
Introduction
In this article, we will go through the tutorial for Keras Optimizers. We will explain why Keras optimizers are used and what are its different types. We will also cover syntax and examples of different types of optimizers in Keras for better understanding of beginners. At last, we’ll also compare the performance of the optimizers discussed in this Keras tutorial.
Keras Optimizers Explained for Neural Network
Optimizers are not integral to Keras but a general concept used in Neural Network and Keras has out of the box implementations for Optimizers. But before going through the list of Keras optimizers we should first understand why optimizers.
When training a neural network, its weights are initially initialized randomly and then they are updated in each epoch in a manner such that they increase the overall accuracy of the network. In each epoch, the output of the training data is compared to actual data with the help of the loss function to calculate the error and then the weight is updated accordingly But how do we know how to update the weight such that it increases the accuracy?
- Also Read – Dummies guide to Loss Functions in Machine Learning [with Animation]
- Also Read – Types of Keras Loss Functions Explained for Beginners
This is essentially an optimization problem where the goal is to optimize the loss function and arrive at ideal weights. The method used for optimization is known as Optimizer. Gradient Descent is the most widely known but there are many other optimizers that are used for practical purposes and they all are available in Keras.
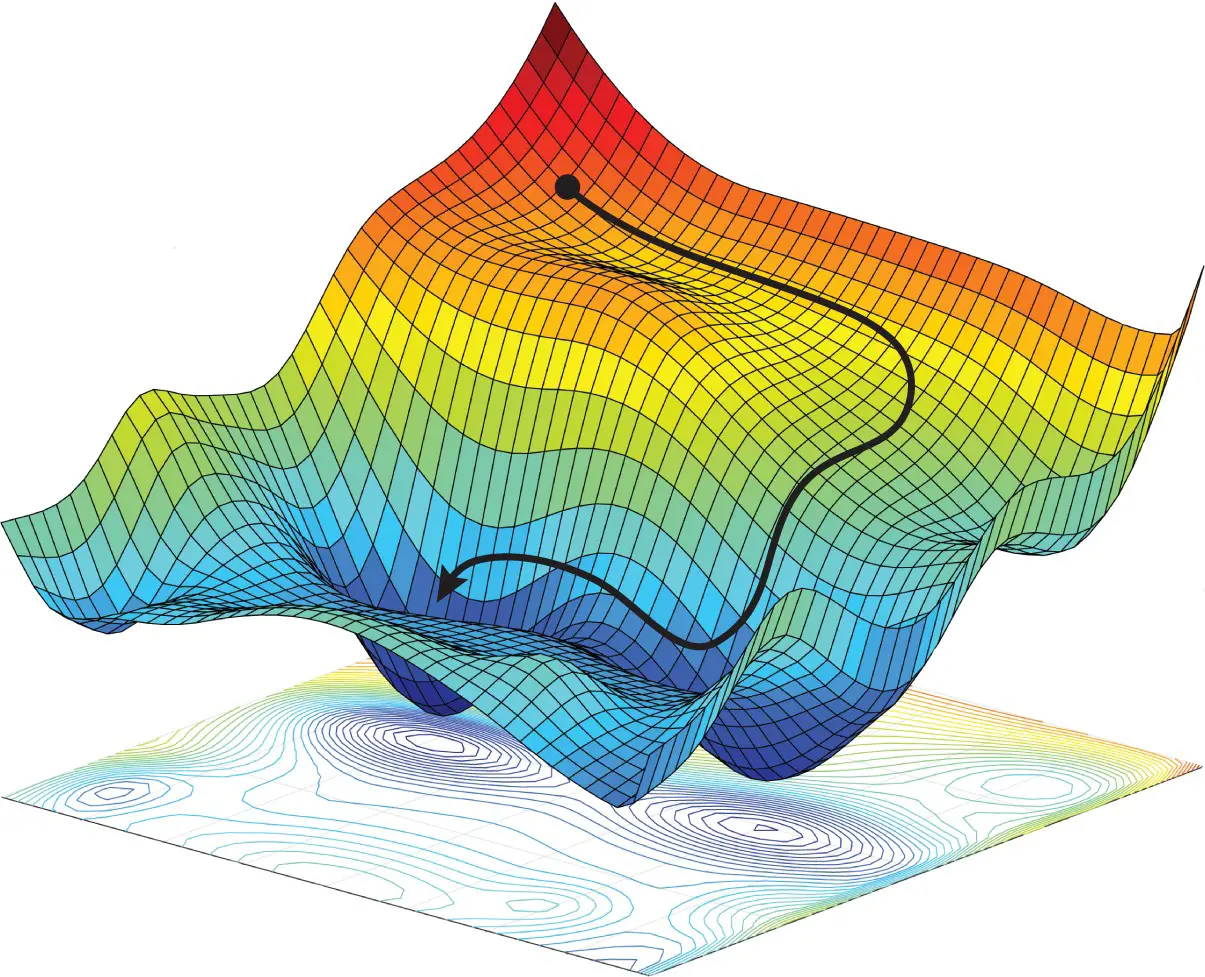
Keras provides APIs for various implementations of Optimizers. You will find the following types of optimizers in Keras –
- SGD
- RMSprop
- Adam
- Adadelta
- Adagrad
- Adamax
- Nadam
- Ftrl
Keras Optimizer Examples of Usage
First of all, let us understand how we can use optimizers while designing neural networks in Keras. There are two ways doing this –
- Create an instance of the optimizer in Keras and use it while compiling the method.
- Directly pass the string identifier for the Optimizer while compiling the method.
Example of 1st Method
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential()
model.add(layers.Dense(64, kernel_initializer='uniform', input_shape=(10,)))
