
In this article, we will take you through POS Tagging and Chunking in NLTK library of Python. We will first understand what is POS tagging and why it is used and finally see some examples of it in NLTK. Then we will turn our focus to understand the concept of what is chunking, its application along with some examples in NLTK library.
What is POS Tagging?
POS Tagging is the process of tagging words in a sentence with corresponding parts of speech like noun, pronoun, verb, adverb, preposition, etc.
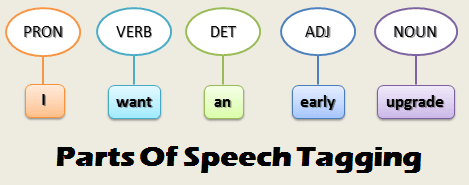
Tagging the words of a text with parts of speech helps to understand how does the word functions grammatically in the context of the sentence. A word can assume different parts of speech depending on the context of the sentence.
POS Tagging is useful in sentence parsing, information retrieval, sentiment analysis, etc. In fact, it is a prerequisite for the process of Chunking and Named Entity Recognition in NLP.
POS Tagging in NLTK Library
POS Tagging in NLTK library is done using pos_tag() function which takes the tokens of a sentence as input and it returns the POS tag for each word.
List of POS Tags in NLTK
Usually, in schools, we are taught about 9 different types of parts of speech – noun, verb, adverb, article, preposition, pronoun, adjective, conjunction, and interjection. But NLTK actually provides many categories and sub-categories of tags than just the traditional nine.
We can generate all the available POS tags by using nltk.help.upenn_tagset() function.
Below is the complete list of NLTK POS tags –
Example of POS Tagging in NLTK
In the below example, we first tokenize the text and pass the tokens to NLTK pos_tag() function.
from nltk import pos_tag
from nltk import word_tokenize
text = "The way to get started is to quit talking and begin doing."
tokenizer = word_tokenize(text)
pos_tag(tokenizer)
Default Tagger in NLTK
NLTK has DefaultTagger function that is used to assign the default tag to the tokens. Let us see this with the help of an example.
Below, we first tokenize the text and then create an instance of DefaultTagger by adding the desired default tag ‘AD’. Finally, we pass the tokenized text to the DefaultTagger instance.
from nltk.tag import DefaultTagger
text = "The way to get started is to quit talking and begin doing."
tokenizer = word_tokenize(text)
tagging = DefaultTagger('Ad')
print(tagging.tag(tokenizer))
What is Chunking in NLP?
We have seen that we can break down a sentence into tokens of words and then do POS tagging for identifying parts of speech for those words. But just doing this does not give us enough meaningful information about the sentence. Chunking can help us to take us to the next level.
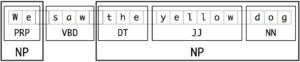
In NLP, chunking is the process of breaking down a text into phrases such as Noun Phrases, Verb Phrases, Adjective Phrases, Adverb phrases, and Preposition Phrases.
Chunking is commonly used to extract Noun Phrases (NP) from the sentence. It should be noted that POS tagging is the prerequisite for the chunking process and the chunks do not overlap with each other.
Chunking is essential for understanding the semantics of the text and helps in information retrieval.
Chunking in NLTK Library
The process of chunking in NLTK is a multi-step process as explained below –
Step1 :
Tokenize the sentence and perform POS Tagging.
Step 2:
Define the grammar to perform chunking. This is a very important step because grammar lays the rule of chunking.
Step 3:
Using this grammar, we create a chunk parser with the help of RegexpParser and apply it to our sentence.
Step 4:
The above step produces the result which can either be printed as it is or we can draw a graph for better visualization.
Example of Chunking in NLTK
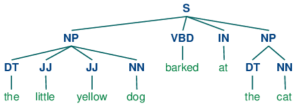
Going by the steps we explained above, in the below example, we first tokenize the sample sentence and perform POS Tagging on it. Then we define the grammar for Noun Phrase as NP: {<DT>?<JJ>*<NN>} which means that a chunk will be constructed when an optional Determiner (DT) is followed by any number of Adjective (JJ) or Noun (NN).
We then initialize an instance of nltk.RegexpParser() with this grammar and use it to parse the tokenized sample sentence. This produces the result of chunking which we both print and draw a tree graph out of it.
import nltk
sentence = "the little yellow dog barked at the cat"
tokens = nltk.word_tokenize(sentence)
print(tokens)
tag = nltk.pos_tag(tokens)
print(tag)
grammar = "NP: {<DT>?<JJ>*<NN>}"
cp = nltk.RegexpParser(grammar)
result = cp.parse(tag)
print(result)
result.draw()
- Also Read – Learn Lemmatization in NTLK with Examples
- Also Read – NLTK Tokenize – Complete Tutorial for Beginners
- Also Read – Complete Tutorial for NLTK Stopwords
- Also Read – Beginner’s Guide to Stemming in Python NLTK
- Also Read – Generating Unigram, Bigram, Trigram and Ngrams in NLTK
Conclusion
Hope you found our article insightful to understand the process of POS Tagging and Chunking in NLTK library. We explained to you the basic concept of both of them along with a couple of examples by using the NLTK library.
Reference – NLTK Documentation

