
Introduction
Feature scaling in machine learning is one of the most important steps during the preprocessing of data before creating a machine learning model. This can make a difference between a weak machine learning model and a strong one. Before we jump on to various techniques of feature scaling let us take some effort to understand why we need feature scaling, only then we would be able to appreciate its importance.
- Also Read – Types of Machine Learning
Why Feature Scaling in Machine Learning
Machine and number
Machine learning algorithm works on numbers and has no knowledge of what that number represents. A weight of 75 Kg and a distance of 75 miles represents completely two different things – this we human can understand easily. But for a machine, both are 75 and are one and same, irrespective of the fact that the units of both are different.
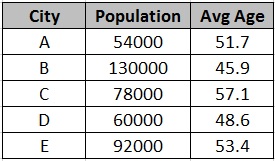
The further implication of this becomes more interesting. Let us take a look at the above table which lists the population and average age of people in the city. As a human, if we are just given number 54000 and are told that this number can either be Population or Age, it would be very intuitive for us to say that 54000 cannot be average age, so it should be population. But think about the machine – the poor guy would not be able to understand that 54000 is too big of a number to be called as the average age of people in a city. Similarly, it is easy for us humans to guess that a city population can’t be 51.7 (a fraction) but the machine cant understand this.
The intuition of problem
Now, keeping this in mind let us think of a machine learning classification algorithm like neural network working on this data. It just sees number – few ranging in thousands and few ranging in the fifties and it makes the underlying assumption that higher ranging numbers have superiority of some sort. So these bigger number (of Population) starts playing a more decisive role while training the model.
This is where the problem lies. The “Population” cannot have a meaningful comparison with the “Average Age”. So the assumption algorithm makes that since 54000 > 51.7 and 130000 > 45.9, therefore, Population is more important feature is fundamentally incorrect.
This problem happens not only in the neural network but in all the algorithm that relies on distance calculation during the training phase.
Scaling down numbers
This serious issue can be addressed with the help of Feature Scaling in machine learning. The intuitive logic behind this is that if all the features are scaled down at a similar range, for e.g. 0 to 1 then this would prevent one feature to dominate over other features, thus overcoming the issue discussed above.
There are many techniques by which we can do Feature Scaling. Let us explore them one by one.
[adrotate banner=”3″]
Mean Normalization
Let us assume that we have to scale down feature A of a data set using Mean Normalization. So each value of column A can be scaled down using below formula.
Scaled_Value(FeatureA)= \(\frac { Value(FeatureA)-Mean(FeatureA) }{ Max(FeatureA)-Min(FeatureA) } \)
In our example data set, let us try to mean normalize value Population = 78000
Mean(Population) = 82800 , Max(Population) = 130000 , Min(Population)=54000
Scaled_Value(78000)=\( \frac { 78000-82800 }{130000-54000} \)= 0.514285714
Below is the complete mean normalization of Population and Avg Age features in above data set-
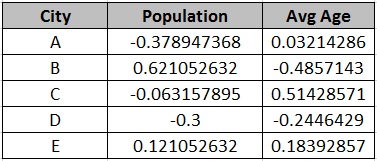
By doing Mean Normalization, the values are compressed between range of -1 to +1 in such a way that the mean of these new values are 0.
Min-Max Normalization
Let us assume that we have to scale down feature A of a data set using Min-Max Normalization. So each value of column A can be scaled down using below formula.
Scaled_Value(FeatureA)= \(\frac { Value(FeatureA)-Min(FeatureA) }{ Max(FeatureA)-Min(FeatureA) } \)
In our example data set, let us try to min-max normalize value Population = 78000
Max(Population) = 130000 , Min(Population)=54000
Scaled_Value(78000)=\( \frac { 78000-54000 }{130000-54000} \)= 0.315789474
Below is the complete min-max normalization of Population and Avg Age features in above data set-
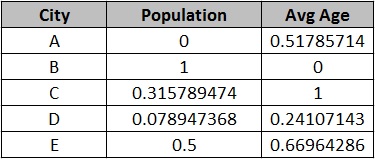
By doing min-max normalization, the range of values are scaled down to between 0 to 1.
Standardization or Z-Score Normalization
Let us assume that we have to scale down feature A of a data set using Standardization. So each value of column A can be scaled down using the below formula.
Scaled_Value(FeatureA)= \(\frac { Value(FeatureA)-Mean(FeatureA) }{ StandardDeviation(FeatureA)} \)
In our example data set, let us try to standardize value Population = 78000
Mean(Population) = 82800 , StandardDeviation(Population) = 27147.007
Scaled_Value(78000)=\( \frac { 78000-82800}{27147.007} \)= -0.176815118
Below is the complete min-max normalization of Population and Avg Age features in above data set-
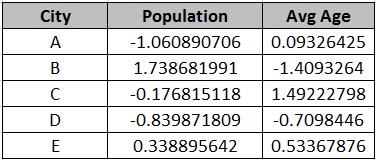
Standardization technique is also known as Z-Score normalization.
Some Points to consider
- Feature scaling is essential for machine learning algorithms that calculate distances between data. If not scaled the feature with a higher value range will start dominating when calculating distances, as explained intuitively in the introduction section.
- So algorithms that use distance calculations like K Nearest Neighbor, Regression, SVMs, etc are the ones that require feature scaling.
- On the other hand, algorithms that do not use distance calculations like Naive Bayes, Tree-based models, LDA do not require feature scaling.
- Which feature technique to use, varies from case to case. For e.g. PCA that deals with variance data, it is advisable to use standardization.
- Feature scaling also helps gradient descend to converge more faster on a small range of values.
In The End…
Hope it was a good simple read and gave you an idea of why feature scaling in machine learning is required and how to do it.
Do share your feed back about this post in the comments section below. If you found this post informative, then please do share this and subscribe to us by clicking on bell icon for quick notifications of new upcoming posts.


