
In NLP, the pipeline is the concept of integrating various text processing components together such that, the output of one component serves as the input for the next component. Spacy provides built-in functionality of pipelines that can be set up quite easily. In this tutorial, we will take you through the features of the Spacy NLP Pipeline along with examples.
Spacy NLP Pipeline
Spacy NLP pipeline lets you integrate multiple text processing components of Spacy, whereas each component returns the Doc object of the text that becomes an input for the next component in the pipeline.
We can easily play around with the Spacy pipeline by adding, removing, disabling, replacing components as per our needs. Moreover, you can also customize the pipeline components if required.
Spacy NLP Pipeline Components
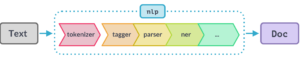
The default components of a trained pipeline include tagger, lemmatizer, parser, and entity recognizers. We can improve the efficiency of this pipeline process by only enabling those components which are needed or by processing the texts as a stream using nlp.pipe and buffer them in batches, instead of one-by-one.
We can initialize them by calling nlp.add_pipe with their names and Spacy will automatically add them to the nlp pipeline. Below is the list of different NLP components and their description.
Below are the components that are available in Spacy Pipeline.
Adding Custom Attributes
In Spacy, we can add metadata in the context and save it in custom attributes using nlp.pipe. This could be done by passing the text and its context in tuples form and passing a parameter astuples=True. The output will be a sequence of doc and context. In the example below, we are passing a list of texts along with some custom attributes to nlp.pipe and setting those attributes to the doc using doc.
import spacy
from spacy.tokens import Doc
if not Doc.has_extension("text_id"):
Doc.set_extension("text_id", default=None)
text_tuples = [("This is the first text.", {"text_id": "text1"}),
("This is the second text.", {"text_id": "text2"})]
nlp = spacy.load("en_core_web_sm")
doc_tuples = nlp.pipe(text_tuples, as_tuples=True)
docs = []
for doc, context in doc_tuples:
doc._.text_id = context["text_id"]
docs.append(doc)
for doc in docs:
print(f"{doc._.text_id}: {doc.text}")
Multiprocessing
Spacy has provided a built-in multiprocessing option with nlp.pipe using the n_process. This will greatly increase the performance of the nlp pipeline. We can use this to make it a multiprocessing task or also make it multiprocessing with as many processes as CPUs can afford by passing n_process=-1 to nlp.pipe.
However, this should be used with caution. We can also set our own batch_size in the nlp pipeline which is 1000 by default. For shorter tasks, it can be faster to use a smaller number of processes with a larger batch size. The optimal batch_size setting will depend on the pipeline components, the length of your documents, the number of processes, and how much memory is available.
docs = nlp.pipe(texts, n_process=4, batch_size=2000)
Spacy Pipeline Under the Hood
Spacy pipeline package consists of three components: the weights, i.e. binary data loaded in from a directory, a pipeline of functions called in order, and language data like the tokenization rules and language-specific settings. A Spanish NER pipeline requires different weights, language data, and components than an English parsing and tagging pipeline.
This is also why the pipeline state is always held by the Language class. spacy.load puts this all together and returns an instance of Language with a pipeline set and access to the binary data.
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp(text)
When we load a pipeline, Spacy first consults the meta.json and config.cfg. The config tells Spacy what language class to use, which components are in the pipeline, and how those components should be created.
- Load the language class and data for the given ID via get_lang_class and initialize it. The Language class contains the shared vocabulary, tokenization rules, and language-specific settings.
- Iterate over the pipeline names and look up each component name in the [components] block. The factory tells Spacy which component factory to use for adding the component with add_pipe. The settings are passed into the factory.
- Make the model data available to the Language class by calling from_disk with the path to the data directory.
Sample CONFIG.CFG
The pipeline’s config.cfg tells Spacy to use the language “en” and the pipeline [“tok2vec”, “tagger”, “parser”, “ner”, “attribute_ruler”, “lemmatizer”]. Spacy will then initialize spacy.lang.en.English, and create each pipeline component and add it to the processing pipeline. It’ll then load in the model data from the data directory and return the modified Language class for you to use as the nlp object.
lang = "en"
pipeline = ["tok2vec", "parser"]
factory = "tok2vec" # Settings for the tok2vec component
factory = "parser" # Settings for the parser component
Spacy first tokenizes the text, loads the model data, and then calls each component in order. The component then accesses the model data to assign annotations to Doc object, token, or to the span of doc object.
The modified document returned by a component is passed to the next component for processing in the pipeline. The output from one component serves as the input for another component for example part of speech tag assigned to a token server as input data for lemmatizer. However, some of the components work independently such as tagger and parser, and don’t require data from any other components.
doc = nlp.make_doc("This is a sentence") # Create a Doc from raw text
for name, proc in nlp.pipeline: # Iterate over components in order
doc = proc(doc) # Apply each component
When can get the list of processing pipelines with the help of nlp.pipeline which returns a list of tuples containing component name and component itself. Whereas nlp.pipe_names returns all the component’s names.
print(nlp.pipeline)
print(nlp.pipe_names)
Customizing Pipeline
In Spacy, we can customize our NLP pipeline. That is we can add, disable, exclude and modify components in the pipeline. This could make a big difference in processed text and will improve loading and inference speed. For example, if we don’t need a tagger or parser we can disable or exclude them from the pipeline.
Disable Component
We can disable the pipeline component while loading the pipeline by using disable keyword. It will be included but disabled by default. The component and its data will be loaded with the pipeline, but it will be disabled and not run as part of the processing pipeline. However, we can explicitly enable it when needed by calling nlp.enable_pipe.
