
Introduction:
In today’s tutorial, we will look at how we can deal with missing values in a dataset by using Sklearn Simple Imputer. In the real world, we will always encounter data sets that have missing values because of many reasons. Missing data is essentially a piece of missing information and it becomes very important how you deal with it for your machine learning model. There are multiple techniques of how to address the missing data and they can be easily implemented by using SimpleImputer module of Sklearn.
We will first understand what does missing data really means what are its different types of characteristics. Then we will understand the various strategies of imputing such missing data and then see examples of Simple Imputer of Scikit Learn.
What is a Missing Data
As the name suggests when the value of an attribute is missing in the dataset it is called missing value. Handling these missing values is very tricky for data scientists because any wrong treatment of these missing values can end up compromising the accuracy of the machine learning model.
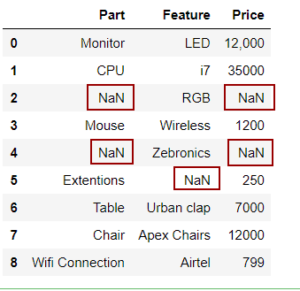
Types of Missing Data
1. Missing at Random (MAR)
2. Missing Completely at Random (MCAR)
3. Missing Not at Random (MNAR)
In this scenario, the data is not missing randomly and the missingness is attributed to the data that was supposed to be captured. MNAR is quite tricky to spot and deal with. E.g. in a survey form, the rich people may not fill the Income field as they would not like to disclose it.
How to Deal with Missing Data
There are various strategies available to address the issue of the missing data however which one works best depends on your dataset. There is no thumb rule, so you will have to assess your dataset and experiment with various strategies.
1. Dropping the Variables with Missing Data
In this strategy, the row or column containing the missing data is deleted completely. This should be used cautiously as you may end up losing important information about the data. Domain knowledge is quite useful to decide whether dropping the columns is the ideal solution for your dataset.
2. Imputation of Data
In this technique, the missing data is filled up or imputed by a suitable substitute and there are multiple strategies behind it.
i) Replace with Mean
Here all the missing data is replaced by the mean of the corresponding column. It works only with a numeric field. However, we have to be cautious here because if the data in the column contains outliers its mean will be misleading
ii) Replace with Median
Here the missing data is replaced with the median values of that column and again it is applicable only with numerical columns.
iii) Replace with Most Frequent Occurring
In this technique, the missing values are filled with the value which occurs the highest number of times in a particular column. This approach is applicable for both numeric and categorical columns.
iv) Replace with Constant
In this approach, the missing data is replaced by a constant value throughout. This can be used with both numeric and categorical columns.
Sklearn Simple Imputer
Sklearn provides a module SimpleImputer that can be used to apply all the four imputing strategies for missing data that we discussed above.
Sklearn Imputer vs SimpleImputer
The old version of sklearn used to have a module Imputer for doing all the imputation transformation. However, the Imputer module is now deprecated and has been replaced by a new module SimpleImputer in the recent versions of Sklearn. So for all imputation purposes, you should now use SimpleImputer in Sklearn.
Examples of Simple Imputer in Sklearn
Create Toy Dataset
We will create a toy dataset with the random numbers and then randomly set some values as nulls. Just to make this dataset more suitable for our examples, we duplicate two cells of the datframes.
In [1]:
# Create a radnom datset of 10 rows and 4 columns df = pd.DataFrame(np.random.randn(10, 4), columns=list('ABCD')) # Randomly set some values as null df = df.mask(np.random.random((10, 4)) < .15) # Duplicate two cells with same values df['B'][8] = df['B'][9] df
Out[1]:
| A | B | C | D | |
|---|---|---|---|---|
| 0 | -0.520643 | NaN | 0.080238 | NaN |
| 1 | 1.225041 | 0.505089 | -1.997088 | NaN |
| 2 | -0.004976 | -0.082857 | 0.376651 | -0.626456 |
| 3 | 1.880424 | 0.527540 | 0.129820 | 1.384916 |
| 4 | -0.476005 | NaN | -1.499829 | 0.334039 |
| 5 | 2.134381 | -0.365297 | 1.554248 | -0.118477 |
| 6 | 0.103352 | 0.458311 | 0.424156 | NaN |
| 7 | -0.759686 | -0.356959 | 1.261324 | -0.278455 |
| 8 | -0.331476 | 0.810893 | -0.466366 | -0.582135 |
| 9 | -1.991735 | -0.343604 | -0.393095 | -1.190406 |
i) Sklearn SimpleImputer with Mean
We first create an instance of SimpleImputer with strategy as ‘mean’. This is the default strategy and even if it is not passed, it will use mean only. Finally, the dataset is fit and transformed and we can see that the null values of columns B and D are replaced by the mean of respective columns.
