|---|---|
| 0 | ADJ | adjective | AFX | affix | Hyph=yes | The Flintstones were a **pre**-historic family. |
| 1 | ADJ | adjective | JJ | adjective | Degree=pos | This is a **good** sentence. |
| 2 | ADJ | adjective | JJR | adjective, comparative | Degree=comp | This is a **better** sentence. |
| 3 | ADJ | adjective | JJS | adjective, superlative | Degree=sup | This is the **best** sentence. |
| 4 | ADJ | adjective | PDT | predeterminer | AdjType=pdt PronType=prn | Waking up is **half** the battle. |
| 5 | ADJ | adjective | PRP$ | pronoun, possessive | PronType=prs Poss=yes | **His** arm hurts. |
| 6 | ADJ | adjective | WDT | wh-determiner | PronType=int rel | It’s blue, **which** is odd. |
| 7 | ADJ | adjective | WP$ | wh-pronoun, possessive | Poss=yes PronType=int rel | We don’t know **whose** it is. |
| 8 | ADP | adposition | IN | conjunction, subordinating or preposition | It arrived **in** a box. | |
| 9 | ADV | adverb | EX | existential there | AdvType=ex | **There** is cake. |
| 10 | ADV | adverb | RB | adverb | Degree=pos | He ran **quickly**. |
| 11 | ADV | adverb | RBR | adverb, comparative | Degree=comp | He ran **quicker**. |
| 12 | ADV | adverb | RBS | adverb, superlative | Degree=sup | He ran **fastest**. |
| 13 | ADV | adverb | WRB | wh-adverb | PronType=int rel | **When** was that? |
| 14 | CONJ | conjunction | CC | conjunction, coordinating | ConjType=coor | The balloon popped **and** everyone jumped. |
| 15 | DET | determiner | DT | determiner | **This** is **a** sentence. | |
| 16 | INTJ | interjection | UH | interjection | **Um**, I don’t know. | |
| 17 | NOUN | noun | NN | noun, singular or mass | Number=sing | This is a **sentence**. |
| 18 | NOUN | noun | NNS | noun, plural | Number=plur | These are **words**. |
| 19 | NOUN | noun | WP | wh-pronoun, personal | PronType=int rel | **Who** was that? |
| 20 | NUM | numeral | CD | cardinal number | NumType=card | I want **three** things. |
| 21 | PART | particle | POS | possessive ending | Poss=yes | Fred**’s** name is short. |
| 22 | PART | particle | RP | adverb, particle | Put it **back**! | |
| 23 | PART | particle | TO | infinitival to | PartType=inf VerbForm=inf | I want **to** go. |
| 24 | PRON | pronoun | PRP | pronoun, personal | PronType=prs | **I** want **you** to go. |
| 25 | PROPN | proper noun | NNP | noun, proper singular | NounType=prop Number=sign | **Kilroy** was here. |
| 26 | PROPN | proper noun | NNPS | noun, proper plural | NounType=prop Number=plur | The **Flintstones** were a pre-historic family. |
| 27 | PUNCT | punctuation | -LRB- | left round bracket | PunctType=brck PunctSide=ini | rounded brackets **(**also called parentheses) |
| 28 | PUNCT | punctuation | -RRB- | right round bracket | PunctType=brck PunctSide=fin | rounded brackets (also called parentheses**)** |
| 29 | PUNCT | punctuation | , | punctuation mark, comma | PunctType=comm | I**,**me and myself. |
| 30 | PUNCT | punctuation | : | punctuation mark, colon or ellipsis | colon **:** is a punctuation mark | |
| 31 | PUNCT | punctuation | . | punctuation mark, sentence closer | PunctType=peri | Punctuation at the end of sentence**.** |
| 32 | PUNCT | punctuation | ” | closing quotation mark | PunctType=quot PunctSide=fin | “machine learning**”** |
| 33 | PUNCT | punctuation | “” | closing quotation mark | PunctType=quot PunctSide=fin | **””** |
| 34 | PUNCT | punctuation | “ | opening quotation mark | PunctType=quot PunctSide=ini | **”**machine learning” |
| 35 | PUNCT | punctuation | HYPH | punctuation mark, hyphen | PunctType=dash | ML site **-** machinelearningknowledge.ai |
| 36 | PUNCT | punctuation | LS | list item marker | NumType=ord | |
| 37 | PUNCT | punctuation | NFP | superfluous punctuation | ||
| 38 | SYM | symbol | # | symbol, number sign | SymType=numbersign | This is hash**#** symbol. |
| 39 | SYM | symbol | $ | symbol, currency | SymType=currency | Dollar **$** is the name of more than 20 curre… |
| 40 | SYM | symbol | SYM | symbol | this is a symbol **$** | |
| 41 | VERB | verb | BES | auxiliary “be” | Let it **be**. | |
| 42 | VERB | verb | HVS | forms of “have” | I**’ve** seen the Queen | |
| 43 | VERB | verb | MD | verb, modal auxiliary | VerbType=mod | This **could** work. |
| 44 | VERB | verb | VB | verb, base form | VerbForm=inf | I want to **go**. |
| 45 | VERB | verb | VBD | verb, past tense | VerbForm=fin Tense=past | This **was** a sentence. |
| 46 | VERB | verb | VBG | verb, gerund or present participle | VerbForm=part Tense=pres Aspect=prog | I am **going**. |
| 47 | VERB | verb | VBN | verb, past participle | VerbForm=part Tense=past Aspect=perf | The treasure was **lost**. |
| 48 | VERB | verb | VBP | verb, non-3rd person singular present | VerbForm=fin Tense=pres | I **want** to go. |
| 49 | VERB | verb | VBZ | verb, 3rd person singular present | VerbForm=fin Tense=pres Number=sing Person=3 | He **wants** to go. |
| 50 | X | other | ADD | [email protected] | ||
| 51 | X | other | FW | foreign word | Foreign=yes | Hello in spanish is **Hola** |
| 52 | X | other | GW | additional word in multi-word expression | ||
| 53 | X | other | XX | unknown | ||
| 54 | SPACE | space | _SP | space | ||
| 55 | NIL | missing tag |
Morphology
In linguistics, morphology is defined as the process of analyzing a word, how they are formed, and their relationship to other words in the same language, the structure of words, and parts of words such as stems, root words, prefixes, and suffixes. Morphology also looks at parts of speech, intonation, and stress, and the ways of context can change a word’s pronunciation and meaning.
