
Introduction
In this tutorial, we will be seeing two encoding methods of Sklearn – LabelEncoder and OnehotEcoder, to encode categorical variables to numeric variables. We will first understand what is categorical data and why it requires encoding for machine learning. We will then understand and compare the techniques of Label Encoding and One Hot Encoding and finally see their example in Sklearn.
What is Categorical Data
Categorical data is the kind of data that describes the characteristics of an entity. The common examples and values of categorical data are –
- Gender: Male, Female, Others
- Education qualification: High school, Undergraduate, Master’s or PhD
- City: Mumbai, Delhi, Bangalore or Chennai, and so on.
Usually, categorical data are non-numeric in nature and are text. It is, however, possible that categorical data is denoted by numbers e.g. Colors can be denoted by numbers like Red = 1, Orange = 2, Blue = 3, and so on but it does not have any mathematical significance.
Why Categorical Data Encoding Needed in ML
Most machine learning algorithms like Regression, Support Vector Machines, Neural Networks, KNN, etc. cannot work with text-based categorical data. So it becomes necessary to convert the categorical data into some sort of numerical encoding as part of data preprocessing and then feed it to the ML algorithms.
It should be noted however that tree-based machine learning algorithms like Decision Trees and Random Forest can work on categorical data and you may not be required to do categorical data encoding.
We next take a look at the two most common techniques of categorical data encoding – i) Label Encoding and ii) One Hot Encoding.
Label Encoding
In label encoding, each distinct value of the feature is assigned numeric values starting from 0 to N-1 where N is the total number of distinct values.
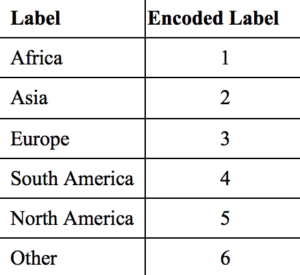
E.g. if we have continents of the world such as [‘Africa’, ‘Asia’, ‘Europe’, ‘South America’, ‘North America’, ‘Others’], after using Label Encoder these categorical values will be encoded as [0,1,2,3,4,5].
One Hot Encoding
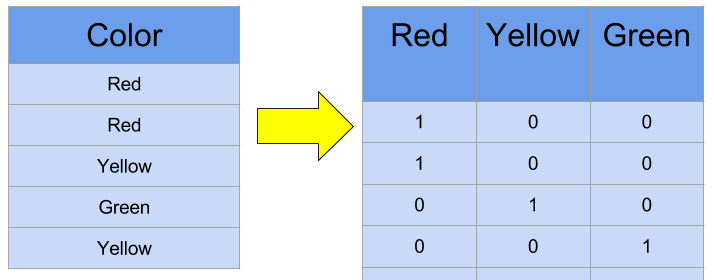
In this technique, first of all, for each distinct value of the feature, new columns are created. Then in these new columns, the presence of that value in the row is denoted by 1, and the absence is denoted by 0.
In the below example, the feature Color has three values Red, Yellow, and Green. As we can see three columns are created corresponding to each of these values. Finally, the presence and absence of the value in each row is denoted by 1 and 0 respectively.
Label Encoding vs One Hot Encoding
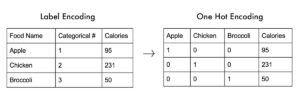
Label encoding may look intuitive to us humans but machine learning algorithms can misinterpret it by assuming they have an ordinal ranking. In the below example, Apple has an encoding of 1 and Brocolli has encoding 3. But it does not mean Brocolli is higher than Apple however it does misleads the ML algorithm. This is why Label Encoding is not very much used for categorical encoding for machine learning.
One Hot Encoding is much suited to overcome the shortcoming of Label Encoding and is commonly used with machine learning algorithms. However, it also has some disadvantages. When the cardinality of the categorical variable is high i.e. there are too many distinct values of the categorical column it may produce a very big encoding with a high number of additional columns that may not even fit the memory or produce not so great results
Example of LabelEncoder in Sklearn
We will now see how to do categorical encoding using Sklearn for Label Encoder. We will see an end-to-end example by using a dataset and create an ML model by applying label encoding.
