
Introduction
Recurrent Neural Networks (RNN) and Transformers have emerged as two popular deep learning models, especially in the field of Natural Language Processing (NLP). Although research on RNNs goes back to the 1980s the Transformer research paper first came out in 2017 only and its models have become highly successful in recent times. In this post, we will compare Transformers vs RNN and understand their similarities and differences point-wise.
Recurrent Neural Networks (RNN)
Recurrent Neural Networks (RNN) are a type of neural network designed to handle sequential data like text, time series, audio, etc. RNNs were first proposed in 1986 but were mostly confined to theoretical research due to a lack of modern computing powers. It uses a hidden layer to maintain a state (memory) to persist the information of the current time step, which can be used in the next time step. Effectively this allows them to capture temporal dependencies within the sequence of input.
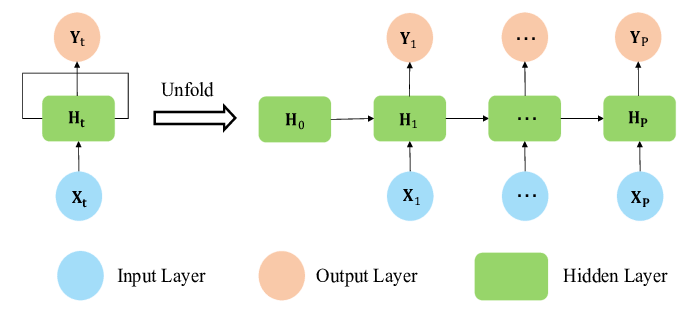
The key features of RNNs are –
- Sequential Processing: RNNs process inputs sequentially by maintaining a hidden state which is updated at each time step.
- Memory: They can remember previous inputs in the sequence, which is important for tasks that require context.
- Vanishing Gradient Problem: Traditional RNNs suffer from the vanishing gradient problem, making it difficult to learn long-range dependencies.
There are many improved variations of simple RNN, the popular ones are –
- Long Short-Term Memory (LSTM)
- Gated Recurrent Unit (GRU)
- Sequence-to-Sequence (Seq2Seq) Models
- Recurrent Convolutional Neural Networks (RCNN)
Transformers
Transformers are a type of neural network that can also process sequential data text, time series, audio, etc. It was first introduced in the 2017 paper “Attention is All You Need,” in which a novel idea was proposed for sequence modeling. They took a different approach from the sequential processing of RNNs and instead relied on a self-attention mechanism. This mechanism allowed the model to attend to all parts of the input sequence simultaneously thus enabling it to capture long-range dependencies more effectively.
- Encoder-Decoder Structure: The original Transformer architecture consists of an encoder that processes the input sequence and a decoder that generates the output sequence.
- Attention Mechanisms: It includes mechanisms like multi-head attention, which enables the model to focus on different parts of the sequence parallelly.
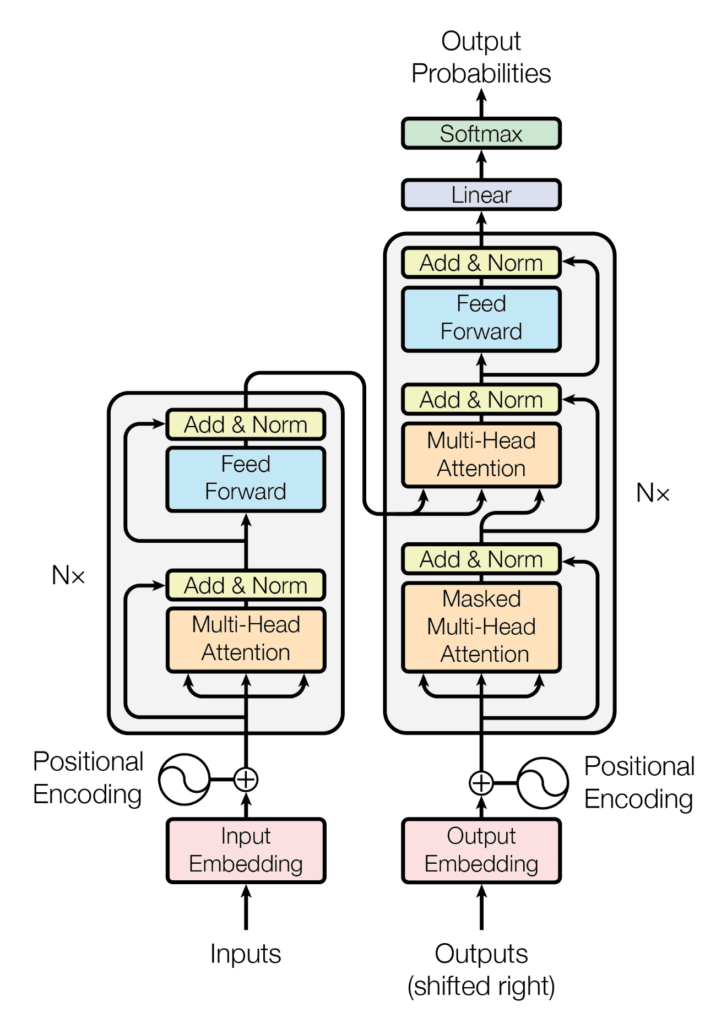
The key features of transformers are –
- Self-Attention: This mechanism allows the model to weigh the importance of different elements in the input sequence, regardless of their position.
