
Introduction
In this tutorial, we will go through various options of feature scaling in the Sklearn library – StandardScaler, MinMaxScaler, RobustScaler, and MaxAbsScaler. We will understand the formulae of these techniques in brief and then go through practical examples of the implementation of each of them for easy understanding of the beginners.
Feature Scaling in Machine Learning
Feature Scaling is used to normalize the data features of our dataset so that all features are brought to a common scale. This is a very important data preprocessing step before building any machine learning model, otherwise, the resulting model will produce underwhelming results.
To understand why feature scaling is necessary let us take an example, suppose you have several independent features like age, employee salary, and height(in feet). Here the possible values of these features lie within the range (21–100 Years), (25,000–1,50,000 INR), and (4.5 – 7 feet) respectively. As you can see each feature has its own range and when these numbers are fed to the model during the training process, the model will not understand the skewness in the data range. This is because it does not understand years, salary, height all it will see are numbers varying across a big range and all this will result in a bad model.
Feature Scaling will help to bring these vastly different ranges of values within the same range. For example, values of years, salary, height can be normalized in the range from (0,1) and thus giving a more quality input to the ML model.
Feature Scaling Techniques
Standardization
Standardization is a useful method to scales independent variables so that it has a distribution with 0 mean value and variance equals 1. However, Standard Scaler is not a good option if our datapoints aren’t normally distributed i.e they do not follow Gaussian distribution.
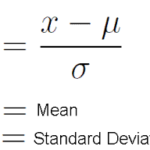
In Sklearn standard scaling is applied using StandardScaler() function of sklearn.preprocessing module.
Min-Max Normalization
In Min-Max Normalization, for any given feature, the minimum value of that feature gets transformed to 0 while the maximum value will transform to 1 and all other values are normalized between 0 and 1. This method however has a drawback as it is sensitive to outliers.
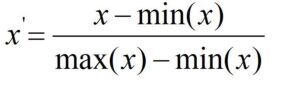
In Sklearn Min-Max scaling is applied using MinMaxScaler() function of sklearn.preprocessing module.
MaxAbs Scaler
In MaxAbs-Scaler each feature is scaled by using its maximum value. At first, the absolute maximum value of the feature is found and then the feature values are divided with it. Just like MinMaxScaler MaxAbs Scaler are also sensitive to outliers.
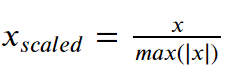
In Sklearn MaxAbs-Scaler is applied using MaxAbsScaler() function of sklearn.preprocessing module.
Robust-Scaler
Robust-Scaler is calculated by using the interquartile range(IQR), here, IQR is the range between the 1st quartile (25th quantile) and the 3rd quartile (75th quantile). It can handle outlier data points as well.
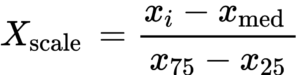
In Sklearn Robust-Scaler is applied using RobustScaler() function of sklearn.preprocessing module.
Sklearn Feature Scaling Examples
In this section, we shall see examples of Sklearn feature scaling techniques of StandardScaler, MinMaxScaler, RobustScaler, and MaxAbsScaler. For this purpose, we will do regression on the housing dataset, and first, see results without feature scaling and then compare the results by applying feature scaling.
About Dataset
The dataset is a California housing dataset that contains various features of the house like its location, age, no. of rooms, house value, etc. The problem statement is to predict the house value given other independent feature variables in the dataset. It contains 20433 rows and 9 columns.
Importing Necessary Libraries
To start with let us load all the required libraries required for our examples.
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler,MinMaxScaler,MaxAbsScaler,RobustScaler
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsRegressor
from sklearn.metrics import accuracy_score
from sklearn import preprocessing
Loading Dataset
#reading the dataset
df=pd.read_csv(r"C:\Users\Veer Kumar\Downloads\MLK internship\FeatureScaling\housing.csv")
df.drop(['ocean_proximity'],axis=1,inplace=True)
df.head(10)
| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | median_house_value | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | -122.23 | 37.88 | 41.0 | 880.0 | 129.0 | 322.0 | 126.0 | 8.3252 | 452600.0 |
| 1 | -122.22 | 37.86 | 21.0 | 7099.0 | 1106.0 | 2401.0 | 1138.0 | 8.3014 | 358500.0 |
| 2 | -122.24 | 37.85 | 52.0 | 1467.0 | 190.0 | 496.0 | 177.0 | 7.2574 | 352100.0 |
| 3 | -122.25 | 37.85 | 52.0 | 1274.0 | 235.0 | 558.0 | 219.0 | 5.6431 | 341300.0 |
| 4 | -122.25 | 37.85 | 52.0 | 1627.0 | 280.0 | 565.0 | 259.0 | 3.8462 | 342200.0 |
| 5 | -122.25 | 37.85 | 52.0 | 919.0 | 213.0 | 413.0 | 193.0 | 4.0368 | 269700.0 |
| 6 | -122.25 | 37.84 | 52.0 | 2535.0 | 489.0 | 1094.0 | 514.0 | 3.6591 | 299200.0 |
| 7 | -122.25 | 37.84 | 52.0 | 3104.0 | 687.0 | 1157.0 | 647.0 | 3.1200 | 241400.0 |
| 8 | -122.26 | 37.84 | 42.0 | 2555.0 | 665.0 | 1206.0 | 595.0 | 2.0804 | 226700.0 |
| 9 | -122.25 | 37.84 | 52.0 | 3549.0 | 707.0 | 1551.0 | 714.0 | 3.6912 | 261100.0 |
Regression without Feature Scaling
Let us first create the regression model with KNN without applying feature scaling. It can be seen that the accuracy of the regression model is mere 24% without feature scaling.