About the Dataset
This is a small dataset about startups that consists of 51 rows and 5 columns. The objective is to predict the Profit based on the other four independent variables of the dataset. Since one of our variables here, ‘State’ is a categorical variable, we will first be encoding it to the numeric variable by using Sklearn LabelEncoder and OneHotEncoder.
Importing Libraries and Read Dataset
We first import all the necessary libraries for our example. And next, we read the dataset in the CSV file into the Pandas dataframe.
#importing the necassary libraries
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
#reading the dataset
df=pd.read_csv(r"C:\Users\Veer Kumar\Downloads\MLK internship\Encoder\50_Startups.csv")
df.head(10)
| R&D Spend | Administration | Marketing Spend | State | Profit | |
|---|---|---|---|---|---|
| 0 | 165349.20 | 136897.80 | 471784.10 | New York | 192261.83 |
| 1 | 162597.70 | 151377.59 | 443898.53 | California | 191792.06 |
| 2 | 153441.51 | 101145.55 | 407934.54 | Florida | 191050.39 |
| 3 | 144372.41 | 118671.85 | 383199.62 | New York | 182901.99 |
| 4 | 142107.34 | 91391.77 | 366168.42 | Florida | 166187.94 |
| 5 | 131876.90 | 99814.71 | 362861.36 | New York | 156991.12 |
| 6 | 134615.46 | 147198.87 | 127716.82 | California | 156122.51 |
| 7 | 130298.13 | 145530.06 | 323876.68 | Florida | 155752.60 |
| 8 | 120542.52 | 148718.95 | 311613.29 | New York | 152211.77 |
| 9 | 123334.88 | 108679.17 | 304981.62 | California | 149759.96 |
df.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 50 entries, 0 to 49 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 R&D Spend 50 non-null float64 1 Administration 50 non-null float64 2 Marketing Spend 50 non-null float64 3 State 50 non-null object 4 Profit 50 non-null float64 dtypes: float64(4), object(1) memory usage: 1.8+ KB
Apply Sklearn Label Encoding
The Sklearn Preprocessing has the module LabelEncoder() that can be used for doing label encoding. Here we first create an instance of LabelEncoder() and then apply fit_transform by passing the state column of the dataframe.
In the output, we can see that the values in the state are encoded with 0,1, and 2.
# label_encoder object
label_encoder =LabelEncoder()
# Encode labels in column.
df['State']= label_encoder.fit_transform(df['State'])
df.head(10)
| R&D Spend | Administration | Marketing Spend | State | Profit | |
|---|---|---|---|---|---|
| 0 | 165349.20 | 136897.80 | 471784.10 | 2 | 192261.83 |
| 1 | 162597.70 | 151377.59 | 443898.53 | 0 | 191792.06 |
| 2 | 153441.51 | 101145.55 | 407934.54 | 1 | 191050.39 |
| 3 | 144372.41 | 118671.85 | 383199.62 | 2 | 182901.99 |
| 4 | 142107.34 | 91391.77 | 366168.42 | 1 | 166187.94 |
| 5 | 131876.90 | 99814.71 | 362861.36 | 2 | 156991.12 |
| 6 | 134615.46 | 147198.87 | 127716.82 | 0 | 156122.51 |
| 7 | 130298.13 | 145530.06 | 323876.68 | 1 | 155752.60 |
| 8 | 120542.52 | 148718.95 | 311613.29 | 2 | 152211.77 |
| 9 | 123334.88 | 108679.17 | 304981.62 | 0 | 149759.96 |
Train Test Split
Here, we will separate the feature and target variables by splitting the dataset into training and testing sets
X=df.iloc[:,[0,1,3]]
y=df.iloc[:,[2]]
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.10,random_state=42)
Create and Train Model
We now create an object of Sklearn Linear regression and train the model by passing the dataset.
