
Introduction
In this tutorial, we will go through different types of PyTorch activation functions to understand their characteristics and use cases. We will understand the advantages and disadvantages of each of them, and finally, see the syntaxes and examples of these PyTorch activation functions. We will cover ReLU, Leaky ReLU, Sigmoid, Tanh, and Softmax activation functions for PyTorch in the article.
But before all that, we will touch upon the general concepts of activation function in neural networks and what are characteristics of a good activation function.
What is an Activation Function?
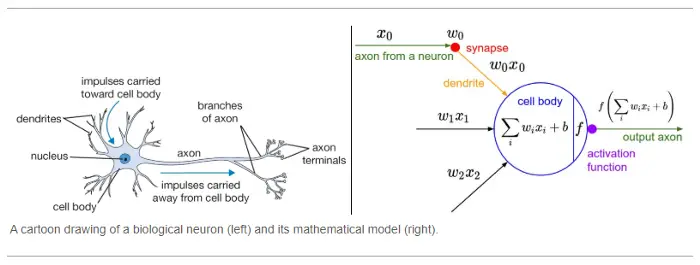
The concept of activation functions in the neural network is inspired by the biological neurons of the human brain. In the biological brain, neurons are fired or activated based on certain inputs from their previous connected neurons. The entire brain is a complex network of these biological neurons that are activated in a complex manner and help the functioning of the entire body.
In the artificial neural network, we have mathematical units known as artificial neurons that are connected with each other. And these neuron units are fired using the activation functions which is nothing but a mathematical function itself.
The below diagram explains this concept and comparison between the biological neuron and artificial neuron.
Characteristics of good Activation Functions in Neural Network
There are many activation functions that can be used in neural networks. Before we take a look at the popular ones in Kera let us understand what is an ideal activation function.
- Non-Linearity – Activation function should be able to add nonlinearity in neural networks especially in the neurons of hidden layers. This is because rarely you will see any real-world scenarios that can be explained with linear relationships.
- Differentiable – The activation function should be differentiable. During the training phase, the neural network learns by back-propagating error from the output layer to hidden layers. The backpropagation algorithm uses the derivative of the activation function of neurons in hidden layers, to adjust their weights so that error in the next training epoch can be reduced.
Read more – Animated Guide to Activation Function in Neural Network
Types of PyTorch Activation Functions
In this section, we will see different types of activation layers available in PyTorch along with examples and their advantages and disadvantages.
i) ReLU Activation Function

The ReLU or Rectified Linear Activation Function is a type of piecewise linear function.
Advantages of ReLU Activation Function
- ReLu activation function is computationally fast hence it enables faster convergence of the training phase of the neural networks.
- It is both non-linear and differentiable which are good characteristics for activation function.
- ReLU does not suffer from the issue of Vanishing Gradient issue like other activation functions. Hence it is a good choice in hidden layers of large neural networks.
Disadvantages of ReLU Activation Function
- The main disadvantage of the ReLU function is that it can cause the problem of Dying Neurons. Whenever the inputs are negative, its derivative becomes zero, therefore backpropagation cannot be performed and learning may not take place for that neuron and it dies out.
ReLU() activation function of PyTorch helps to apply ReLU activations in the neural network.
Syntax of ReLU Activation Function in PyTorch
torch.nn.ReLU(inplace: bool = False)
Parameters
- inplace – For performing operations in-place. The default value is False.
Example of ReLU Activation Function
Now let’s look at an example of how the ReLU Activation Function is implemented in PyTorch. Here PyTorch’s nn package is used to call the ReLU function.
For input purposes, we are using the random function to generate data for our tensor. At last, we obtain the output.
m = nn.ReLU()
input = torch.randn(5)
output = m(input)
print("This is the input:",input)
print("This is the output:",output)
This is the input: tensor([ 1.0720, -1.4033, -0.6637, 1.2851, -0.5382]) This is the output: tensor([1.0720, 0.0000, 0.0000, 1.2851, 0.0000])
ii) Leaky ReLU Activation Function

This second type of activation function is Leaky ReLU which is a variation of ReLU that addresses the issue of dying neurons discussed above.
You can see in the above illustration, that in the negative axis, there is a small tiny bit of extension on the negative side, unlike ReLU. This implies that its derivative would be a very small fraction and never zero. This ensures that the learning of the neuron does not stop during backpropagation and thus avoiding the dying neuron issue.
In PyTorch, the activation function for Leaky ReLU is implemented using LeakyReLU() function.
Syntax of Leaky ReLU in PyTorch
torch.nn.LeakyReLU(negative_slope: float = 0.01, inplace: bool = False)
Parameters
- negative_slope – With the help of this parameter, we control negative slope.
- inplace – If we want to do the operation in-place, then this parameter is used. The default parameter is False.
Example of Leaky ReLU Activation Function
In the below example of the leaky ReLU activation function, we are using the LeakyReLU() function available in nn package of the PyTorch library.
Then with the help of a random function, we generate data that will be used as input values for producing output.
m = nn.LeakyReLU(0.1)
input = torch.randn(18)
output = m(input)
print("This is the input:",input)
print("----------------------------------------------------")
print("This is the output:", output)
This is the input: tensor([ 1.3159, -2.4688, 0.3144, 1.3210, -2.0890, 0.7903, 0.4291, -0.7938,
-0.5030, 0.7853, -0.4555, 1.4221, -1.6509, 1.3590, -0.4521, -0.0615,
-1.8761, 0.7038])
------------------------------------------------------------------------------------------
This is the output: tensor([ 1.3159, -0.2469, 0.3144, 1.3210, -0.2089, 0.7903, 0.4291, -0.0794,
-0.0503, 0.7853, -0.0455, 1.4221, -0.1651, 1.3590, -0.0452, -0.0062,
-0.1876, 0.7038])
iii) Sigmoid Activation Function