model.add(layers.Activation('softmax'))
opt = keras.optimizers.Adam(learning_rate=0.01)
model.compile(loss='categorical_crossentropy', optimizer=opt)
Example of 2nd Method
# pass optimizer by name: default parameters will be used
model.compile(loss='categorical_crossentropy', optimizer='adam')
Types of Keras Optimizers
Now we will understand different types of optimizers in Keras and their usage along with advantages and disadvantages.
1. Keras SGD Optimizer (Stochastic Gradient Descent)
SGD optimizer uses gradient descent along with momentum. In this type of optimizer, a subset of batches is used for gradient calculation.
Syntax of SGD in Keras
tf.keras.optimizers.SGD
(learning_rate=0.01, momentum=0.0, nesterov=False, name="SGD", **kwargs)Example of Keras SGD
Here SGD optimizer is imported from Keras library. We have also specified the learning rate in this example.
import numpy as np
import tensorflow as tf
opt = tf.keras.optimizers.SGD(learning_rate=0.1)
var = tf.Variable(1.0)
loss = lambda: (var ** 2)/2.0 # d(loss)/d(var1) = var1
step_count = opt.minimize(loss, [var]).numpy()
# Step is `- learning_rate * grad`
var.numpy()
2. Keras RMSProp Optimizer (Root Mean Square Propagation)
In the RMSProp optimizer, the aim is to ensure a constant movement of the average of square of gradients. And secondly, the division of gradient by average’s root is also performed.
Syntax of Keras RMSProp
tf.keras.optimizers.RMSprop(learning_rate=0.001, rho=0.9,
momentum=0.0, epsilon=1e-07, centered=False, name="RMSprop",**kwargs)Example of Keras RMSProp (Root Mean Square Propagation)
The following example shows how keras library is used for implementing root mean square propagation optimizer.
opt = tf.keras.optimizers.RMSprop(learning_rate=0.1)
var1 = tf.Variable(10.0)
loss = lambda: (var1 ** 2) / 2.0 # d(loss) / d(var1) = var1
step_count = opt.minimize(loss, [var1]).numpy()
var1.numpy()
3. Keras Adam Optimizer (Adaptive Moment Estimation)
The adam optimizer uses adam algorithm in which the stochastic gradient descent method is leveraged for performing the optimization process. It is efficient to use and consumes very little memory. It is appropriate in cases where huge amount of data and parameters are available for usage.
Keras Adam Optimizer is the most popular and widely used optimizer for neural network training.