# Train Test Split X=df.iloc[:,:-1] y=df.iloc[:,[7]] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0) # Creating Regression Model clf = KNeighborsRegressor() clf.fit(X_train, y_train) # Accuracy on Tesing Data clf.predict(X_test) score=clf.score(X_test,y_test) print("Accuracy for our testing dataset without Feature scaling is : {:.3f}%".format(score*100) )
Accuracy for our testing dataset without Feature scaling is : 24.722%
Applying Sklearn StandardScaler
# Train Test Split X=df.iloc[:,:-1] y=df.iloc[:,[7]] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0) #Creating StandardScaler Object scaler = preprocessing.StandardScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test) #Seeing the scaled values of X_train X_train.head()
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|
| 776 | -1.277402 | 0.948735 | -0.765048 | -0.812050 | -0.880144 | -0.898309 | -0.827732 | 0.249804 |
| 1969 | -0.653503 | 1.379387 | -1.638653 | 0.357171 | 0.156937 | 0.245374 | 0.323227 | 0.111380 |
| 20018 | 0.150079 | -0.633443 | 1.855769 | -0.181906 | -0.279729 | -0.427070 | -0.267947 | 0.133652 |
| 8548 | 0.579322 | -0.820683 | 0.426233 | -0.533359 | -0.545525 | -0.818004 | -0.615851 | 1.691745 |
| 9847 | -1.397190 | 1.262362 | 0.029139 | -0.351683 | -0.585869 | -0.583267 | -0.563534 | 0.502220 |
# Creating Regression Model
model=KNeighborsRegressor()
model.fit(X_train,y_train)
# Accuracy on Tesing Data
y_test_hat=model.predict(X_test)
score=model.score(X_test,y_test)
print("Accuracy for our testing dataset using Standard Scaler is : {:.3f}%".format(score*100) )
Accuracy for our testing dataset using Standard Scaler is : 98.419%
Applying Sklearn MinMaxScaler
# Train Test Split X=df.iloc[:,:-1] y=df.iloc[:,[7]] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0) #Creating MinMax Object mm = preprocessing.MinMaxScaler() X_train = mm.fit_transform(X_train) X_test = mm.transform(X_test) #Seeing the scaled values of X_train X_train.head()
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.211155 | 0.567481 | 0.784314 | 0.022331 | 0.019863 | 0.008941 | 0.020556 | 0.539668 | 0.902266 |
| 1 | 0.212151 | 0.565356 | 0.392157 | 0.180503 | 0.171477 | 0.067210 | 0.186976 | 0.538027 | 0.708247 |
| 2 | 0.210159 | 0.564293 | 1.000000 | 0.037260 | 0.029330 | 0.013818 | 0.028943 | 0.466028 | 0.695051 |
| 3 | 0.209163 | 0.564293 | 1.000000 | 0.032352 | 0.036313 | 0.015555 | 0.035849 | 0.354699 | 0.672783 |
| 4 | 0.209163 | 0.564293 | 1.000000 | 0.041330 | 0.043296 | 0.015752 | 0.042427 | 0.230776 | 0.674638 |
Now this scaled data is used for creating the regression model and again it can be seen that the accuracy of the model is quite good at 98.55%
# Creating Regression Model model=KNeighborsRegressor() model.fit(X_train,y_train) # Accuracy on Tesing Data y_test_hat=model.predict(X_test) score=model.score(X_test,y_test) print("Accuracy for our testing dataset using MinMax Scaler is : {:.3f}%".format(score*100) )
Accuracy for our testing dataset using MinMax Scaler is : 98.559%
Create a MaxAbsScaler object followed by applying the fit_transform method on the training dataset and then transform the test dataset with the same object.
In [8]:
# Train Test Split X=df.iloc[:,:-1] y=df.iloc[:,[7]] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0) #Creating MaxAbsScaler Object mab=MaxAbsScaler() X_train = mab.fit_transform(X_train) X_test = mab.transform(X_test)
Next, we create the KNN regression model using the scaled data and it can be seen that the test accuracy is 99.38%
# Creating Regression Model model=KNeighborsRegressor() model.fit(X_train,y_train) # Accuracy on Tesing Data y_test_hat=model.predict(X_test) score=model.score(X_test,y_test) print("Accuracy for our testing dataset using MinMax Scaler is : {:.3f}%".format(score*100) )
Accuracy for our testing dataset using MaxAbs Scaler is : 99.382%
Apply RobustScaler in Sklearn
# Train Test Split X=df.iloc[:,:-1] y=df.iloc[:,[7]] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0) #Creating RobustScaler Object rob =RobustScaler() X_train = rob.fit_transform(X_train) X_test = rob.transform(X_test)
Finally, we create the regression model and test the accuracy which turns out to be 98.295%
In [11]:
# Creating Regression Model model=KNeighborsRegressor() model.fit(X_train,y_train) # Accuracy on Tesing Data y_test_hat=model.predict(X_test) score=model.score(X_test,y_test) print("Accuracy for our testing dataset using MinMax Scaler is : {:.3f}%".format(score*100) )
Accuracy for our testing dataset using Robust Scaler is : 98.295%
Summary
From the below observation, it is quite evident that feature scaling is a very important step of data preprocessing before creating the ML model. Without feature scaling the accuracy was very poor and after different feature scaling techniques were applied the test accuracy became above 98%.
| Type of Scaling | Test_Accuracy |
|---|---|
| No Feature Scaling | 24.722% |
| StandardScaler | 98.419% |
| MinMaxScaler | 98.559% |
| MaxAbsScaler | 99.382% |
| RobustScaler | 98.295% |


2 Responses
What about data leakage in this? Are there changes of data leakage which may have increased accuracy.
The scaler objects have been created by fitting on the training dataset only. So there is no possibility of test data leaking into the training process.