
Introduction
Overfitting and underfitting in machine learning are phenomena that result in a very poor model during the training phase. These are the types of models you should avoid creating during training as they can’t be used in production and are nothing more than a piece for trash.
In this post, we will understand what exactly is overfitting and underfitting and how to detect them. We will also see how we can avoid them. But before all this, we will get ourselves familiarized with few other related concepts to build a base. So let us begin.
Related Initial Concepts
Generalization and True Function
For any given real-world problem where we have a set of inputs and output data, we can map these inputs to the output using a function.
The goal of supervised machine learning model is to produce a model that not only understand the function between input and output for training data but also generalize this function so that it can work with new unseen data with good accuracy.
Given a set of data that represents this real-world problem, there always exists that one hypothetical True Function that can generalize input and output mapping in the best way possible.
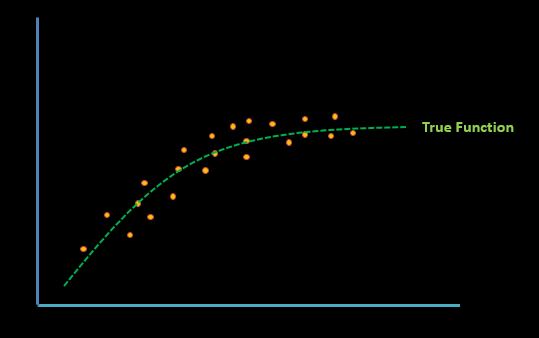
As we can see in this illustration, this true function line represents the sweet spot that generalizes the data distribution.
During the training phase, the goal is to find a function as close as possible to this actual true function to produce a generalized model.
Bias and Variance
These are two related concepts that will not only help you understand overfitting and underfitting in machine learning but also how a good machine learning model should behave.
Bias
Bias is the error that is introduced by the model’s prediction and the actual data.
Bias = Predicted – Actual
- High Bias means the model has created a function that fails to understand the relationship between input and output data.
- Low Bias means the model has created a function that has understood the relationship between input and output data.
Variance
The variance of the machine learning model is the amount by which its performance varies with different data set.
- Low variance means, the performance of the machine learning model does not vary much with the different data set
- High variance means, the performance of the machine learning model varies considerably with different data set.
Good Fit Model
Before we discuss about the bad model we should first understand how the good model should look like.
A well-trained model should have low variance and low bias. This is also known as Good Fit.
In the animation, you may see that the good fit function is actually very close to the actual true function that generalizes the data distribution.
This means a good fit model should be generalized enough to work with any unseen data (low variance) and at the same time should produce low prediction error (low bias).
A good fit model is what we try to achieve during the training phase.
Overfitting and Underfitting
Now that we have understood all the relevant terms and concepts let us now understand overfitting and underfitting in machine learning in detail and why it is such a bad thing.
Overfitting
During the training phase, the model can learn the complexity of training data in so detail that it creates a complex function which can almost map entire input data with output data correctly, with very little or no error.
So does it mean that you should be happy that the model could map the complex relationship between training data so accurately? Not really. Use this model to predict test or unseen data and it will fail miserably!!
As you can see in the animation, the model has created such a complex function that it covers all the test points in a zig-zag manner.
This is the classic case of overfitting where the model shows low error or bias during training phase but fails to show similar accuracy with the test or unseen data (i.e. high variance)
Underfitting
On the other hand, during the training phase, the model may not learn the complex relationship between training data in much details and can come up with a very simple model.
In animation, you can see that the model produced just a simple straight-line function, even though the data distribution is nonlinear.
This simple model looks generalized that may work with other data (low variance). However it is so simple that it produces too much error in prediction (high bias).
How to detect Overfitting and Underfitting
As you can see, overfitting introduces the problem of high variance and underfitting results in high bias and thus resulting in a bad model.
We can identify these models during training and testing phase itself.
- If a model is showing high accuracy during the training phase but fails to show similar accuracy during the testing phase it indicates overfitting.
- If a model fails to show satisfactory accuracy during the training phase itself it means the model is underfitting.
There are many testing strategies that you may you use here. You can read more about them in below post –
How to avoid Overfitting and Underfitting
Creating a good machine learning model is more of an art than certain thumb of rules.
There can be various reasons for underfitting and overfitting and below are some guidelines that you can use to eliminate them.
Avoiding Overfitting
- Increase the data in your training set. Limiting yourself with a very small data set can cause your model to create a direct function rather than a generalized function.
- Reduce the complexity of your machine learning model architecture. For example, you can reduce the number of neurons/layers in neural network, reduce number of estimators in Random Forest, etc. Do remember that we should design the simplest machine learning model that can solve our problem.
- Early stopping during training phase can prevent the model from overfitting with the training data itself in subsequent epochs.
- In case of deep neural network you may use techniques of Dropouts where neurons are randomly switched off during training phase.
- Applying L1 and L2 regularization techniques limit the model’s tendency to overfit. It is a broad topic which we may discuss in a separate post.

Avoiding Underfitting
- Increase the data. Again if you limit the data during training phase you are not providing enough details to model to learn the relationship between data.
- Increase the complexity of your machine learning model as it might help you to capture the underlying complex relationships between data. For e.g increasing the number of neurons/layers in the neural networks.
- You might be using too many fewer features and hence providing too much less information to your model, resulting in underfitting. So you may try to increase the number of features into your model.
- There might be too much noise in the data that might be preventing your model to understand the correct nature of data. Try to do proper preprocessing and noise removal from the data.
- You might be terminating the training epochs before the model starts fitting the data. You may increase the number of epochs and see if the model shows better accuracy.
In The End…
I hope it was a good knowledgeable read on the bad boys of the machine learning world. As I said before, creating a good fit model is more like an art. You do something cheesy here and there and you might end up with overfitted or underfitted model.
Do share your feedback about this post in the comments section below. If you found this post informative, then please do share this and subscribe to us by clicking on the bell icon for quick notifications of new upcoming posts. And yes, don’t forget to join our new community MLK Hub and Make AI Simple together.


