
In this tutorial, we will be going to cover the understanding of Spacy tokenizer for beginners with examples We will give you a brief understanding of tokenization in natural language processing and then show you how to perform tokenization in the Spacy library. We will cover various examples including custom tokenizer, third party tokenizer, sentence tokenizer, etc.
- Also Read – Complete Guide to NLTK Tokenization
Tokenization is the task of splitting a text into small segments, called tokens. The tokenization can be at the document level to produce tokens of sentences or sentence tokenization that produces tokens of words or word tokenization that produces tokens of characters.
The tokenizer is usually the initial step of the text preprocessing pipeline and works as input for subsequent NLP operations like stemming, lemmatization, text mining, text classification, etc.
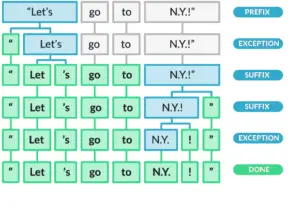
Spacy Tokenizers
In Spacy, the process of tokenizing a text into segments of words and punctuation is done in various steps. It processes the text from left to right.
- First, the tokenizer split the text on whitespace similar to the split() function.
- Then the tokenizer checks whether the substring matches the tokenizer exception rules. For example, “don’t” does not contain whitespace, but should be split into two tokens, “do” and “n’t”, while “U.K.” should always remain one token.
- Next, it checks for a prefix, suffix, or infix in a substring, these include commas, periods, hyphens, or quotes. If it matches, the substring is split into two tokens.
In the example below, we are tokenizing the text using spacy. First, we imported the Spacy library and then loaded the English language model of spacy and then iterate over the tokens of doc objects to print them in the output.
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("You only live once, but if you do it right, once is enough.")
for token in doc:
print(token.text)
Creating Tokenizer
In spacy we can add our own created tokenizer in the pipeline very easily. For example in the code below we are adding the blank Tokenizer with just the English vocab.
# Construction 1
from spacy.tokenizer import Tokenizer
from spacy.lang.en import English
nlp = English()
# Creating a blank Tokenizer with just the English vocab
tokenizer = Tokenizer(nlp.vocab)
tokens = tokenizer("Let's go to N.Y.")
print("Blank tokenizer",end=" : ")
for token in tokens:
print(token,end=', ')
# Construction 2
from spacy.lang.en import English
nlp = English()
# Creating a Tokenizer with the default settings for English
tokenizer = nlp.tokenizer
tokens = tokenizer("Let's go to N.Y.")
print("\nDefault tokenizer",end=' : ')
for token in tokens:
print(token,end=', ')
Adding Special Rule
In some cases, we need to customize our tokenization rules. This could be an expression or an abbreviation for example if we have ViratKohli in our text and we need to split it (Virat Kholi) during tokenization. This could be done by adding a special rule to an existing Tokenizer rule.
import spacy
from spacy.symbols import ORTH
nlp = spacy.load("en_core_web_sm")
doc = nlp("ViratKholi is the worlds best bastman") # phrase to tokenize
print("Normal tokenization : ",end=' ')
for token in doc:
print(token,end=', ')
special_case = [{ORTH: "Virat"}, {ORTH: "Kholi"}] # Adding special case rule
nlp.tokenizer.add_special_case("ViratKholi", special_case)
doc = nlp("ViratKholi is the worlds best bastman")
print("\nSpecial case tokenization : ",end=' ')
for token in doc: # Checking new tokenization
print(token,end=', ')
Debugging the Tokenizer
A debugging tool was provided by spacy library as nlp.tokenizer.explain(text) which return returns a list of tuples containing token itself and the rules on which it was tokenized.
from spacy.lang.en import English
nlp = English()
text = "Let's move to L.A."
doc = nlp(text)
tok_exp = nlp.tokenizer.explain(text)
for t in tok_exp:
print(t[1], "\t", t[0])
Customizing Spacy Tokenizer
In Spacy, we can create our own tokenizer with our own customized rules. For example, if we want to create a tokenizer for a new language, this can be done by defining a new tokenizer method and adding rules of tokenizing to that method. These rules are prefix searches, infix searches, postfix searches, URL searches, and defining special cases. The below code is an example of creating a tokenizer class.