The sigmoid activation function produces output in the range of 0 to 1 which is interpreted as the probability.
Advantages of Sigmoid Activation Function
- The sigmoid activation function is both non-linear and differentiable which are good characteristics for activation function.
- As its output ranges between 0 to 1, it can be used in the output layer to produce the result in probability for binary classification.
Disadvantages of Sigmoid Activation Function
- Sigmoid activation is computationally slow and the neural network may not converge fast during training.
- When the input values are too small or too high, it can cause the neural network to stop learning, this issue is known as the vanishing gradient problem. This is why the Sigmoid activation function should not be used in hidden layers.
In PyTorch, the activation function for sigmoid is implemented using LeakyReLU() function.
Syntax of Sigmoid Activation Function in PyTorch
torch.nn.SigmoidExample of Sigmoid Activation Function
A similar process is followed for implementing the sigmoid activation function using the PyTorch library. The random data generated is passed to the Sigmoid() function of PyTorch and output is obtained.
m = nn.Sigmoid()
input = torch.randn(2)
output = m(input)
print("This is the input:",input)
print("This is the output:",output)
This is the input: tensor([ 0.0118, -0.6906]) This is the output: tensor([0.5029, 0.3339])
iv) Tanh Activation Function

Tanh activation function is similar to the Sigmoid function but its output ranges from +1 to -1.
Advantages of Tanh Activation Function
- The Tanh activation function is both non-linear and differentiable which are good characteristics for activation function.
- Since its output ranges from +1 to -1, it can be used to transform the output of a neuron to a negative sign.
Disadvantages
- Since its functioning is similar to a sigmoid function, it also suffers from the issue of Vanishing gradient if there are too low or too high input values.
In PyTorch, the activation function for Tanh is implemented using Tanh() function.
Syntax of Tanh Activation Function in PyTorch
torch.nn.TanhExample of Tanh Activation Function
Once again, the Tanh() activation function is imported with the help of nn package.
Then, random data is generated and passed to obtain the output.
m = nn.Tanh()
input = torch.randn(7)
output = m(input)
print("This is the input:",input)
print("This is the output:",output)
This is the input: tensor([-0.7077, 0.8317, -0.8910, 2.2377, -0.5721, -0.8976, 0.9172]) This is the output: tensor([-0.6093, 0.6814, -0.7119, 0.9775, -0.5169, -0.7151, 0.7246])
v) SoftMax Activation Function

Softmax function produces a probability distribution as a vector whose value range between (0,1) and the sum equals 1.
Advantages of Softmax Activation Function
- Since Softmax produces a probability distribution, it can be used as an output layer for multiclass classification.
In PyTorch, the activation function for Softmax is implemented using Softmax() function.
Syntax of Softmax Activation Function in PyTorch
torch.nn.Softmax(dim: Optional[int] = None)
Shape
- Input: (∗) where * means, Number of Dimensions
- Output: (∗), The output has an identical shape as an input.
Parameters
dim (int) – This is the dimension on which softmax function is applied.
Example – Softmax Activation Function
In the below example, we are using softmax activation function along with dim parameter set as ‘1’. Then, input data is produced to get the output.
m = nn.Softmax(dim=1)
input = torch.randn(4, 5)
output = m(input)
print("This is the input:",input)
print("----------------------------------------------------------")
print("This is the output:",output)
This is the input: tensor([[ 0.4325, -0.0198, -0.3384, 1.0506, 0.6901],
[ 0.9477, -0.3371, -0.7476, 0.7868, 0.6242],
[-0.3339, 2.4288, 0.4182, 0.5997, -1.5545],
[ 0.5749, -0.5843, -1.2282, 2.0387, -0.7899]])
------------------------------------------------------------------------------------------
This is the output: tensor([[0.1905, 0.1212, 0.0881, 0.3535, 0.2465],
[0.3295, 0.0912, 0.0605, 0.2805, 0.2384],
[0.0459, 0.7266, 0.0973, 0.1167, 0.0135],
[0.1651, 0.0518, 0.0272, 0.7137, 0.0422]])
Which Activation Function to use in Neural Network?
- Sigmoid and Tanh activation functions should not be used in hidden layers as they can lead to the Vanishing Gradient problem.
- Sigmoid activation function should be used in the output layer in case of Binary Classification
- ReLU activation functions are ideal for hidden layers of neural networks as they don’t suffer from the Vanishing Gradient problem and help for faster convergence during training.
- Softmax activation function should be used in the output layer for multiclass classification.
- Also Read – PyTorch Tensor – Explained for Beginners
- Also Read – PyTorch Stack vs Cat Explained for Beginners
Conclusion
This tutorial talked about different kinds of activation functions in the PyTorch library. covered syntax of activation functions with examples along with pros and cons of each of them.
Reference – PyTorch Documentation