For example, the trained Spacy pipeline ‘en_core_web_sm’ contains both a parser and senter that perform sentence segmentation, but the senter is disabled by default.
import spacy
nlp = spacy.load("en_core_web_sm", disable=["tagger", "parser"]) # Loading the tagger and parser but don't enable them.
doc = nlp("This sentence wouldn't be tagged and parsed")
nlp.enable_pipe("tagger") # Explicitly enabling the tagger later on.
doc = nlp("This sentence will only be tagged")
We can use the nlp.select_pipes context manager to temporarily disable certain components for a given block. The select_pipes returns an object that lets us call its restore() method to restore the disabled components when needed. This could be useful if we want to prevent unnecessary code indentation of large blocks.
import spacy
disabled = nlp.select_pipes(disable=["tagger", "parser"])
disabled.restore()
doc = nlp("This senetence will be tagged as well as parsed")
If we want to disable all pipes except for one or a few, we can use the enable keyword.
import spacy
nlp=spacy.load(enable="parser") # Enable only the parser
doc = nlp("This sentence will only be parsed")
Exclude Components
In Spacy, we can also exclude a component by passing exclude keyword along with the list of excluded components. Unlike diable, it will not load the component and its data with the pipeline. Once the pipeline is loaded, there will be no reference to the excluded or include any components.
import spacy
nlp = spacy.load("en_core_web_sm", exclude=["ner"]) # Load the pipeline without the entity recognizer
doc = nlp("NER will be excluded from the pipeline")
We can also use the remove_pipe method to remove pipeline components from an existing pipeline, the rename_pipe method to rename them, or the replace_pipe method to replace them with a custom component entirely.
nlp.remove_pipe("parser")
nlp.rename_pipe("ner", "entityrecognizer")
nlp.replace_pipe("tagger", "my_custom_tagger")
| Argument | Description |
|---|---|
| nlp.pipeline | Returns tuples of component name and component of the processing pipeline, in order. |
| nlp.pipe_names | Returns pipeline component names, in order. |
| nlp.components | Returns tuples of all component names and components, including disabled components. |
| nlp.component_names | Returns all component names, including disabled components. |
| nlp.disabled | Returns names of components that are currently disabled. |
Analyzing Components
In Spacy we can analyze the pipeline components using the nlp.analyze method which returns information about the components such as the attributes they set on the Doc and Token, whether they retokenize the Doc and which scores they produce during training. It will also show warnings if components require values that aren’t set by the previous component – for instance if the entity linker is used but no component that runs before it sets named entities. Setting pretty=True will pretty-print a table instead of only returning the structured data.
import spacy
nlp = spacy.blank("en")
nlp.add_pipe("tagger")
# This is a problem because it needs entities and sentence boundaries
nlp.add_pipe("entity_linker")
analysis = nlp.analyze_pipes()
print("output 1:")
print(analysis)
analysis = nlp.analyze_pipes(pretty=True)
print("Output 2:")
print(analysis)
Output 1:
{
"summary": {
"tagger": {
"assigns": ["token.tag"],
"requires": [],
"scores": ["tag_acc", "pos_acc", "lemma_acc"],
"retokenizes": false
},
"entity_linker": {
"assigns": ["token.ent_kb_id"],
"requires": ["doc.ents", "doc.sents", "token.ent_iob", "token.ent_type"],
"scores": [],
"retokenizes": false
}
},
"problems": {
"tagger": [],
"entity_linker": ["doc.ents", "doc.sents", "token.ent_iob", "token.ent_type"]
},
"attrs": {
"token.ent_iob": { "assigns": [], "requires": ["entity_linker"] },
"doc.ents": { "assigns": [], "requires": ["entity_linker"] },
"token.ent_kb_id": { "assigns": ["entity_linker"], "requires": [] },
"doc.sents": { "assigns": [], "requires": ["entity_linker"] },
"token.tag": { "assigns": ["tagger"], "requires": [] },
"token.ent_type": { "assigns": [], "requires": ["entity_linker"] }
}
}
Output 2:
============================= Pipeline Overview =============================
# Component Assigns Requires Scores Retokenizes
- ------------- --------------- -------------- ----------- -----------
0 tagger token.tag tag_acc False
1 entity_linker token.ent_kb_id doc.ents nel_micro_f False
doc.sents nel_micro_r
token.ent_iob nel_micro_p
token.ent_type
================================ Problems (4) ================================
⚠ 'entity_linker' requirements not met: doc.ents, doc.sents,
token.ent_iob, token.ent_type
Creating Custom Components
In Spacy we can create our own custom pipeline component and add it to the nlp pipeline. We create a pipeline component like any other function except first describe the function as a pipeline component using @Language.component decorator. This pipeline component will be listed in the pipeline config to save, load, and train pipeline using our component. The custom components can be added to the pipeline using the add_pipe method. we can also specify the component position in the pipeline list.
import spacy
nlp= spacy.load("en_core_web_sm")
@Language.component("my_component") # creating component.
def my_component(doc):
# Do something to the doc here
return doc
nlp.add_pipe("my_component", first=True) # adding it to the pipeline.
nlp.add_pipe("my_component", before="parser")
| Argument | Description |
|---|---|
| last | If set to True, the component is added last in the pipeline. By default, components are added in the last. |
| first | If set to True, the component is added first in the pipeline. |
| before | Takes String name or index to add the new component before. |
| after | String name or index to add the new component after. |
- Also Read – Tutorial for Stopwords in Spacy Library
- Also Read – Complete Guide to Spacy Tokenizer with Examples
Reference – Spacy Documentation