import re
import spacy
from spacy.tokenizer import Tokenizer
special_cases = {":)": [{"ORTH": ":)"}]}
prefix_re = re.compile(r'''^[\[\("']''')
suffix_re = re.compile(r'''[\]\)"']$''')
infix_re = re.compile(r'''[-~]''')
simple_url_re = re.compile(r'''^https?://''')
def custom_tokenizer(nlp):
return Tokenizer(nlp.vocab, rules=special_cases,
prefix_search=prefix_re.search,
suffix_search=suffix_re.search,
infix_finditer=infix_re.finditer,
url_match=simple_url_re.match)
nlp = spacy.load("en_core_web_sm")
nlp.tokenizer = custom_tokenizer(nlp)
doc = nlp("hello-world. :)")
print([t.text for t in doc])
Modifying Existing Rules of Tokenizer
In spacy, we can also modify existing rules of tokenizer by adding or removing the character from the prefix, suffix, or infix rules with the help of NLP’s Default object.
i) Adding characters in the suffixes search
In the code below we are adding ‘+’, ‘-‘ and ‘$’ to the suffix search rule so that whenever these characters are encountered in the suffix, could be removed.
from spacy.lang.en import English
import spacy
nlp = English()
text = "This is+ a- tokenizing$ sentence."
doc = nlp(text)
print("Default tokenized text",end=' : ')
for token in doc:
print(token,end=', ')
suffixes = nlp.Defaults.suffixes + [r"\-|\+|\$",]
suffix_regex = spacy.util.compile_suffix_regex(suffixes)
nlp.tokenizer.suffix_search = suffix_regex.search
print('\nText after adding suffixes', end=' : ')
doc = nlp(text)
for token in doc:
print(token,end=', ')
ii) Removing characters from the suffix search
As we have added suffixes in our suffix rule, similarly we can remove some suffixes from our suffix rule. For example, we are removing the suffix tokenization ‘(‘ from the suffix rule.
from spacy.lang.en import English
import spacy
nlp = English()
text = "This is a (tokenizing) sentence."
doc = nlp(text)
print("Default tokenized text",end=' : ')
for token in doc:
print(token,end=', ')
suffixes = list(nlp.Defaults.suffixes)
suffixes.remove("\(")
suffix_regex = spacy.util.compile_suffix_regex(suffixes)
nlp.tokenizer.suffix_search = suffix_regex.search
print('\nText after removing suffixes', end=' : ')
doc = nlp(text)
for token in doc:
print(token,end=', ')
Adding a Custom Tokenizing Class
We can customize the tokenizing class of an nlp doc’s object. This can be done by creating a tokenizer class and assigning it to nlp.tokenize.For example, we can add a basic white space tokenizer to our tokenizer object.
import spacy
from spacy.tokens import Doc
class WhitespaceTokenizer:
def __init__(self, vocab):
self.vocab = vocab
def __call__(self, text):
words = text.split(" ")
return Doc(self.vocab, words=words)
nlp = spacy.blank("en")
nlp.tokenizer = WhitespaceTokenizer(nlp.vocab)
doc = nlp("The purpose of our lives is to be happy.")
print([token.text for token in doc])
Third-party Tokenizers (BERT word pieces)
We can also add any other third-party tokenizers. In the example below, we used BERT word piece tokenizer provided by the tokenizers library.
from tokenizers import BertWordPieceTokenizer
from spacy.tokens import Doc
import spacy
class BertTokenizer:
def __init__(self, vocab, vocab_file, lowercase=True):
self.vocab = vocab
self._tokenizer = BertWordPieceTokenizer(vocab_file, lowercase=lowercase)
def __call__(self, text):
tokens = self._tokenizer.encode(text)
words = []
spaces = []
for i, (text, (start, end)) in enumerate(zip(tokens.tokens, tokens.offsets)):
words.append(text)
if i < len(tokens.tokens) - 1:
# If next start != current end we assume a space in between
next_start, next_end = tokens.offsets[i + 1]
spaces.append(next_start > end)
else:
spaces.append(True)
return Doc(self.vocab, words=words, spaces=spaces)
nlp = spacy.blank("en")
nlp.tokenizer = BertTokenizer(nlp.vocab, "bert-base-uncased-vocab.txt")
doc = nlp("Justin Drew Bieber is a Canadian singer, songwriter, and actor.")
print(doc.text, '\n', [token.text for token in doc])
Merging and Splitting of Tokens
We can merge or split our tokens during the process of tokenization by using Doc.retokenize context manager. Modifications in the tokenization are stored and performed all at once when the context manager exits.