- Parallel Processing: Transformers can process the entire input sequence in parallel, which speeds up training and inference time significantly.
- Scalability: It can process very long sequences and large datasets efficiently.
Some of the popular transformer models are –
- BERT
- GPT
- RoBERTa
- DistilBERT
- T5
Transformers vs RNN – Similarities
Neural Network Foundation
The architectures of both RNN and Transformer are based on neural networks and use similar training techniques (e.g., backpropagation, gradient descent).
Sequence Handling
Both RNNs and Transformers are designed to process sequential data and are widely used in NLP tasks.
Applications
Both RNNs and Transformers can be used for tasks such as language modeling, machine translation, text generation, etc.
Transformers vs RNN – Differences
Architecture
- RNNs: They process sequence data element by element by maintaining a hidden state that is passed along the sequence allowing it to capture temporal dependency across time steps.
- Transformers: Unlike RNN, transformers process the entire sequence data parallel by using the self-attention mechanism.
Computation Efficiency
- RNNs: Since RNN does sequential processing the computation time can become very slow, especially for very long sequences of data.
- Transformers: Since Transformers does parallel processing, it allows for faster computation and better utilization of hardware resources.
Handling Long Dependencies
- RNNs: They are known to struggle with long-range dependencies due to the vanishing gradient problem. However, its other variations LSTMs and GRUs mitigate this to some extent.
- Transformers: They can handle long-range dependencies efficiently through self-attention, which can directly connect distant parts of the sequence.
Training Complexity
- RNNs: Generally simpler and less resource-intensive but can be challenging to train on long sequences.
- Transformers: Require more computational resources and memory but benefit from faster training times due to parallel processing.
Model Interpretability
- RNNs: The hidden states maintained by RNNs are less interpretable and harder to visualize.
- Transformers: Self-attention weights provide a more interpretable model since they show how different parts of the sequence influence each other.
Scalability
- RNNs: They are less scalable for very large datasets and long sequences due to their sequential processing nature.
- Transformers: They are highly scalable for processing large-scale data and very long sequences.
Summary
| Feature/Aspect | RNNs | Transformers |
|---|---|---|
| Foundation | Based on neural network fundamentals | Based on neural network fundamentals |
| Sequence Handling | Designed to handle sequence data. | Designed to handle sequence data. |
| Applications | Language modeling, machine translation, text generation, etc. | Language modeling, machine translation, text generation, etc. |
| Architecture | Sequential processing, hidden states | Self-attention, parallel processing |
| Computation Efficiency | Slower due to sequential nature | Faster due to parallel processing |
| Long Dependency Handling | Struggles with long-range dependencies | Effective with long-range dependencies |
| Training Complexity | Simpler but challenging for long sequences | More complex, faster training |
| Model Interpretability | Less interpretable hidden states | More interpretable self-attention weights |
| Scalability | Less scalable for large datasets/sequences | Highly scalable for large datasets/sequences |


