
Introduction
Here in this article, we will be going through the tutorial of tokenization which is the initial step in Natural Language Processing. We will first understand the concept of tokenization, and see different functions in nltk tokenize library – word_tokenize, sent_tokenize, WhitespaceTokenizer, WordPunctTokenizer, and see how to Tokenize data in a Dataframe.
What is Tokenization in NLP?
Tokenization is the process of breaking up the original raw text into component pieces which are known as tokens. Tokenization is usually the initial step for further NLP operations like stemming, lemmatization, text mining, text classification, sentiment analysis, language translation, chatbot creation, etc.
Almost always while working with NLP projects you will have to tokenize the data.
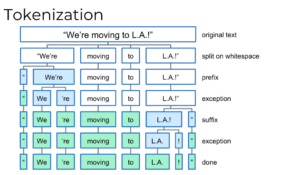
What are Tokens?
Tokens are broken pieces of the original text that are produced after tokenization. Tokens are the basic building blocks of text -everything that helps us understand the meaning of the text is derived from tokens and the relationship to one another. For example, the character is a token in a word, a word is a token in a sentence, and a sentence is a token in a paragraph.
NLTK Tokenize Package
nltk.tokenize is the package provided by the NLTK module that is used in the process of tokenization.
In order to install the NLTK package run the following command.
- pip install nltk
- Then, enter the Python shell in your terminal by simply typing python
- Type import nltk
- nltk.download(‘all’)
i) Character Tokenization in Python
Character tokenization is the process of breaking text into a list of characters. This can be achieved quite easily in Python without the need for the NLTK library.
Let us understand this with the help of an example. In the example below, we used list comprehension to convert the text into a list of characters.
Example
text="Hello world"
lst=[x for x in text]
print(lst)
ii) Word Tokenization with NLTK word_tokenize()
Word tokenization is the process of breaking a string into a list of words also known as tokens. In NLTK we have a module word_tokeinize() to perform word tokenization.
Let us understand this module with the help of an example.
In the examples below, we have passed the string sentence to word_tokenize() and tokenize it into a list of words.
Example 1
from nltk.tokenize import word_tokenize
text="Hello there! Welcome to the programming world."
print(word_tokenize(text))
Example 2
from nltk.tokenize import word_tokenize
text="We are learning Natural Language Processing."
print(word_tokenize(text))
iii) Sentence Tokenization with NLTK sent_tokenize()
Sentence tokenization is the process of breaking a paragraph or a string containing sentences into a list of sentences. In NLTK, sentence tokenization can be done using sent_tokenize().
In the examples below, we have passed text of multiple lines to sent_tokenize() which tokenizes it into a list of sentences.
Example 1
from nltk.tokenize import sent_tokenize
text="It’s easy to point out someone else’s mistake. Harder to recognize your own."
print(sent_tokenize(text))
Example 2
from nltk.tokenize import sent_tokenize
text="Laughing at our mistakes can lengthen our own life. Laughing at someone else's can shorten it."
print(sent_tokenize(text))
iv) Whitespace Tokenization with NLTK WhitespaceTokenizer()
WhitespaceTokenizer() module of NLTK tokenizes a string on whitespace (space, tab, newline). It is an alternate option for split().
In the example below, we have passed a sentence to WhitespaceTokenizer() which then tokenizes it based on the whitespace.
Example
from nltk.tokenize import WhitespaceTokenizer
s="Good muffins cost $3.88\nin New York. Please buy me\ntwo of them.\n\nThanks."
Tokenizer=WhitespaceTokenizer()
print(Tokenizer.tokenize(s))
v) Word Punctuation Tokenization with NLTK WordPunctTokenizer()
WordPunctTokenizer() module of NLTK tokenizes a string on punctuations.
In the below example, we have tokenized the string on punctuations by passing it to WordPuntTokenizer() function.
Example
from nltk.tokenize import WordPunctTokenizer
text="We're moving to L.A.!"
Tokenizer=WordPunctTokenizer()
print(Tokenizer.tokenize(text))
vi) Removing Punctuations with NLTK RegexpTokenizer()
We can remove punctuation from a sentence by using RegexpTokenizer() function of NLTK.
In the example below, we have used RegexpTokenizer() to convert the text into a list of words that don’t contain punctuations and then joined them using .join() function.
Example
from nltk.tokenize import RegexpTokenizer
text="The children - Pierre, Laura, and Ashley - went to the store."
tokenizer = RegexpTokenizer(r"\w+")
lst=tokenizer.tokenize(text)
print(' '.join(lst))
vii) Tokenization Dataframe Columns using NLTK
Quite often you will need to tokenized data in a column of pandas dataframe. This can be achieved easily by using apply and lambda function of Python with the NLTK tokenization functions.
Let us understand this better with the help of an example below.
Example
import pandas as pd
from nltk.tokenize import word_tokenize
df = pd.DataFrame({'Phrases': ['The greatest glory in living lies not in never falling, but in rising every time we fall.',
'The way to get started is to quit talking and begin doing.',
'If life were predictable it would cease to be life, and be without flavor.',
"If you set your goals ridiculously high and it's a failure, you will fail above everyone else's success."]})
df['tokenized'] = df.apply(lambda row: nltk.word_tokenize(row['Phrases']), axis=1)
df.head()
NLTK Tokenize vs Split
The split function is usually used to separate strings with a specified delimiter, e.g. in a tab-separated file, we can use str.split(‘\t’) or when we are trying to split a string by the newline \n when our textfile has one sentence per line or when we are trying to split by any specific character. But the same can’t be performed using the NLTK tokenize functions.
from nltk.tokenize import word_tokenize
text="This is the first line of text.\nThis is the second line of text."
print(text)
print(text.split('\n')) #Spliting the text by '\n'.
print(text.split('\t')) #Spliting the text by '\t'.
print(text.split('s')) #Spliting by charecter 's'.
print(text.split()) #Spliting the text by space.
print(word_tokenize(text)) #Tokenizing by using word
Conclusion
Here in this NLTK Tokenize tutorial, we have learned –
- Tokenization is the process of breaking up the original raw text into component pieces which are known as tokens.
- Tokens are the basic building blocks of text.
- Word tokenization is the process of breaking a string into a list of words.
- Sentence tokenization is the process of breaking a paragraph or a string containing sentences into a list of sentences.
- WhitespaceTokenizer() function tokenizes a string on whitespace.
- WordPunctTokenizer() tokenizes a string based on punctuations.
- Difference between NLTK Tokenize vs Split.
Reference – NLTK Documentation