To merge several tokens into one single token, pass a Span to tokenizer.merge.
i) Merging Tokens
We can merge several tokens to a single token by passing a span of doc to tokenizer.merge. An optional dictionary of attrs lets us set attributes that will be assigned to the merged token – for example, the lemma, part-of-speech tag, or entity type. By default, the merged token will receive the same attributes as the merged span’s root.
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("I live in New York")
print("Before:", [token.text for token in doc])
with doc.retokenize() as retokenizer:
retokenizer.merge(doc[3:5], attrs={"LEMMA": "new york"})
print("After:", [token.text for token in doc])
ii) Splitting Tokens
We can split a token into two or more tokens using retokenizer.split method. For example, if we want to split ‘NarendraModi’ into two ‘Narendra’ and ‘Modi’, we can apply this rule.
import spacy
from spacy import displacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("PM NarendraModi is our prime minister")
print("Before:", [token.text for token in doc])
with doc.retokenize() as retokenizer:
heads = [(doc[1], 0), (doc[1], 1)]
retokenizer.split(doc[1], ["Narendra", "Modi"], heads=heads)
print("After:", [token.text for token in doc])
Sentence Tokenization
Sentence tokenization is the process of splitting sentences of a text. We can iterate over the sentences by using Doc.sents. We can check whether a Doc has sentence boundaries by calling Doc.has_annotation with the attribute name “SENT_START”.
The below code is an example of splitting a text into sentences.
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("This is a sentence. This is another sentence.")
print(doc.has_annotation("SENT_START"))
for sent in doc.sents:
print(sent.text)
However, SpaCy has provided four methods to tokenize a sentence. These are :
- Dependency parser method
- Statistical sentence segmenter method
- Rule-based pipeline component method
- Custom function method
i) Default: Using the Dependency Parse
The spaCy library uses the full dependency parse to determine sentence boundaries. This is usually the most accurate approach and is the default sentence segmenter, but it requires a trained pipeline that provides accurate predictions. This method works with excellent accuracy if our text is closer to general-purpose news or web text.
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("This is a sentence. This is another sentence.")
for sent in doc.sents:
print(sent.text)
ii) Statistical Sentence Segmenter
The statistical SentenceRecognizer is a simpler and faster alternative to the parser that only provides sentence boundaries. It is easier to train because it only requires annotated sentence boundaries rather than full dependency parses.
import spacy
nlp = spacy.load("en_core_web_sm", exclude=["parser"])
nlp.enable_pipe("senter")
doc = nlp("This is a sentence. This is another sentence.")
for sent in doc.sents:
print(sent.text)
iii) Rule-based Pipeline Component
The rule-based Sentencizer sets sentence boundaries using a customizable list of sentence-final punctuation like ., ! or ?.
import spacy
from spacy.lang.en import English
nlp = English() # just the language with no pipeline
nlp.add_pipe("sentencizer")
doc = nlp("This is a sentence. This is another sentence.")
for sent in doc.sents:
print(sent.text)
iv) Custom Rule-Based Strategy
If we want to implement our own strategy that differs from the default rule-based approach of splitting sentences, we can also create a custom pipeline component that takes a Doc object and sets the Token.is_sent_start attribute on each individual token.
from spacy.language import Language
import spacy
text = "this is a sentence...hello...and another sentence."
nlp = spacy.load("en_core_web_sm")
doc = nlp(text)
print("Before:", [sent.text for sent in doc.sents])
@Language.component("set_custom_boundaries")
def set_custom_boundaries(doc):
for token in doc[:-1]:
if token.text == "...":
doc[token.i + 1].is_sent_start = True
return doc
nlp.add_pipe("set_custom_boundaries", before="parser")
doc = nlp(text)
print("After:", [sent.text for sent in doc.sents])
- Also Read – Complete Guide to NLTK Tokenization

