
Introduction
Ensemble learning is one of the most popular approaches used in machine learning competition nowadays. The top-ranking people on the competition list are preferring ensemble learning more and more. And surely, even outside the competitive arena, ensemble learning has emerged as a very powerful tool among industry professionals.
In this post, we will give a gentle introduction to ensemble learning and discuss its different variations. And most importantly we will understand why it is so powerful.
Intuition behind Ensemble Learning
Real Life Situation
So imagine, that a person falls sick and he goes to a doctor. The doctor on evaluating him concludes he has a tumor. One of the obvious response would be that the person will consult a few more doctors to take their opinion on his medical condition. In doing so the person has the following advantage –
- The diagnosis of a single doctor might not be correct always. So more validation is better.
- The same opinion from multiple doctors gives more affirmation on the diagnosis.
- In a complicated situation, if multiple doctors have conflicting opinions then generally the opinion of the majority of doctors is most likely to be correct.
- The different opinions of multiple doctors can give a combined strong opinion.
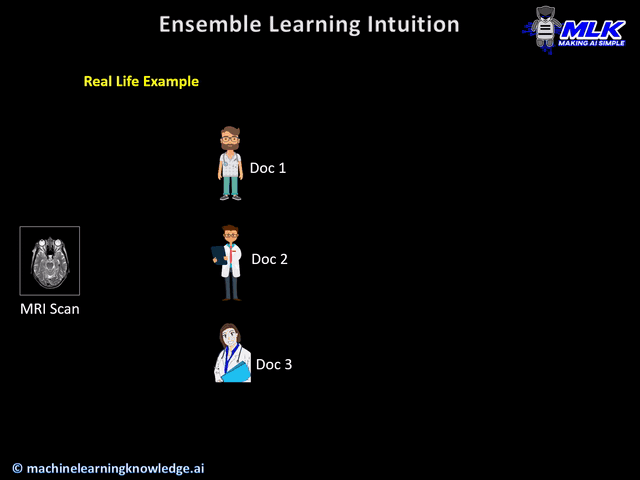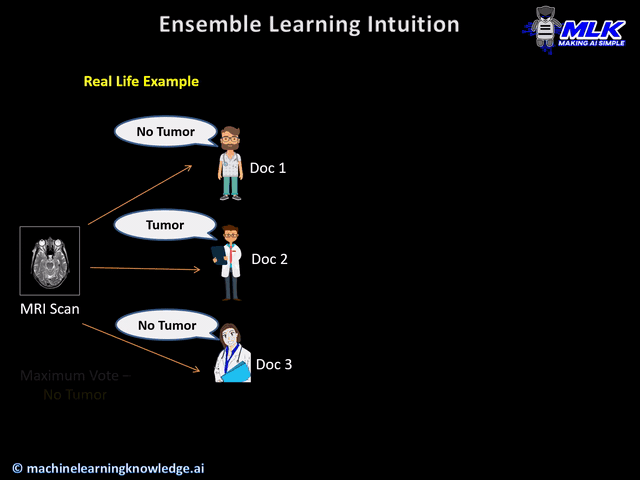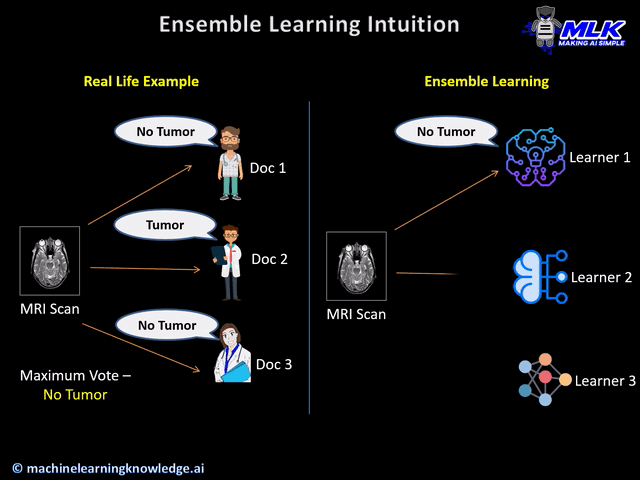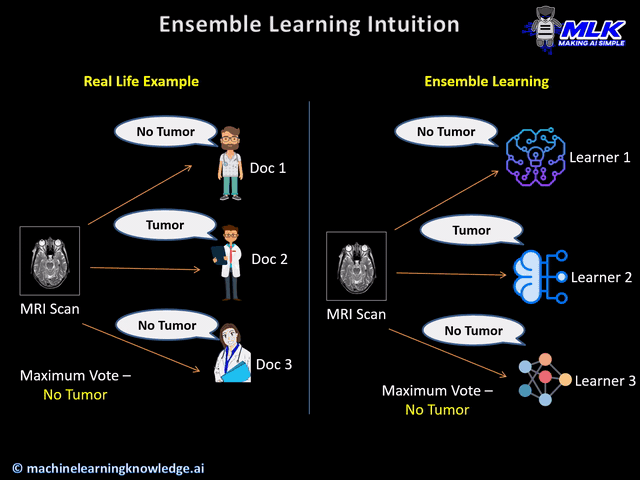
This real-life situation shows that collective opinions from multiple experts are more reliable than the individual’s opinion.