Syntax of Keras Adam
tf.keras.optimizers.Adam(learning_rate=0.001, beta_1=0.9 beta_2=0.999, epsilon=1e-07,amsgrad=False, name="Adam",**kwargs)Example of Keras Adam Optimizer
The following code snippet shows an example of adam optimizer.
opt = tf.keras.optimizers.Adam(learning_rate=0.1)
var1 = tf.Variable(10.0)
loss = lambda: (var1 ** 2)/2.0 # d(loss)/d(var1) == var1
step_count = opt.minimize(loss, [var1]).numpy()
# The first step is `-learning_rate*sign(grad)`
var1.numpy()
4. Keras Adadelta Optimizer
In Adadelta optimizer, it uses an adaptive learning rate with stochastic gradient descent method. Adadelta is useful to counter two drawbacks:
- The continuous learning rate degradation during training.
- It also solves the problem of the global learning rate.
Syntax of Keras Adadelta Optimizer
tf.keras.optimizers.Adadelta(
learning_rate=0.001, rho=0.95, epsilon=1e-07, name="Adadelta",**kwargs)5. Keras Adagrad Optimizer
Keras Adagrad optimizer has learning rates that use specific parameters. Based on the frequency of updates received by a parameter, the working takes place.
Even the learning rate is adjusted according to the individual features. This means there are different learning rates for some weights.
Syntax of Keras Adagrad
tf.keras.optimizers.Adagrad(learning_rate=0.001,
initial_accumulator_value=0.1,epsilon=1e-07, name="Adagrad", **kwargs)Comparison of Optimizers
The graphs show a comparison of the performance of different optimizers that we discussed above. We can see that RMSProp helps to converge the training of neural networks in fewer epochs or iteration whereas Adagrad takes the most time for converging. In case of Adam, it is clearly visible how it goes beyond the desired location due to momentum and then comes back to the correct point of convergence.
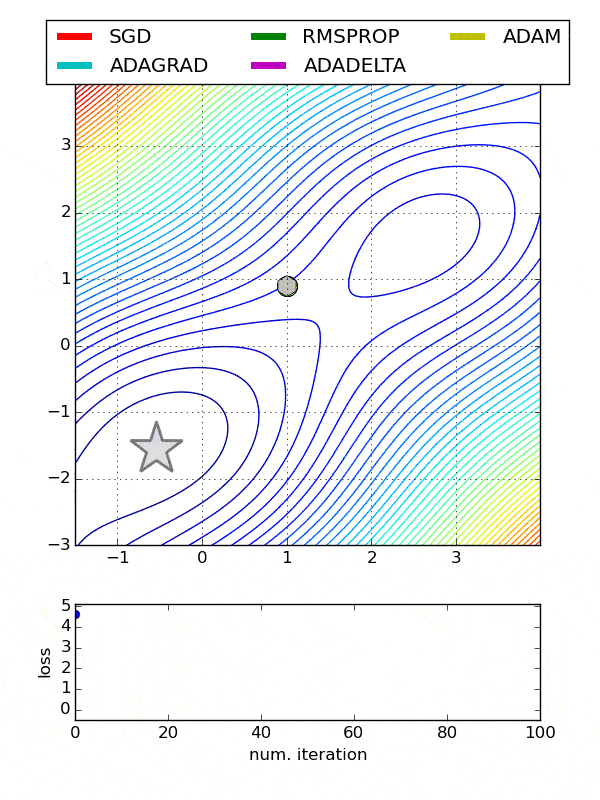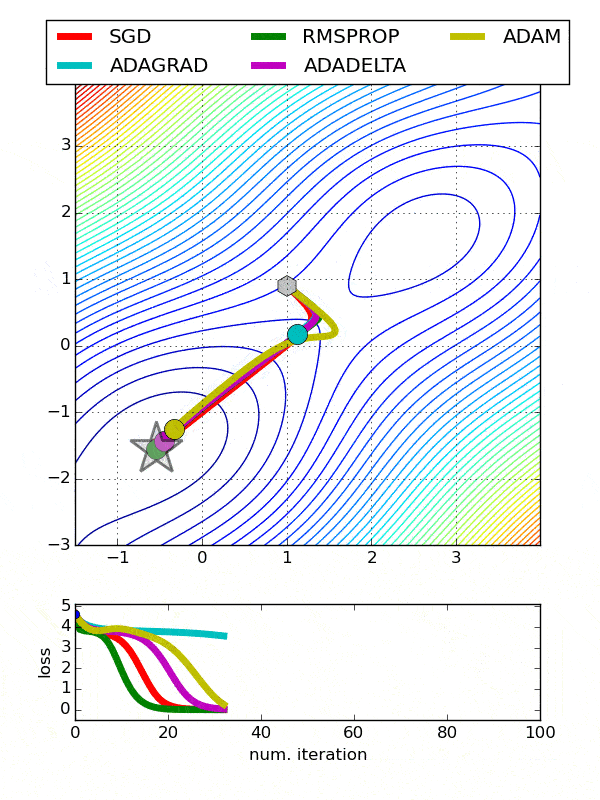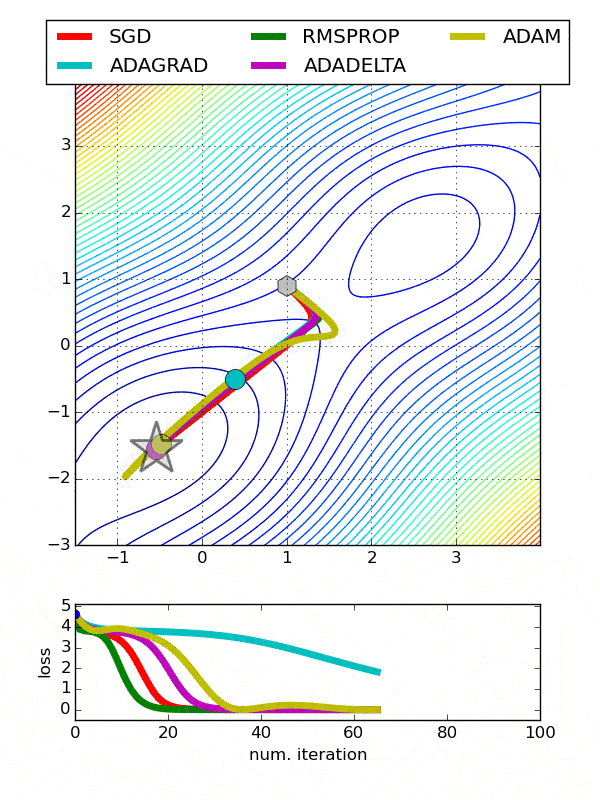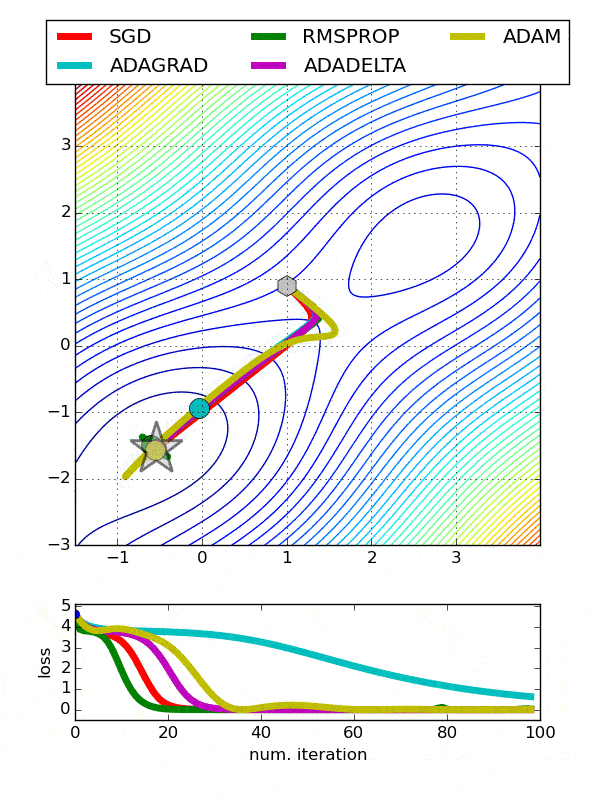
Conclusion
In this article, we explained Keras Optimizers with its different types. We also covered the syntax and examples of different types of optimizers available in Keras. We hope this article was useful to you.
Reference Keras Documentation