Spacy uses the token text and fine-grained part-of-speech tags to produce morphological features.
In Spacy, the morphological features are stored in the MorphAnalysis under Token.morph, which allows us to access individual morphological features. In the example below, we are iterating the tokens of doc object and printing all the morphological features by using token.morph attributes. However, we can also access any particular type of morphological features by using morph.get() function. token.morph.to_dict() function returns all the morphological features in a dictionary format.
import spacy
nlp = spacy.load("en_core_web_sm")
print("Pipeline:", nlp.pipe_names)
doc = nlp("I was heading towards North.")
for token in doc:
print(token.text)
print(token.morph) ## Printing all the morphological features.
print(token.morph.get("Number")) ## Printing a particular type of morphological
## features such as Number(Singular or plural).
print(token.morph.to_dict()) ## Prining the morphological features in dictionary format.
print('\n\n')
[Out] :
Pipeline: ['tok2vec', 'tagger', 'parser', 'ner', 'attribute_ruler', 'lemmatizer']
I
Case=Nom|Number=Sing|Person=1|PronType=Prs
['Sing']
{'Case': 'Nom', 'Number': 'Sing', 'Person': '1', 'PronType': 'Prs'}
was
Mood=Ind|Number=Sing|Person=3|Tense=Past|VerbForm=Fin
['Sing']
{'Mood': 'Ind', 'Number': 'Sing', 'Person': '3', 'Tense': 'Past', 'VerbForm': 'Fin'}
heading
Aspect=Prog|Tense=Pres|VerbForm=Part
[]
{'Aspect': 'Prog', 'Tense': 'Pres', 'VerbForm': 'Part'}
towards
[]
{}
North
NounType=Prop|Number=Sing
['Sing']
{'NounType': 'Prop', 'Number': 'Sing'}
.
PunctType=Peri
[]
{'PunctType': 'Peri'}
Counting POS Tags in Spacy
In the example below, we are passing the POS token attribute to Doc.count() function which returns a frequency dictionary with key as POS attribute value and its frequency as the value. With the help of for loop, we are printing the POS tag and its count.
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp(u"Don't be afraid to give up the good to go for the great")
# Counting the frequencies of different POS tags:
POS_counts = doc.count_by(spacy.attrs.POS)
print(POS_counts)
for k,v in sorted(POS_counts.items()):
print(f'{k:{4}}. {doc.vocab[k].text:{5}}: {v}')
Counting fine-grained tags
In the example below, we are passing the TAG token attribute to Doc.count() and it is returning a frequency dictionary with key as TAG attribute value and its frequency as the value. With the help of for loop, we are printing the POS tag and its count.
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp(u"The quick brown fox jumped over the lazy dog's back.")
# Counting the frequencies of different fine-grained tags:
TAG_counts = doc.count_by(spacy.attrs.TAG)
print(TAG_counts)
for k,v in sorted(TAG_counts.items()):
print(f'{k}. {doc.vocab[k].text:{4}}: {v}')
Visualizing the POS Tags in Spacy
In Spacy we can visualize the part-of-speech tags and syntactic dependencies using displacy.serve() function which takes a single Doc or list of Doc objects and returns a nice visualization.
import spacy
from spacy import displacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("You only live once, but if you do it right, once is enough.")
displacy.serve(doc, style="dep")
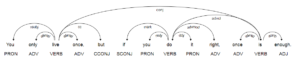
Parameters
distance : Distance between token dipendencies.
compact : Compactness of color.
color : Color of the font.
bg : Background color of the visualization.
font : Style of the font in the visualization.
In [7]:
import spacy
from spacy import displacy
nlp = spacy.load("en_core_web_sm")
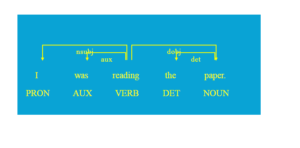
doc = nlp("I was reading the paper")
options = {'distance': 110, 'compact': 'True', 'color': 'yellow', 'bg': '#09a3d5', 'font': 'Times'}
displacy.serve(doc, style="dep",options=options)
Visualizing POS Tags in Long Texts in Spacy
Long texts can become difficult to read when displayed in one row, so it’s often better to visualize them sentence-by-sentence instead. Displacy supports rendering both Doc and Span objects, as well as lists of Docs or Spans. Instead of passing the full Doc to displacy.serve, we can also pass in a list doc.sents. This will create one visualization for each sentence.
import spacy
from spacy import displacy
nlp = spacy.load("en_core_web_sm")
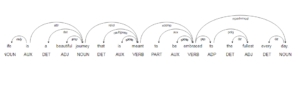
text = "Life is a beautiful journey that is meant to be embraced to the fullest every day.However, that doesn’t mean you always wake up ready to seize the day, and sometimes need a reminder that life is a great gift."
doc = nlp(text)
sentence_spans = list(doc.sents)
displacy.serve(sentence_spans, style="dep")
[Out] :
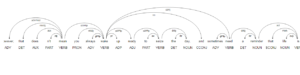
Reference – Spacy Documentation


2 Responses
Nice work!
Thank You for liking the article !