And this forms the ideology of ensemble learning.
Ensemble Learning
Ensemble Learning is a paradigm of machine learning in which multiple learners are combined together to form a much more powerful learner.
Individual learners, also known as base learners can have a high bias or high variance or both, which is not good. Such learners are known as weak learners. But when these weak learners are combined together it can produce a strong learner having low bias and low variance.
Base Learners
In order to create an ensemble learning model, the base learners should be different from one another and hence should produce a different hypothesis.
There can be many ways by which we can introduce diversity in base learners. Some of the straight forward methods are –
Different Algorithms
Base learners can be created from different algorithms. For example, one learner can be using a decision tree, another learner might be using a neural network, the third might be using some another model and so on.
Such set up of base learners is also known as heterogeneous learners.
Different hyperparameters
In this case, base learners can be created from the same algorithm but each learner uses different parameters. For example, all base learners might be using a neural network algorithm. But one learner might be using 3 neurons in the hidden layer, another learner might be having 5 neurons in the hidden layer. The third learner might be having more hidden layers than others and so on.
Such set up of base learners is also known as homogeneous learners.
Different Training Data
In this setup, the base learners are trained on different training data and hence they create a different hypothesis from each other. When we say different training data we actually mean learners are trained on different subsets of original training data.
All these base learners can be trained in parallel or in a sequential manner before their hypothesis can be combined.
[adrotate banner=”3″]
Types of Ensemble Learning (Popular Ones)
Currently, there are two popular ensemble learning methods that are widely used-
- Bagging (Bootstrap Aggregation)
- Boosting
1.Bagging (Bootstrap Aggregation)
Bagging, also known as Bootstrap Aggregation is an Ensemble Learning technique that has two parts – i) Bootstrap and ii) Aggregation.
Bootstrap