In [2]:
mean_imputer = SimpleImputer(strategy='mean')
result_mean_imputer = mean_imputer.fit_transform(df)
pd.DataFrame(result_mean_imputer, columns=list('ABCD'))
| A | B | C | D | |
|---|---|---|---|---|
| 0 | -0.520643 | -0.000173 | 0.080238 | -0.153853 |
| 1 | 1.225041 | 0.505089 | -1.997088 | -0.153853 |
| 2 | -0.004976 | -0.082857 | 0.376651 | -0.626456 |
| 3 | 1.880424 | 0.527540 | 0.129820 | 1.384916 |
| 4 | -0.476005 | -0.000173 | -1.499829 | 0.334039 |
| 5 | 2.134381 | -0.365297 | 1.554248 | -0.118477 |
| 6 | 0.103352 | 0.458311 | 0.424156 | -0.153853 |
| 7 | -0.759686 | -0.356959 | 1.261324 | -0.278455 |
| 8 | -0.331476 | -0.343604 | -0.466366 | -0.582135 |
| 9 | -1.991735 | -0.343604 | -0.393095 | -1.190406 |
ii) Sklearn SimpleImputer with Median
We first create an instance of SimpleImputer with strategy as ‘median’ and then the dataset is fit and transformed. We can see that the null values of columns B and D are replaced by the mean of respective columns.
In [3]:
median_imputer = SimpleImputer(strategy='median')
result_median_imputer = median_imputer.fit_transform(df)
pd.DataFrame(result_median_imputer, columns=list('ABCD'))
| A | B | C | D | |
|---|---|---|---|---|
| 0 | -0.520643 | -0.213231 | 0.080238 | -0.278455 |
| 1 | 1.225041 | 0.505089 | -1.997088 | -0.278455 |
| 2 | -0.004976 | -0.082857 | 0.376651 | -0.626456 |
| 3 | 1.880424 | 0.527540 | 0.129820 | 1.384916 |
| 4 | -0.476005 | -0.213231 | -1.499829 | 0.334039 |
| 5 | 2.134381 | -0.365297 | 1.554248 | -0.118477 |
| 6 | 0.103352 | 0.458311 | 0.424156 | -0.278455 |
| 7 | -0.759686 | -0.356959 | 1.261324 | -0.278455 |
| 8 | -0.331476 | -0.343604 | -0.466366 | -0.582135 |
| 9 | -1.991735 | -0.343604 | -0.393095 | -1.190406 |
iii) Sklearn SimpleImputer with Most Frequent
We first create an instance of SimpleImputer with strategy as ‘most_frequent’ and then the dataset is fit and transformed.
If there is no most frequently occurring number Sklearn SimpleImputer will impute with the lowest integer on the column.
We can see that the null values of column B are replaced with -0.343604 that is the most frequently occurring in that column. In column D since there is no such frequently occurring number the nulls got replaced by the lowest number -1.190406
In [4]:
most_frequent_imputer = SimpleImputer(strategy='most_frequent')
result_most_frequent_imputer = most_frequent_imputer.fit_transform(df)
pd.DataFrame(result_most_frequent_imputer, columns=list('ABCD'))
| A | B | C | D | |
|---|---|---|---|---|
| 0 | -0.520643 | -0.343604 | 0.080238 | -1.190406 |
| 1 | 1.225041 | 0.505089 | -1.997088 | -1.190406 |
| 2 | -0.004976 | -0.082857 | 0.376651 | -0.626456 |
| 3 | 1.880424 | 0.527540 | 0.129820 | 1.384916 |
| 4 | -0.476005 | -0.343604 | -1.499829 | 0.334039 |
| 5 | 2.134381 | -0.365297 | 1.554248 | -0.118477 |
| 6 | 0.103352 | 0.458311 | 0.424156 | -1.190406 |
| 7 | -0.759686 | -0.356959 | 1.261324 | -0.278455 |
| 8 | -0.331476 | -0.343604 | -0.466366 | -0.582135 |
| 9 | -1.991735 | -0.343604 | -0.393095 | -1.190406 |
iv) Sklearn SimpleImputer with Constant
We first create an instance of SimpleImputer with strategy as ‘constant’ and fill_value as 99. If we don’t supply fill_value it will take 0 as default for numerical columns. Also in a numeric column, SimpleImputer does not accept a string for default fill.
The dataset is fit and transformed and we can see that all nulls are replaced by 99.
In [5]:
constant_imputer = SimpleImputer(strategy='constant',fill_value=99)
result_constant_imputer = constant_imputer.fit_transform(df)
pd.DataFrame(result_constant_imputer, columns=list('ABCD'))
| A | B | C | D | |
|---|---|---|---|---|
| 0 | -0.520643 | 99.000000 | 0.080238 | 99.000000 |
| 1 | 1.225041 | 0.505089 | -1.997088 | 99.000000 |
| 2 | -0.004976 | -0.082857 | 0.376651 | -0.626456 |
| 3 | 1.880424 | 0.527540 | 0.129820 | 1.384916 |
| 4 | -0.476005 | 99.000000 | -1.499829 | 0.334039 |
| 5 | 2.134381 | -0.365297 | 1.554248 | -0.118477 |
| 6 | 0.103352 | 0.458311 | 0.424156 | 99.000000 |
| 7 | -0.759686 | -0.356959 | 1.261324 | -0.278455 |
| 8 | -0.331476 | -0.343604 | -0.466366 | -0.582135 |
| 9 | -1.991735 | -0.343604 | -0.393095 | -1.190406 |