from sklearn.linear_model import LinearRegression
model=LinearRegression()
model.fit(X_train,y_train)
LinearRegression()
Finding Model Accuracy
Model accuracy on the test data will tell us about how well our model is generalized on the training data, based on predicting values for unseen data.
from sklearn.metrics import r2_score
y_pred=model.predict(X_test)
score=r2_score(y_test,y_pred)
print("Accuracy for our testing dataset using LabelEncoder is : {:.3f}%".format(score*100) )
Accuracy for our testing dataset using LabelEncoder is : 66.826%
Example of OneHotEncoder in Sklearn
We will now see how to do categorical encoding using Sklearn for One Hot Encoding. We will use the same dataset that was used in the above example hence the similar sections at the start are skipped and we straight jump to the encoding part below
One Hot Encoding in Sklearn
The Sklearn Preprocessing has the module OneHotEncoder() that can be used for doing one hot encoding.
We first create an instance of OneHotEncoder() and then apply fit_transform by passing the state column. This returns a new dataframe with multiple columns categorical values. This is stored in an intermediate dataframe which is finally joined with the original dataframe.
The drop=’first’ parameter is used to help us overcome the multicollinearity that may arise due to the dummy variables of one hot encoding. This is also known dummy variable trap. Rest assured by dropping the column there will be no loss of the information.
# creating instance of one-hot-encoder
enc = OneHotEncoder(drop='first')
enc_df = pd.DataFrame(enc.fit_transform(data[['State']]).toarray())
# merge with main df bridge_df on key values
df =df.join(enc_df)
df.head()
| R&D Spend | Administration | Marketing Spend | State | Profit | 0 | 1 | |
|---|---|---|---|---|---|---|---|
| 0 | 165349.20 | 136897.80 | 471784.10 | 2 | 192261.83 | 0.0 | 1.0 |
| 1 | 162597.70 | 151377.59 | 443898.53 | 0 | 191792.06 | 0.0 | 0.0 |
| 2 | 153441.51 | 101145.55 | 407934.54 | 1 | 191050.39 | 1.0 | 0.0 |
| 3 | 144372.41 | 118671.85 | 383199.62 | 2 | 182901.99 | 0.0 | 1.0 |
| 4 | 142107.34 | 91391.77 | 366168.42 | 1 | 166187.94 | 1.0 | 0.0 |
Train Test Split
Here, we will separate the feature and target variables and do train test split of the data set.
X=df.iloc[:,[0,1,2,5,6]]
y=df.iloc[:,[4]]
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.10,random_state=42)
Create and Train Model
We now create an object of Sklearn Linear regression and train the model by passing the dataset.
model=LinearRegression()
model.fit(X_train,y_train)
LinearRegression()
Finding Model Accuracy
Model accuracy on the test data will tell us about how well our model is generalized on the training data, based on predicting values for unseen data.
y_pred=model.predict(X_test)
score=r2_score(y_test,y_pred)
print("Accuracy for our testing dataset using OneHotEncoder is : {:.3f}%".format(score*100) )
Accuracy for our testing dataset using OneHotEncoder is : 86.748%
Comparison
As we discussed in the label encoding vs one hot encoding section above, we can clearly see the same shortcomings of label encoding in the above examples as well.
With label encoding, the model had a mere accuracy of 66.8% but with one hot encoding, the accuracy of the model shot up by 22% to 86.74%
Conclusion
We hope you liked our tutorial and now understand better how to implement LabelEncoder and OneHotEncoder using Sklearn (Scikit Learn) in Python. Here, we have illustrated end-to-end examples of both by using a dataset to build a Linear Regression model. We also did the comparison of label encoding vs one hot encoding.


4 Responses
The article is great. I have learnt so muchA
We are glad you found the article useful !
Just found a tiny error under OneHotEncoder topic – ” Then in these new columns, the absence of that value in the row is denoted by 1, and absence is denoted by 0.”
I think the first occurrence of the word “absence” should be replaced by “presence”.
Yes, Pujesh.. it was a small typo mistake. Thanks for pointing it out. It is corrected now.