Bootstrap is a technique of random sampling of data with replacement. In the ensemble learning context, we prepare multiple training sets by this bootstrap method.
Just to give an example, if we have a data set (a,b,c,d,e,f,g,h,i,j) then we can get following training set using bootstrap –
(a,f,d,j,h,c) (b,g,a,i,c,f) (i,d,c,e,a,d) (b,h,g,h,a,b)
Notice, that the same data can appear multiple times in the training set, since we are doing random sampling with replacement.
Aggregation
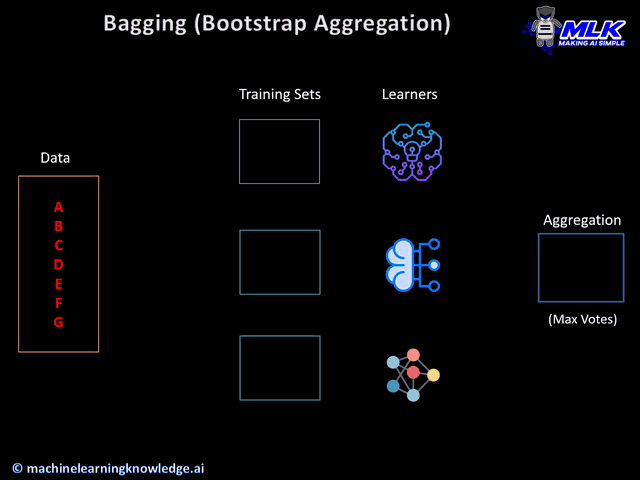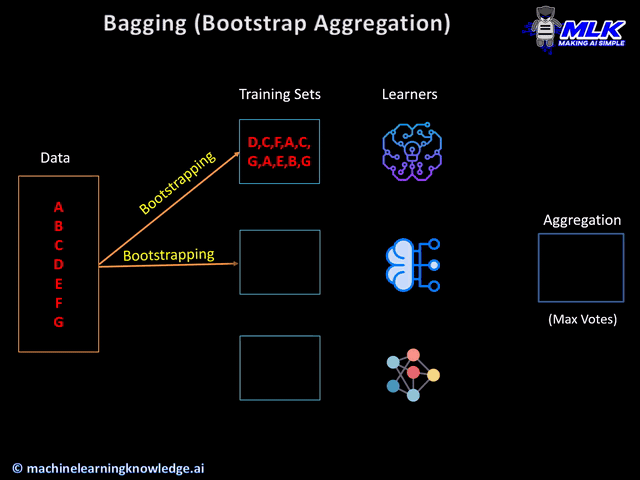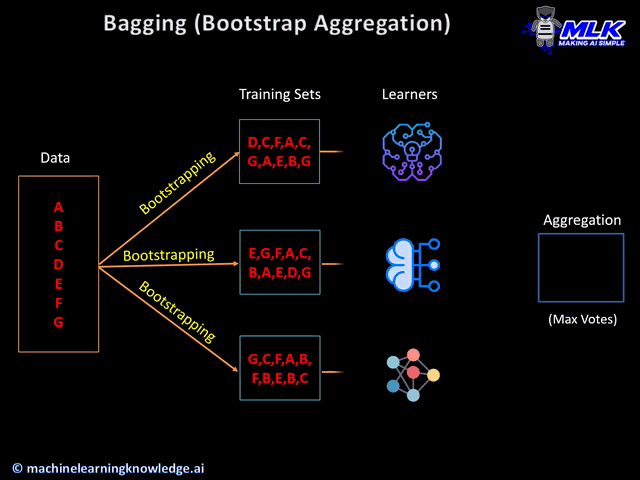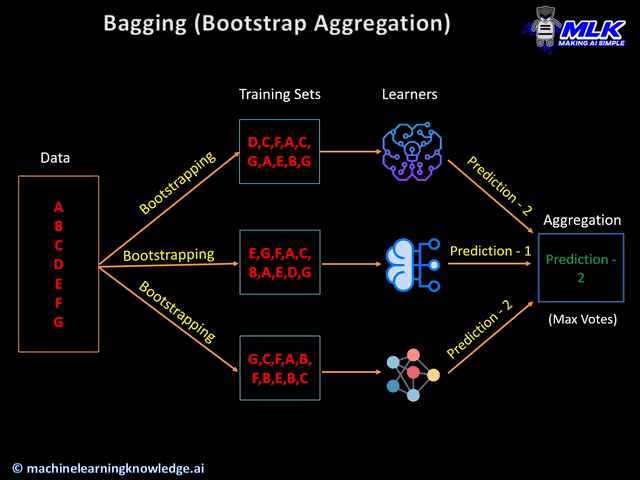
The different learners train on these various training sets that are obtained by bootstrapping method. The hypothesis of these individually trained learners are then aggregated to form a single consensus output.
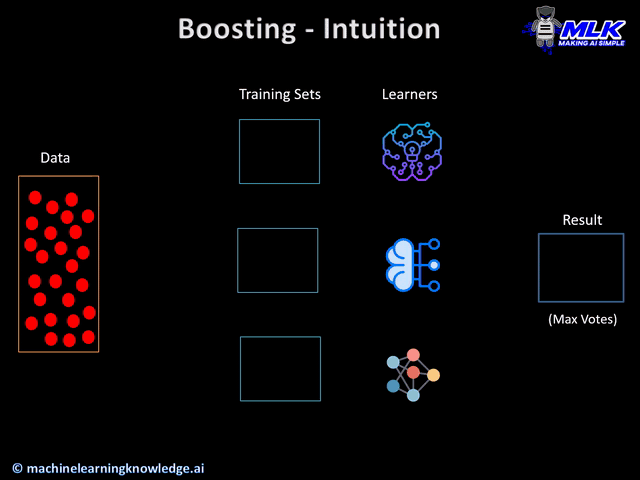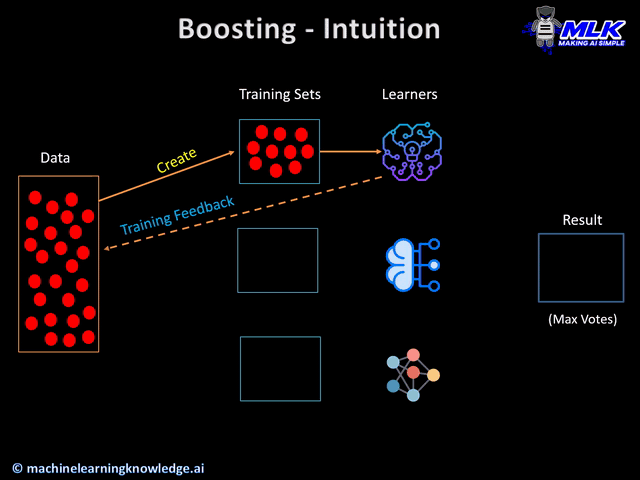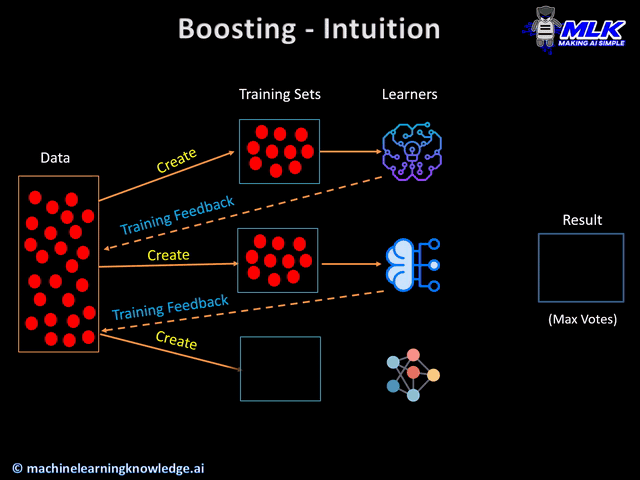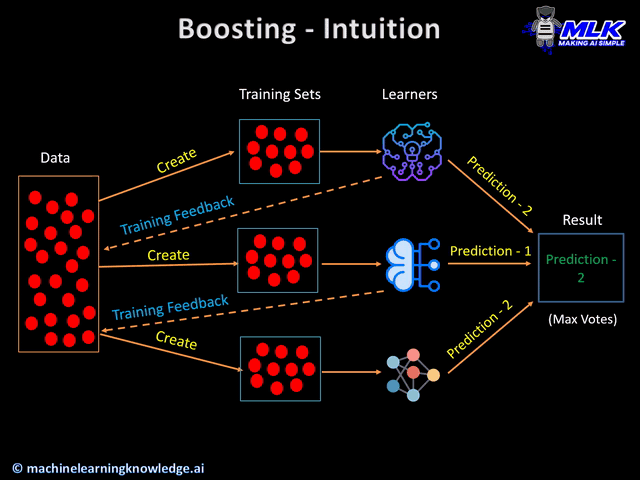
- In the case of classification, the aggregation takes place by considering the maximum vote by the different learners. This means, that if 3 base learners classify as class A and the remaining 2 learners classify as class B, then the prediction will be considered as class A, based on the maximum vote it got.
- In case of regression, the aggregation takes place by taking average of the results. This means, that if the 5 base learners produce following results – 21.23, 20.67, 21.66, 21.01, 20.82 then the actual result will be 21.07
In the Bagging method, the learners are trained independently of each other on their respective training sets. This is why it is also known as Parallel Ensemble Learning.
Bagging helps to reduce variance and hence avoids the possibility of overfitting.
2.Boosting
Boosting is another popular ensemble learning method in which different learners are trained in an iterative manner one after another to finally create a strong learner.
One key characteristic of boosting is that when the learners are trained sequentially, each learner tries to work more on the weak predictions of the previous learner. At the intuition level, you can think that after the training of each learner, a feedback is generated which is used by the next learner to improve on the previous learner.
Once all learners are trained, boosting also relies on the voting of learners to get the combined prediction.
When it comes to better bias, boosting usually performs better than bagging.
There are 3 popular variants of Boosting. Lets us have a look at that –
Ada Boost
- In Ada Boost, in the beginning, each data is assigned an equal weight so that each has an equal probability of being selected in the training data set.
- After the first learner is trained, the weight of data is increased whose prediction was done wrongly by the first learner.
- When the next learner is trained, the data with higher weights are included in the training set. This ensures that the next learner can learn about the data which the previous learner failed to do.
- The process of steps 1 and 3 keeps on getting repeated until we have all data properly predicted by the learners in the training phase.
Gradient Boosting
In Gradient Boosting, each learner tries to reduce the loss of the previous learner by optimizing the loss function.
- Initially, the first learner is trained and the loss is calculated.
- Now, the next learner is added which focuses on reducing the loss obtained from the previous learner
- The process in step 2 is repeated, till the loss function is properly optimized and data is fitted properly.
XGBoost
Gradient boosting technique is computationally slow. XGBoost is variant of gradient boosting which focuses on performance and fast computation.
XGBoost actually stands for Extreme Gradient Boosting and relies on parallel and distributed computing to achieve fast much greater performance and results.
XGBoost is the most widely used model by the winner of competitions and data scientists.
In The End…
I hope this post gave you a good introductory overview of Ensemble Learning. The algorithms of Boosting deserve their own detailed posts and we will cover them in future.
Meanwhile, if you might like to understand some more machine learning basic concepts, do check out our below posts –
- Also Read – Deep Learning vs Machine Learning – No More Confusion !!
- Also Read- Supervised vs Unsupervised Learning – No More Confusion !!
- Also Read- Semi Supervised Learning – A Gentle Introduction for Beginners
Animation Element Source-
- Icons made by Vitaly Gorbachev from www.flaticon.com
- Icons made by Becris from www.flaticon.com
- Icons made by Eucalyp from www.flaticon.com


